この記事の3行要約
- CAG(Context-Aware Generation)とRAG(Retrieval-Augmented Generation)の構成と違いを、図解で丁寧に解説
- 生成AIは“内なる知識”か“外部の情報”か──どこから答えを生むかで構造も戦略も変わってくる
- 本記事では、CAGとRAGの仕組み・事例・使い分けを網羅し、AI活用の地図として機能します
こんにちは、リュウセイです。
ChatGPT活用支援サービスをやっています。
今回は、RAG(Retrieval-Augmented Generation)に代わりうるかもしれない新手法「CAG(Cache-Augmented Generation)」について、論文ベースで解説していこうと思います。
このCAGを提案している論文はDon’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasksというもので、まだまだ数少ない情報しかないため、いろいろと噛み砕いてみる価値があると感じました。
僕は以前、「RAG(取得拡張生成)」と「検索エンジン」の仕組みと違いについての記事も書いていますので、もしRAG自体がよく分からない方はそちらを先に読んでいただけるとスムーズかもしれません。
RAGと検索エンジンの違いを理解すれば、今回紹介するCAGが「どんな背景で提案されたのか」がよりクリアになるはずです。
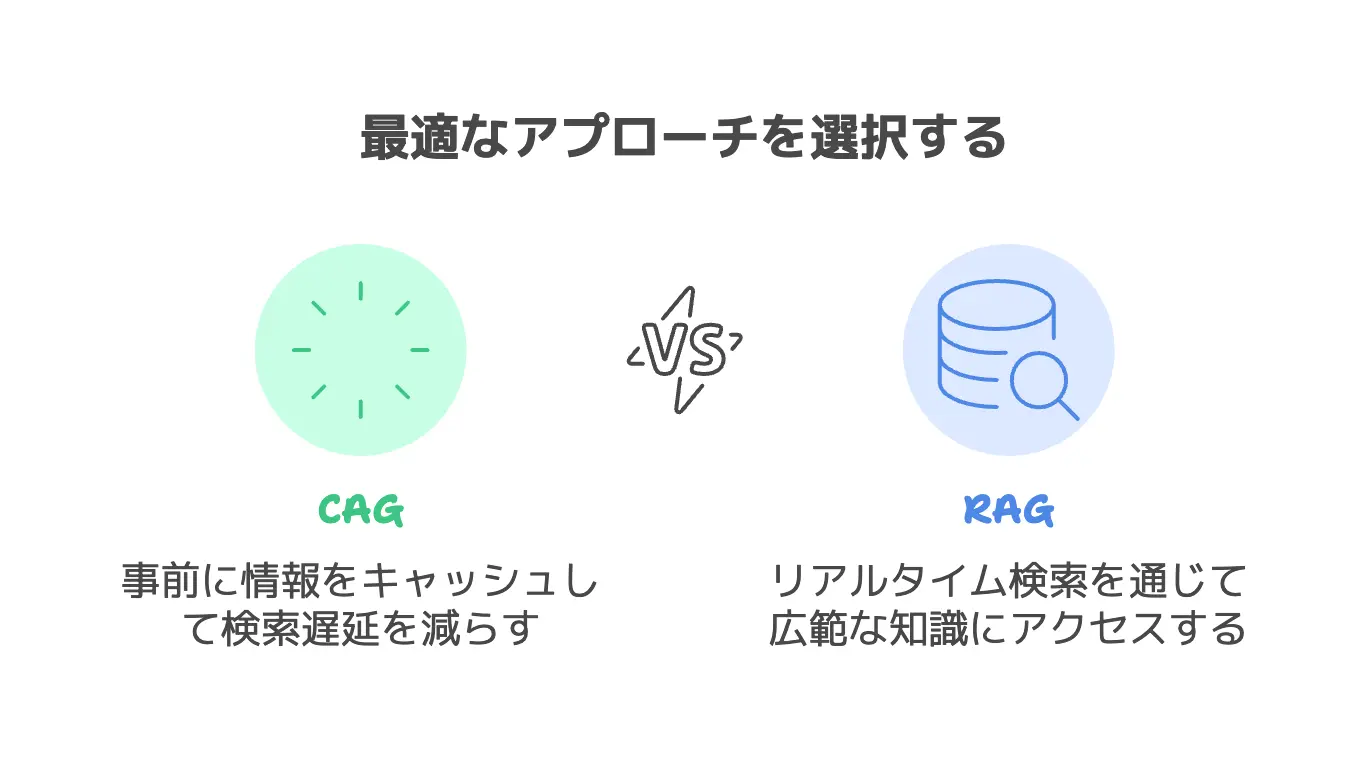
CAGという手法は、簡単に言えば「長文LLMのコンテキストウィンドウを最大活用し、事前に知識をすべて読み込んでしまう」というアプローチです。
リアルタイムの検索を伴うRAG方式とは異なり、CAGでは推論時の検索を必要としません。
「KVキャッシュを先に作っておいて、そこにすべての外部知識を詰め込む」という発想で、検索によるエラーや遅延を減らそうとしているのがCAGの基本的な狙いです。
今回は、論文に書いてある要点をもとにCAGの仕組みやメリット、課題などをまとめていきます。
専門的な要素をできるだけ初心者視点で噛み砕きますので、AIに詳しくないあなたでもなるべく理解しやすくなるよう、頑張って解説していきますね。
当記事は、筆者の下書きとChatGPTを合わせて執筆しています。しっかりファクトチェック済みです。
RAGとは何か?初心者目線でざっくり把握
あなたは「RAG」という言葉を聞いたことがあるでしょうか。
RAG(Retrieval-Augmented Generation)とは、大規模言語モデル(LLM)が回答を生成するときに、外部の知識や文書を「検索」して取り込み、その情報をベースに回答を出す仕組みを指します。
つまり、質問やタスクに応じて「最適だと思われる文書を引っ張ってきてから」回答を作るため、リアルタイムに文書を探すことになります。
RAGが注目されたのは、LLM単体で保持できる知識の限界を補うためでした。
例えば、巨大な知識をすべてモデル内部に詰め込むのは大変ですし、モデルが訓練時点で学習していない新しい情報を参照するときには、どうしても外部の何かを検索しに行く仕組みが必要になります。
RAGはまさにそこをカバーするもので、質問された内容に合わせて「今必要そうな文書」を検索して取得し、生成モデルに与えるわけです。
その点は、すでに多くの企業やシステムでも応用されてきました。
しかしながらRAGには、検索が遅れて回答が遅くなるとか、検索がうまくいかないと誤った文書を参照してしまうといった問題もありました。
僕が過去に書いた「RAG(取得拡張生成)」と「検索エンジン」の仕組みと違いの記事でも触れましたが、結局は検索という工程が「ボトルネック」になりがちなんです。
CAG(Cache-Augmented Generation)は、そうしたRAGの欠点を克服するために誕生したと言われています。
従来の検索とどう違う?RAGを使う背景を理解
RAGが脚光を浴びた最初の背景には、「LLMだけじゃ新しい情報をうまく扱えない」という事情がありました。
LLMは事前学習されたパラメータを使って推論するため、学習時点に含まれていない最新知識は基本的に知らないという制約があります。
また、膨大な量のテキストをすべて内部パラメータに取り込むには限界があり、すでに大量のデータを学習しているのに、さらに新たなテキストを動的に参照するのは苦手だったわけです。
そこで、検索機能を組み合わせて「新たにやってきた質問に対して、まず検索エンジンで候補文書を取り出し、それをもとにLLMが回答を生成する」という方式が登場しました。
RAGはこれに当たります。
要は「検索+生成」のハイブリッドで、一度検索した情報を入力テキストとしてLLMに取り込んで回答を導くわけです。
このとき、従来の検索エンジンとまったく同じ仕組みを使うと、検索エンジンが持つ問題点(検索ヒット率に左右される、検索に時間がかかるなど)もそのままついてきます。
RAGという名称こそ新しいものの、実質的には「AIを使った検索エンジンみたいなシステム」に近いという見方もできます。
昔からある検索技術(BM25など)を使いながらも、モデルの中に取り込む部分を工夫しているわけですね。
ただし、大規模言語モデルが加わることで普通の検索よりも柔軟な回答が期待できるのも事実です。
例えば、単純にキーワードに合致した文章を並べるのではなく、「AとBを総合してCになる」というように「解釈」や「要約」が絡んだ回答を返すことができます。
これがRAGの魅力ですが、反面、うまく噛み合わないと検索で返ってきた誤情報に基づいて答えを作るという困り事も発生します。
実際にRAGがうまく動かず「変な回答になっちゃった……」という事例は多く、検索アルゴリズムの精度やランキングの質に依存する面が強いのです。
こうした「検索アルゴリズムで取りこぼしがある」「検索にかかる時間が無視できない」「誤った文書を拾ったら全部台無しになる」という問題意識があったからこそ、検索そのものを要らなくする方法が熱望され始めたのです。
具体的にどんな仕組み?RAGの内部で起きていること
RAGをもうちょっと内部まで覗いてみると、以下のようなプロセスが典型的です。
- ユーザーのクエリ(質問)が来る
例えば「昨日リリースされた新スマホのスペックは?」という質問をもらう。 - 検索エンジンが動き、関連度が高そうな文書をいくつか返す
従来のBM25などを活用する場合、単純にキーワードマッチを使うことが多いです。
あるいは近年はWord Embedding(埋め込みベクトル)を使ったデンス検索が一般的になりつつありますが、やることは同じで「関連度が高い文書候補を提示する」。 - 抽出した文書をLLMが受け取る
ここで、複数の文書がまとめてLLMに渡されるケースが多いです。
どこまでをコンテキストに入れるかはシステム設計次第ですが、要はLLMが「回答のために使う文書」を外部から補強してもらう形になります。 - LLMが回答を生成
上記文書を踏まえて最終的に回答を作ります。
「○○という記事に書かれているからこうだよ」「その記事を総合するとこう言えそうだよ」というふうに、モデル自身が推論して文章を組み立てます。
RAGの面白いところは、「どんな検索アルゴリズムを使うか?」や「どれだけ多くの文書をLLMに渡すか?」といった設計に自由度がある点でしょう。
それゆえ実装の仕方も様々ですし、「検索エンジンそのものを何で構築する?」という話になれば企業によって全然違うかもしれません。
また、RAGは「多くの文書を渡した方が正答率は上がるかもしれないけど、LLMのコンテキストウィンドウを圧迫する」というジレンマも抱えています。
あまりに多くの文書を無秩序に突っ込めば、重要な部分が目立たなくなったり、モデルが途中で混乱してしまうリスクがあります。
さらに、数が多ければ多いほど検索も時間がかかりますから、リアルタイム性が損なわれる可能性もあるんですね。
一方で、「じゃあ検索しないと新しい情報に対応できないし……」というのも事実です。
こうして見ると、RAGは一種の両刃の剣と言えます。
そこを「初めから必要な文書すべてを読み込んでおいて、検索自体をやめてしまおう」と大胆に考えたのがCAGです。
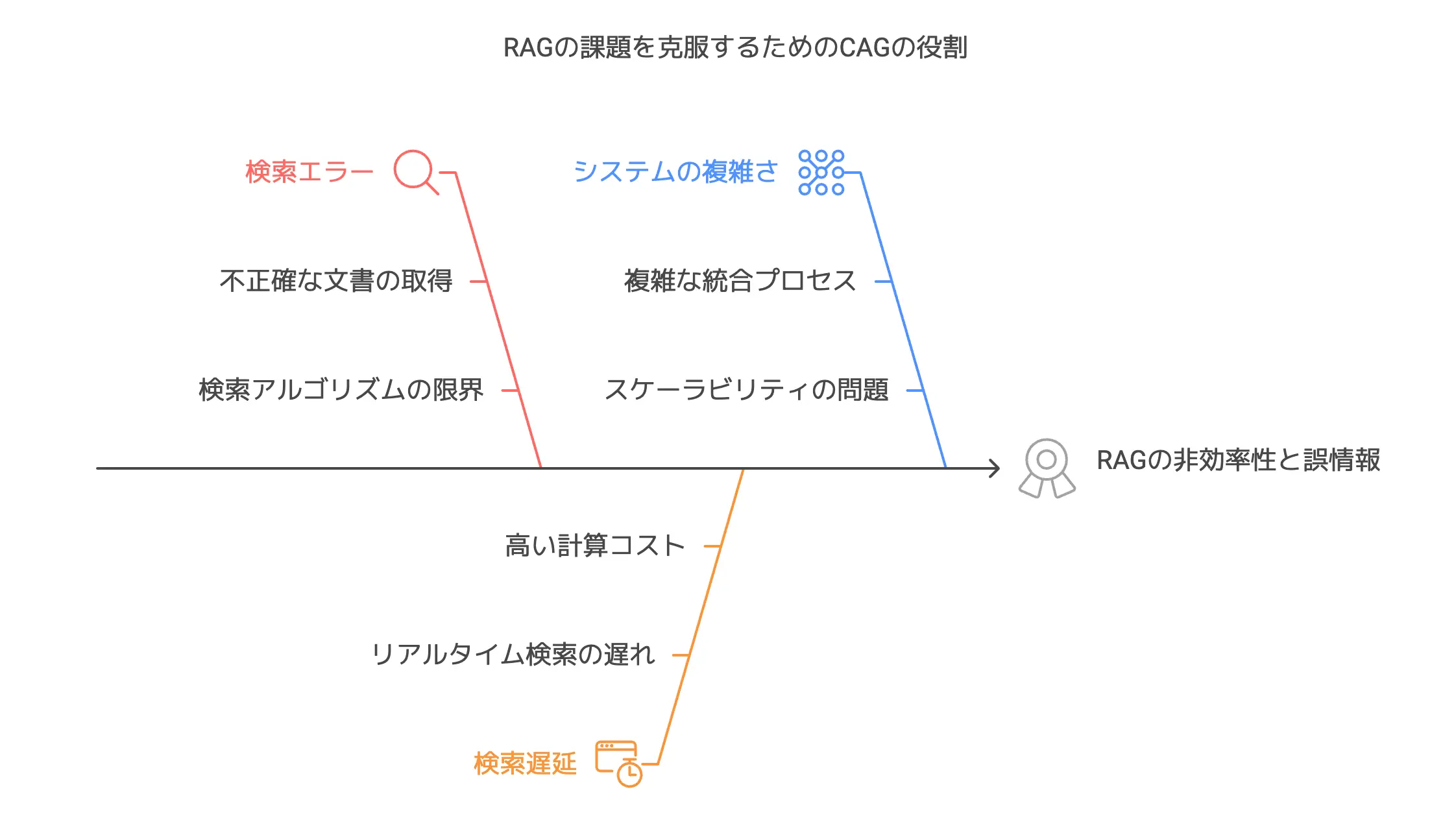
なぜ問題が起こる?検索エラーや遅延の原因を探る
では、RAGに内在する問題をより具体的に見てみましょう。
大きく分けて、検索エラーと検索遅延、そしてシステムの複雑化が三大問題とされています。
- 検索エラーのリスク
検索アルゴリズムで文書を取り込む際、必ずしも正確に「今の質問に完全一致する文書」を拾えるとは限りません。
キーワードマッチングの場合は、質問文に書かれている単語を含む文書しかピックアップできず、ニュアンスが違うけれど実は重要な文書を拾えない可能性もあります。
逆に、単語は一致しているけど文脈的には関係ないものが混じることも多いです。
デンス検索(RAGの基盤技術)を使ったとしても、埋め込みモデルの精度次第では似てるけど違うトピックを拾ったりします。
そうなると、LLMは外部文書が正しいと思い込んで回答を作るため、誤情報が回答に含まれる確率が高まります。
これを「ガベージイン・ガベージアウト(入力データの品質が低ければ、出力結果の品質も低くなる原則)」なんて呼ぶ人もいますが、とにかく検索段階でミスがあると回答がガラッと崩れちゃうわけですね。 - 検索遅延
RAGでは、質問を受けてから検索を行うので、どうしてもリアルタイムでネットワークアクセスやデータベース問い合わせが走ります。
すると、膨大な量の文書を検索しなければならないケースでは、回答時間が遅くなる。
ユーザーがぱっと回答を求めているときには、こうした遅延はストレスになるかもしれません。
特にビジネス活用の現場で、リアルタイムに近いレスポンスを期待される状況だと、1秒でも速さが欲しいものです。 - システムの複雑化
検索エンジン部分と生成モデル部分を統合することになるので、メンテナンスコストが上がるのもRAGのデメリットです。
検索エンジンのインデックス更新や、ランキングアルゴリズムのチューニング、さらに生成モデルとの連携部分をちゃんと管理しなければなりません。
たとえば新しい文書が追加されたらそれを検索エンジンに取り込む必要があるし、常にシステムを適切に回すためにエンジニアリングリソースを割かなければならない。
こうした3つの大きな課題が組み合わさると、「もっと楽に高品質な回答生成をやる方法は無いのか……」と考える気持ちが自然に出てきます。
CAGはそこに一石を投じたアプローチで、「検索しない」「KVキャッシュを先に作る」という斬新さが注目されています。
CAG(Cache-Augmented Generation)の基礎
ここからは、本題であるCAG(Cache-Augmented Generation)の基本的な考え方について話を進めます。
CAGとは、膨大な知識や文書を「事前にLLMへ読み込んでおき、それをまとめてキャッシュ化する」という発想に基づいており、推論時には検索を通さずにそのキャッシュから必要な部分を取り出して回答を作る方式です。
要は「もう検索しなくていいじゃん、最初から必要なデータ全部ぶち込んでおこう」という感じのアプローチで、RAGが苦手としていた遅延や検索ミスを大きく緩和しようとしています。
論文Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasksでは、CAGの仕組みと実験結果について詳しく述べられています。
長文LLMの能力が高まった今だからこそ、CAGは注目され始めました。
RAGと比較して、いったい何がどう違うのか、そしてどんなメリットやデメリットがあるのかを、これから解き明かしていきます。
RAGとの違いをやさしく比較してみよう
RAGとCAGの違いを一言でまとめると、「リアルタイム検索をするか、しないか」の差が一番大きいポイントです。
RAGは「質問が来るたびに必要な情報を検索する」のに対し、CAGは「先に必要そうな情報を全部読み込んでキャッシュを作り、それを利用する」わけですね。
こう聞くと「検索しないなんて大丈夫なの?」と思う方もいるでしょう。
もちろん、CAGが万能というわけではありません。
実はCAGには、「そもそも読み込める文書量に限りがある」という大前提が存在します。
今のLLMが持つコンテキストウィンドウの大きさにも限度がありますから、一度に読み込める情報の量は無制限ではないのです。
一方で、もし対象とする文書がそこまで膨大でない場合や、絞り込み済みの知識ベースが比較的小規模の場合など、文書をまるごとキャッシュしても問題ないケースは意外と多いです。
たとえば自社内のFAQドキュメントだけとか、ある特定の分野の文書だけに限定しているとか。
そのような管理がしやすい範囲であれば、検索というプロセスを完全に省き、代わりに事前に一気に読み込んでしまう方が話が早いというわけですね。
検索エラーが起こらないし、回答も高速になるし、システム構成もスリムになる。
RAGでやろうとすると検索まわりのメンテナンスが大変なので、CAGの登場は「大規模知識を持たないけれど、限られた範囲で確実に高精度な回答がしたい」人にピッタリとも言えます。
また、RAGが使う検索システムは複雑ですが、CAGは「一回だけ読み込んでKVキャッシュを生成」するのが仕組みのベースになります。
ここが大きな違いです。
モデルが文書を読み込んで内部状態をキャッシュに保存し、以降のクエリではそのキャッシュを呼び出すだけ。
この単純さがCAGの強みとも言えます。
しかし、RAGは「ほぼ無限に広がる知識ベースをリアルタイムに検索する」という夢を実現しやすい側面も持っているので、どちらが絶対に良いかはケースバイケースでしょう。
CAGはあくまで「管理可能な範囲の知識なら、まとめて載せてしまった方がメリット大きい」というアプローチだからです。
KVキャッシュって何?長文LLMと事前読み込みの効果
CAG手法で重要なのが「KVキャッシュ(Key-Value Cache)」という概念です。
長文LLMが大量のトークンを処理するとき、中間的に保持する「メモリ」や「内部状態」のようなものがあり、そのキーとバリューのペアをキャッシュ化して保存する仕組みがKVキャッシュと呼ばれます。
そもそもキャッシュとは:データへのアクセスを高速化するために、一時的にデータを保存する仕組み。
これを具体的に言うと、LLMが「文書の内容を解析してトークン同士の関係を学習した結果」や「文章構造を理解した結果」を一種のキャッシュとして持っておくイメージです。
普通の推論では入力テキストを都度解析して答えを出すところ、CAGでは事前に大量の文書を解析し、その結果を一回キャッシュしてしまいます。
そうすると、推論時はクエリと一緒にこのキャッシュを読み込みさえすれば「既に解析済みの文書たち」をすぐ参照できるわけです。
この仕組みにより、リアルタイム検索がなくなる代わりに「事前読み込み」タイミングだけ処理を頑張るという分業が生まれます。
事前にKVキャッシュを生成しておくのは確かに手間ですが、一度キャッシュさえ作ってしまえば、その後のクエリは非常に高速に処理できる。
これは、「長文LLMが沢山のトークンを処理できるからこそ可能になった技術」とも言えます。
昔のLLMはコンテキストウィンドウがすごく狭く、ちょっと長い文章を入れるだけで上限オーバーしてしまいました。
しかし、近年のモデルは数万トークン以上のコンテキストを扱えるようになりつつあり、今後さらに増えていくとされています。
そうなると「この程度の文書なら、まるごとLLMに食わせちゃえる」という状況が増えてきます。
CAGはこれを前提に組み立てられた発想であり、長文LLMの進化がなければ成立しないアプローチだったとも言えますね。
さらに、KVキャッシュは推論のたびに再構築する必要がなく、一度作ったキャッシュを再利用できる点が画期的です。
これにより、RAGみたいにその都度検索して文書を引っ張る工程が不要になり、検索にかかるコストがほぼゼロになるのです。
検索時の遅延がほぼないのは大きいメリットですよね。
CAGが提案された理由と狙いを初心者視点で理解
CAGが提案された理由は、ここまで書いてきたRAGの問題点を真正面から解決しようとしたからです。
「検索が遅い」「エラーが混ざる」「システム構成がややこしい」などの不満があるなら、検索ステップを無くしてしまえば全部解決するんじゃない?という単純明快なアイデアが根底にあります。
しかし、当然ながら「どれだけの文書を事前に読み込めるか」がボトルネックになるわけです。
論文を読んでみると、CAGは主に「管理しやすいサイズの知識ベース」を扱う場合に特に向いているとして紹介されています。
たとえば企業内文書や製品マニュアル、研究の特定分野の論文セットなど、ある程度テーマが絞られている場合ですね。
CAGが狙いとしているのは「特定領域の知識を完全に押さえ込んでしまい、高速かつ間違いの少ない回答を提供する」こと。
RAGだとどうしても「検索ステップによる遅延」や「検索結果が信用できない」というリスクが拭えませんが、CAGは「先に全部読み込んだから、その後に必要なデータはもう揃っているよ」というスタンスなんです。
また、「最初にKVキャッシュを作る段階では時間がかかるかもしれないけれど、使い回しがきく」というのも大きい。
RAGはクエリ単位で検索を行うため、たとえ同じクエリが何度来ても同じように検索コストが発生します。
CAGならキャッシュを再ロードするだけなので、二度目以降はほぼ遅延ゼロに近いパフォーマンスを発揮します。
初心者視点で見ると、「なんだ、検索いらないんだ。なら設定が簡単そう!」と感じるかもしれませんが、もちろんキャッシュ生成時の作業は必要です。
そのための手順やメモリの確保など、技術的な部分は論文でも触れられていますが、少なくとも検索エンジンをどう組むか考えなくていいという利点は大きいですね。
総合的に見ると、CAGはRAGを否定するわけではなく、RAGの欠点をカバーできる分野で特に有効という立ち位置でしょう。
ちなみに論文タイトルが「Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks」なので、「RAGなんてやめろ! これからはCAGだ!」と言わんばかりの攻めたタイトルですよね。
ただ、その真意としては「必要のない検索を回すくらいならキャッシュ作った方が良い場面がたくさんあるよ」という話に近いんだろうと僕は理解しています。
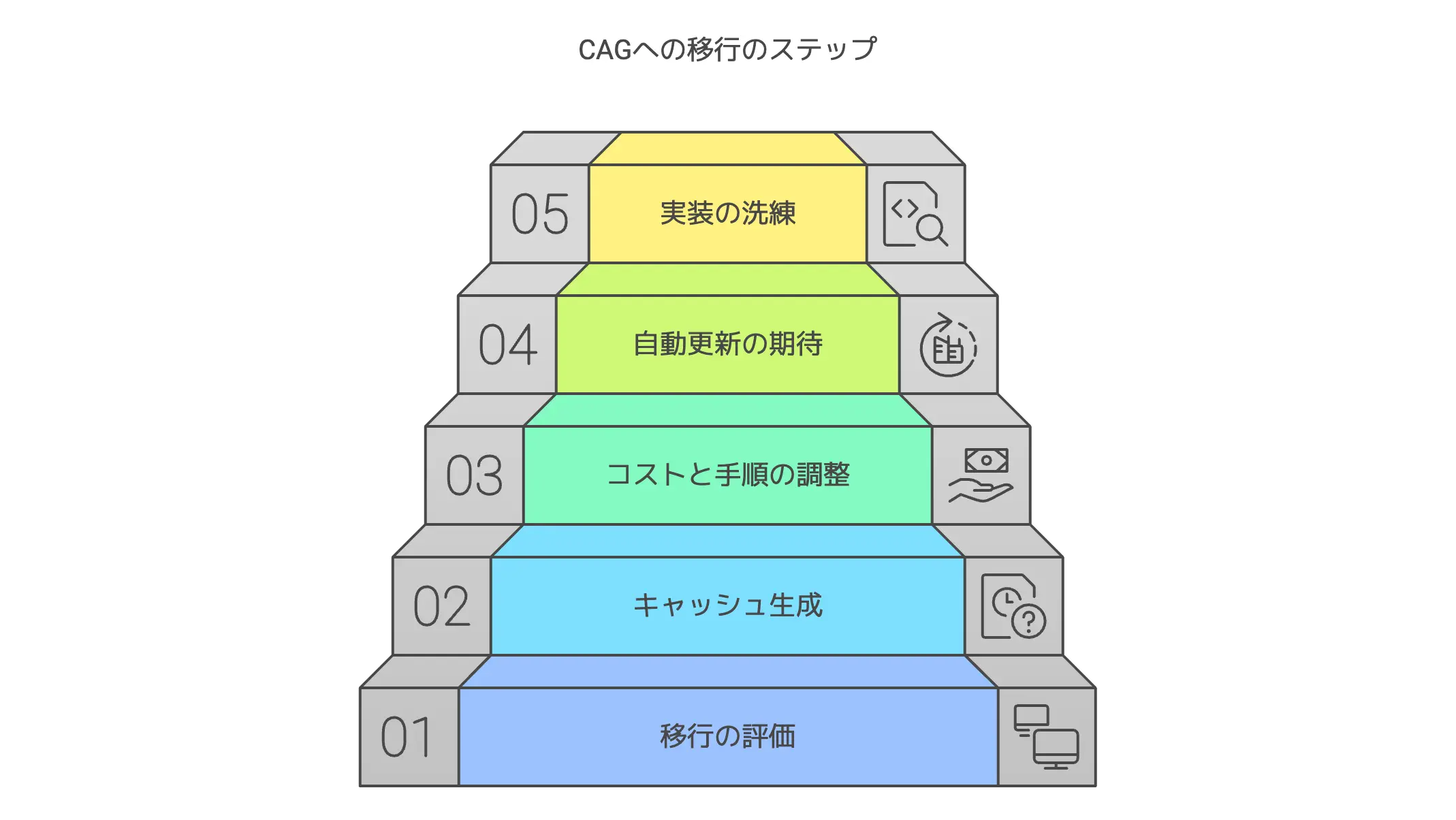
CAGはこう動く!3ステップの流れを学ぶ
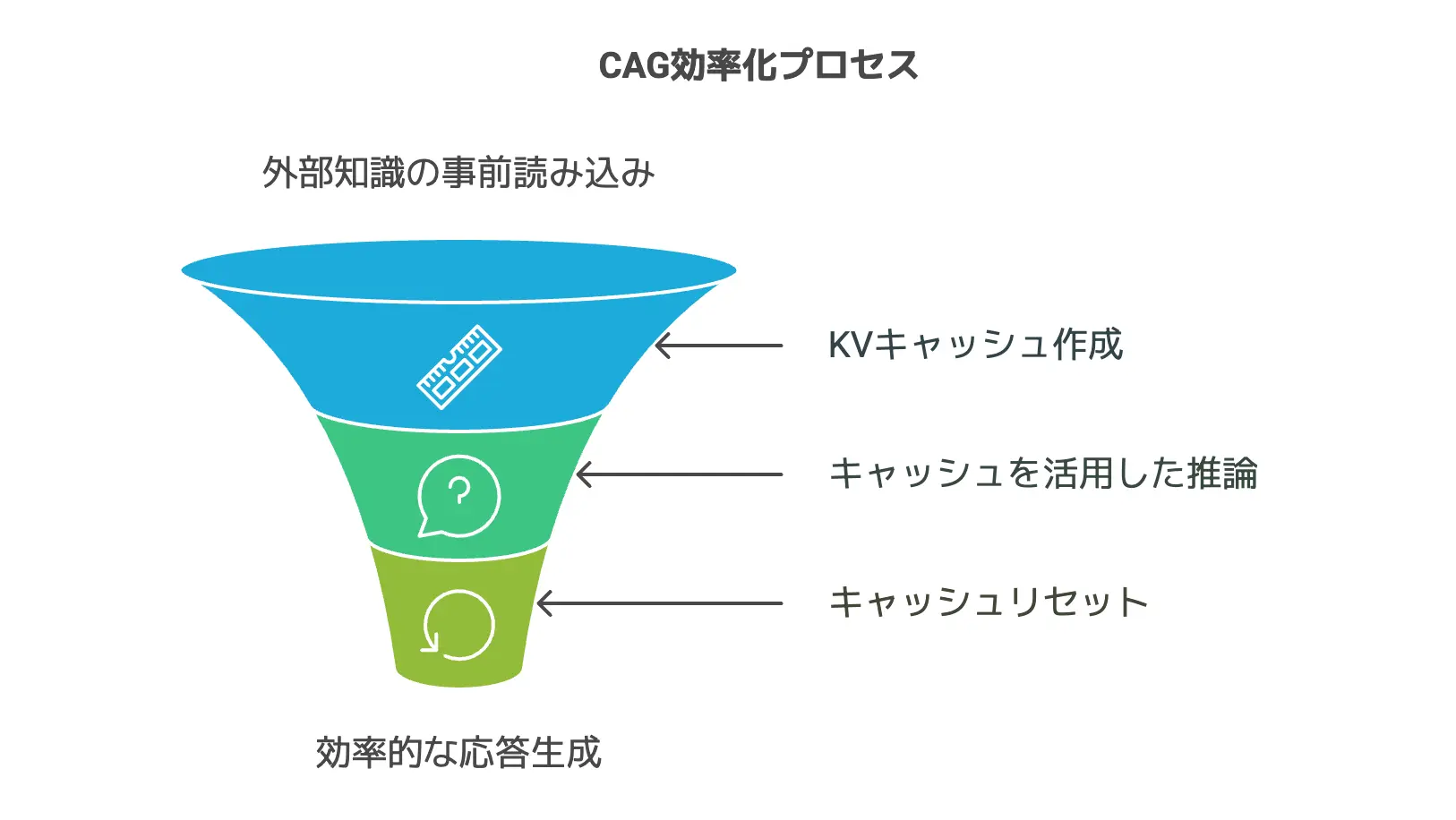
では実際にCAGがどんな動きをするのか、3ステップで確認しましょう。
CAGはシンプルに言うと「外部知識をまとめて読み込み(KVキャッシュ化)→ 推論時にキャッシュを活用 → 必要に応じてリセット」という流れです。
リアルタイム検索がないぶん、スタート地点での読み込み処理が肝になります。
ここでは具体的な作業イメージも交えつつ、CAGが「どうやって知識を準備し、どう回答を作り出すのか」を追いかけていきます。
RAGのように、クエリごとに知識を持ってくるわけではなく、一度に全部やってしまう点を頭に置いておくと分かりやすいですよ。
ステップ1:外部知識の事前読み込みで準備万端
CAGの最初のステップは「関連文書の事前読み込み」です。
ここで言う「関連文書」というのは、あなたが扱いたい分野やテーマに合致するすべてのテキストを指します。
例えば、自社製品のFAQやマニュアル、研究論文、ニュース記事など、とにかく「今後のクエリ回答で使われそうな知識」を一通りまとめるわけです。
この段階では、LLMのコンテキストウィンドウに収まる範囲で文書を整理し、必要に応じて分割や要約などの前処理をすることが重要になります。
「ひたすら何百MBも突っ込む」みたいな強引なやり方は、現実的にコンテキストウィンドウがパンクしてしまうので難しいですね。
あくまで「LLMが読み込める程度の文書規模に収まるか」が、CAGを使うときのまず最初の判断材料になるのです。
文書を準備したら、LLMにそれらを一度通して「KVキャッシュ」を作る作業に移ります。
一般的にはLLMのAPIやモデル内部の仕組みを使い、文書を順番にモデルへ入力して、そこで生成される内部状態(キーとバリュー)を記録します。
論文では「KV-Encode(D)」のような表現で書かれていますね。
この出力がCKV(Cache Key-Value)と呼ばれるデータです。
そして、このCKVはディスクやメモリに保存しておくため、モデルが後から参照するときには「文書を最初から読み込む必要がない」のがポイントです。
LLMが覚えている状態をまるっとキャッシュ化しておいて、「あの文書はすでに読み込んであるから再度読み込む必要はないよ」とするのがCAGの効率の秘密ですね。
ここで注意したいのは、最初にこの事前読み込みとキャッシュ作成を行う段階では、それなりにコストや時間がかかるかもしれないということです。
しかし、それを済ませておけば、その後の問い合わせに対しては即座に回答可能な状態になるのがCAGの最大の利点。
RAGのように毎回検索する必要がないので、大きなワークロードを一度で片付けるイメージですね。
ステップ2:キャッシュを活用した推論の実際
次のステップは、実際にユーザーからクエリが来たときの推論です。
RAGだとクエリを受け取るたびに検索が走りますが、CAGではそんな必要はありません。
すでに作っておいたCKV(キャッシュデータ)をロードし、クエリと結合してLLMへ与えるだけ。
具体的には、「事前にキャッシュされたコンテキスト」 + 「ユーザーの質問(クエリ)」をまとめてモデルに入力し、回答を生成してもらうという流れです。
モデルからすれば、「あ、もう文書はすでに解析済みなんだね。じゃあその文書情報に基づいて答えを書くよ」という感じで、すぐに応答を出せます。
これがCAGが生み出す高速性の要因といえるでしょう。
さらに、検索ステップがないので「検索が外すかもしれない」という誤差要因もほぼありません。
最初に選定した文書が正しければ、変な文書を取り込んで回答を狂わせる心配も少ないです。
もちろん「最初に間違った文書を含めてしまった場合」は危険ですが、そこはRAGも同じように「検索でミスるかもしれない」というリスクがあったわけです。
CAGのほうが、いったん読み込んだ文書をまるごとモデルが理解している分、ミスったときも一貫性をもっておかしな回答をする……なんてことも考えられますが、少なくとも検索エラーのリスクはありません。
また、ユーザーがどれだけクエリを投げても、キャッシュを再利用できる限りは処理がほぼ同じコストで済むのは大きな利点です。
RAGの場合、クエリが100回投げられたら100回検索が走りますが、CAGは1回読み込んだ文書をベースに100回回答できるわけですから。
「この文書だけ使いたいんだよね」「この範囲のドキュメントだけ必要なんだよね」というケースなら、めちゃくちゃ効率的ですよね。
一方で、どうしてもコンテキストウィンドウに入りきる範囲しか扱えないのは変わりません。
だからこそ「検索不要なんだ! 無限に何でもできるんだ!」と期待しすぎると痛い目にあうかもしれない。
CAGはあくまで「管理しやすい文書量」による知識統合を想定している点は覚えておきたいですね。
ステップ3:必要に応じてリセットするメカニズム
最後のステップは、「キャッシュをリセットする」メカニズムです。
これは、CAGが長時間動いているときに、キャッシュに新たなトークンが追加され続けて肥大化してしまう状況をリフレッシュするための仕組みだと考えてください。
論文では「新しいトークンを切り捨てる」といった表現があり、具体的にはメモリ上に追加されてきたトークンを一定のタイミングで再初期化し、キャッシュサイズを元に戻すという感じです。
要するに「増えすぎたら部分的に消すことでパフォーマンスを維持する」とでも理解すればOK。
ここは技術的な細かい話かもしれませんが、長文LLMで大規模な文書を扱うと、どうしても途中でコンテキストが広がりすぎてしまうリスクがあります。
CAGのアプローチでは大量の文書を一度に読み込むため、キャッシュ自体が巨大になりがちなんですね。
でもそれを適度にリセットすることで、モデルを再起動したり、もう一度すべてを最初から計算し直したり、という手間を最小化できるという狙いがあります。
「キャッシュをリセットしつつ、また必要なときはロードし直す」なんて手順を踏めば、長期間運用してもパフォーマンスが安定しやすい。
こうしたキャッシュ管理の仕組みこそが、「RAGの検索にはないCAGならではの運用ノウハウ」とも言えます。
RAGでは新しい文書が増えれば検索インデックスを更新しなきゃいけないし、CAGではキャッシュ生成をやり直さなきゃいけない。
結局どちらにしろメンテは要るんですが、検索かキャッシュかという違いは大きいですよね。
CAGが解決するRAGの課題
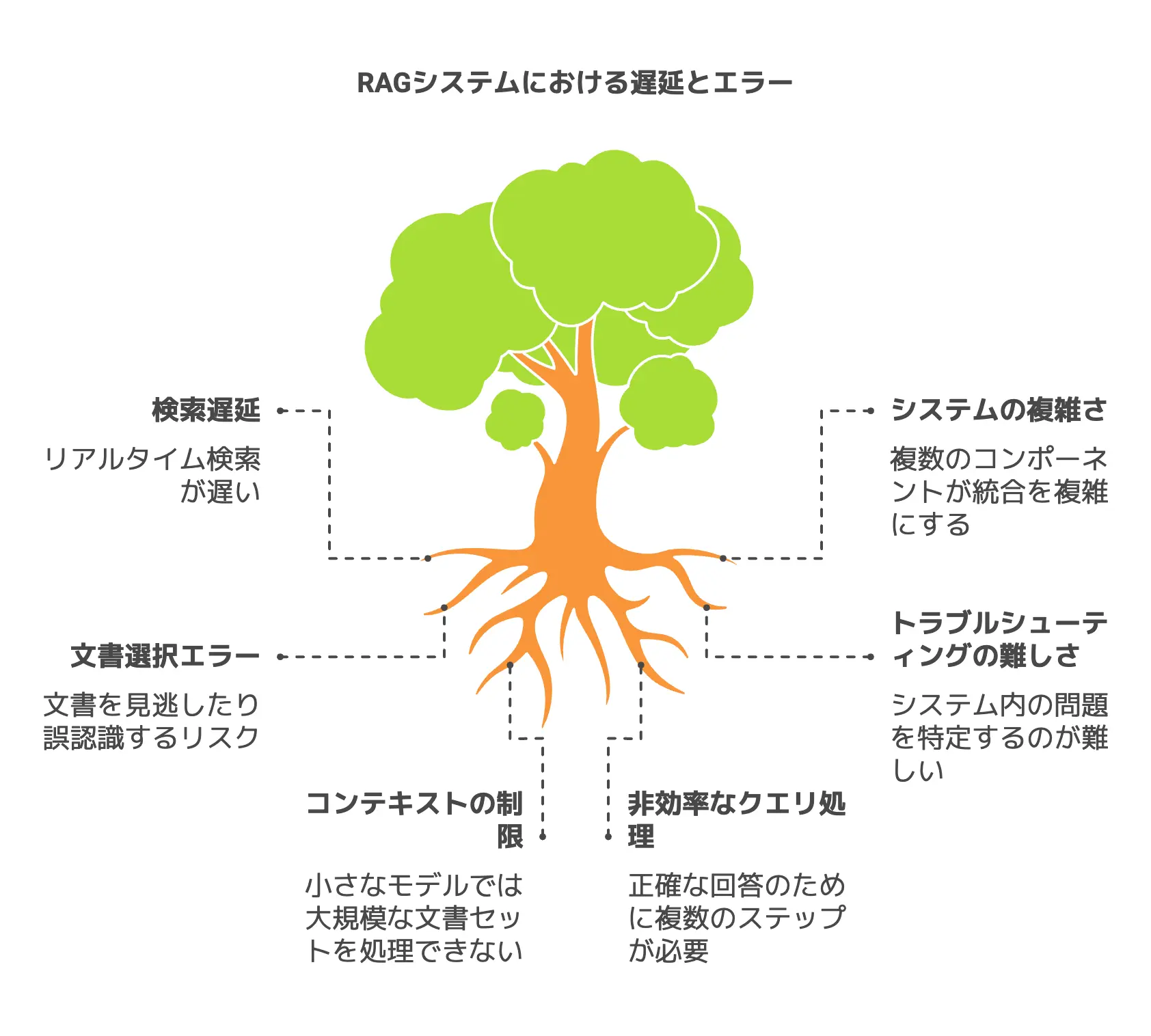
前章の3ステップを経るCAGの仕組みを見ると、なるほどRAGとは別のアプローチで知識を統合していることが分かります。
では、実際にRAGのどんな課題を解決しているのか、具体的に見てみましょう。
RAGにありがちな検索遅延や検索エラー、システムの複雑さを、CAGはどう減らしているのでしょうか。
検索遅延のない快適さとシステムのシンプル化
RAGを使ったシステムでよく耳にするのが、「リアルタイム検索が遅い」「インデックスの更新に手間がかかる」といった問題です。
検索をする以上、検索エンジン部分は絶対に必要で、かつその検索アルゴリズムの精度や速度が回答の質やスピードを左右します。
例えばBM25を使うならBM25の調整が必要だし、デンス検索を使うなら埋め込みモデルを適切に訓練・管理しないといけない。
一方で、CAGではリアルタイム検索を完全に排除し、事前読み込みだけで回答可能という仕組みによって、検索遅延が全く発生しません。
ユーザーから質問が投げられたときに、わざわざ検索クエリを走らせる工程がないからですね。
その結果、推論スピードが飛躍的に上がると論文でも実験結果が示されています。
さらに、検索エンジンを組み込む必要がない分、システム構成がシンプルになるのも大きいです。
RAGの場合は「検索器 + 生成モデル + 統合部分」と三つ巴の連携が必要ですが、CAGでは実質的に「長文LLM + KVキャッシュ管理」のみで済みます。
検索アルゴリズムの変更やインデックス更新、検索と生成の連携設計などに手を取られることが減り、開発や保守が楽になるかもしれません。
特に、トラブルシューティングがしやすいのも地味に嬉しいポイントだと思います。
RAGでは「検索エンジンのどこかがおかしいのか? それともLLMの応答が悪いのか?」みたいに原因切り分けが面倒になりがちです。
CAGならキャッシュさえ正しく作られていれば、あとはモデルの出力を見れば済むので、原因特定がシンプルになるでしょう。
このように、検索による遅延もシステムの煩雑さも、CAGなら大幅に軽減できるというのが論文のメイン主張のひとつです。
文書選択エラーを極力減らす包括的なアプローチ
もう一つの重要な利点として、「文書選択エラーを排除しやすい」ことが挙げられます。
RAGの検索ステップでは、どうしても「必要な文書を取りこぼしたり、不要な文書を拾ってしまう」リスクが付きまといます。
しかしCAGは「そもそも最初から対象となる文書を全て読み込んである」ので、後から変な絞り込みをする必要がありません。
もちろん、最初の段階で「対象文書の集合」を間違えたら意味がないんですが、そこは手動で選別すればOKという話です。
一度選んでしまえば、それらをまとめてキャッシュ化し、モデルがすべて把握した上で回答を出せる状態を作ります。
よって、検索アルゴリズムのランク付けのミスや、キーワードの取りこぼしなどが原因で「本当はあるはずの答えが出ない」という事態は減るはずです。
また、モデルが文書を一括で理解できるため、複数文書に跨る複雑な参照も行いやすいと論文では言及されています。
RAGの場合、検索で返ってきた文書同士の文脈関係をLLMが十分に掴めないまま回答しちゃうケースもありますが、CAGだと最初から全体を読んでキャッシュを作っている分、俯瞰した理解が期待できるわけですね。
この点は特に「マルチホップ推論」を要するような高度なQA(質問応答)で強みを発揮するかもしれません。
たとえばA文書とB文書の内容を掛け合わせないと導けない答えがある場合、CAGならすでに全文書がキャッシュ化されているので、モデルが自然な形で両者を結び付けられるんです。
RAGだと「AとBを正しく検索しなきゃいけない」「検索結果をモデルが正しく合成しなきゃいけない」と2段階のリスクがありましたが、CAGでは最初からAもBも取り込んだ状態で推論できるというわけですね。
つまり、文書選択ミスがほぼなく、総合的なコンテキスト理解に強いのがCAGの利点。
一方で、やはり「膨大すぎる文書を全部読み込めるのか?」という課題は残りますが、対象範囲が限られていれば相当に強力な手法だと言えるでしょう。
大規模LLMの強みをフル活用した高精度の回答
CAGの前提として、「ある程度コンテキストウィンドウが大きいLLMを使う」ことが挙げられます。
これまで触れてきたように、もしコンテキストサイズが小さいモデルしか無いなら、最初に大量の文書を読み込むなんて芸当はできないわけです。
ところが最近のLLMでは、GPT-4の一部モデルは数万トークンのコンテキストウィンドウをサポートしていますし、これからもっと拡張される可能性が高いですよね。
さらに、長文LLMは文脈を俯瞰的に捉えて統合する能力が高いという特性があり、それとCAGの「すべての文書を一度に取り込む」という方式が非常に相性が良いです。
モデルからすると、事前に読み込まれた文書が全部キャッシュにある状態なので、「文書Aの第3段落での記述と文書Bの終わりの方の注釈を組み合わせると、こういう結論になる」みたいな多角的推論がやりやすいんです。
RAGでも似たようなことは可能ですが、検索で抽出する文書数に限りがありますし、複数の検索結果を混ぜ合わせるときにモデルが混乱するリスクも大きい。
CAGなら最初から「文書AもBもCもDも、全部キャッシュされてますよ!」という状態でLLMが推論するため、多重検索の段階で起こり得るエラーや漏れを極力減らすことができます。
また、大規模LLMの高度な言語理解力をフルに活かせるのもポイントです。
RAGが外部検索から得た文書を単純に与えるだけだと、どうしても文書同士のつながりを拾いきれないことがありました。
CAGは「事前に全部読み込んでいる」状態をモデルが内面化できるので、文書間の関連性や構造的な知識を統合しやすいのです。
結果として、より高精度な回答が期待できるというのが論文でも強調されています。
実際、後ほど触れる実験ではRAGを上回るBERTScoreをマークするなど、定量的にCAGの優位性が示されています。
もちろん「常にCAGがRAGより優れている」というわけではなく、対象文書のサイズや更新頻度、運用形態によってはRAGの方が便利なケースもあるでしょう。
ただ「RAGの弱みを知ったうえで、CAGがそれをカバーできる可能性は大いにある」というのが論文の言い分なのです。
どれくらい速い?CAGの推論スピード徹底比較

ここからは、推論スピードという観点でCAGがRAGに比べてどれほどアドバンテージを持つのかを見ていきます。
CAGは検索ステップを省略するため、理論上はRAGよりもずっと速いはずですが、実際にはどれくらいの差が出るのでしょうか。
論文によると、実験で得られた成果はかなり興味深い数字でした。
インコンテキスト学習との時間差はどの程度?
まず、CAGにおける「推論スピード」と言っても、比較相手はひとつではありません。
論文で触れられているのは主に「RAG方式」と「インコンテキスト学習方式」、そして「CAG方式」の速度比較です。
インコンテキスト学習(In-Context Learning)というのは、単純に「LLMのコンテキストウィンドウに、必要な文書をその都度貼り付けて推論させる」手法を指します。
要は検索はしないけど、クエリが来るたびにそのクエリに対応する文書を事前にコピペするイメージ。
すると、クエリが来るたびに「文書読み込み+推論」という流れが必要になるため、連続したクエリに対しては結構な時間がかかってしまうのが問題でした。
CAGでは、一度KVキャッシュを作ってしまえば、後から何回クエリが来てもキャッシュは使い回しできるので、インコンテキスト学習と比べるとその後の推論が桁違いに速くなります。
論文によると、特に大量の文書(長い参照テキスト)を扱う場合に差が顕著だそうで、インコンテキスト学習だと数十秒、数分かかってしまうような処理が、CAGなら数秒以内に終わるケースもあったと報告されています。
これはイメージ的にも納得しやすいですよね。
毎回1万トークン以上の文書を貼り付けて推論するのか、それとももう読み込んであるからクエリだけ渡すのか、後者が速いのは想像に難くない。
あなたがAIを業務に活かそうとするとき、多数の問い合わせを同じドメインで処理するシチュエーションなら、CAGの高速性は非常に魅力的だと思います。
実際の実験結果で見る速度の優位性
論文では、具体的にSQuADやHotPotQAといったQAデータセットを用いて、RAG方式やインコンテキスト学習方式との速度比較を行っています。
結果として、CAGは「参照テキストが長くなるほど、推論時間が圧倒的に短い」という傾向を示したんだとか。
RAGの場合、文書検索に要する時間が結構バカにならないですし、さらに取得した文書をLLMに食わせて推論するステップもあります。
CAGは事前にキャッシュを作る段階で時間がかかるかもしれませんが、一度作ってしまえばその後の推論は一貫して高速に行える。
なので長い文書を何度も参照しなければいけないケースならば、その差がますます開いていくのです。
また、インコンテキスト学習方式と比べても、CAGは複数クエリに対応するときに有利です。
インコンテキスト学習では毎回文書をコピペするようなもので、そのたびに大量のトークン解析が必要です。
CAGは「キャッシュ済みデータがあるから、解析をもうしなくて良い」というわけで、一度の読み込み後は質問数が増えても推論コストがあまり増えません。
論文に掲載されている数字としては、たとえばHotPotQA Largeサイズで、「CAGを使わないと推論が94秒ほどかかるのに対し、CAGだと2秒ちょっとで済む」というような例があります。
このように数十倍以上の速度差が平気で出ることがあるので、ビジネスの現場では大きなメリットと言えるでしょう。
長文テキストでも威力を発揮する理由
CAGが長文テキストでこそ効果を発揮する理由は、「事前に作るキャッシュが、まさに長文LLMの文脈理解をすでに完了した状態だから」です。
長いテキストをその都度モデルに入れるとなると、インコンテキスト学習方式でもかなりの計算コストがかかります。
ところがCAGは最初の段階で全テキストを通しておくため、推論時はクエリを添えてモデルに一部の状態を呼び出すだけで済む。
もう少し噛み砕くなら、大規模言語モデルはテキストを読む際に「層を深く通過させながら」理解を積み上げていく構造を持っています。
CAGで言うKVキャッシュは、その理解の最終段階または中間段階を「動的に保存しておいて再利用する」というイメージです。
結果的に「もうすでにほぼ全解析が終わってるから、今さら文書読み込みには時間がかからない」という状態になるわけですね。
この手法が長いテキストや大量の文書を相手にするほどコスパが良いのは、事前準備が重たい分だけ後で得するモデルだからとも言えます。
1度や2度だけ質問に答えるならRAGやインコンテキスト学習でもいいかもしれません。
でも何度も繰り返し回答を求められるようなシステムであれば、CAGにした方が初期コストを回収できる可能性が高いです。
特に企業内で「似たような質問が頻繁に出る」とか、サポートセンターで「限られたマニュアルに基づく回答を大量にする」とか、そういう場面ではCAGを導入することで爆発的に対応速度が上がるかもしれません。
これこそがCAGが「検索エンジン不要」と豪語できる理由で、長文LLMが使える環境下でのみ成り立つという点も忘れてはいけないポイントですね。
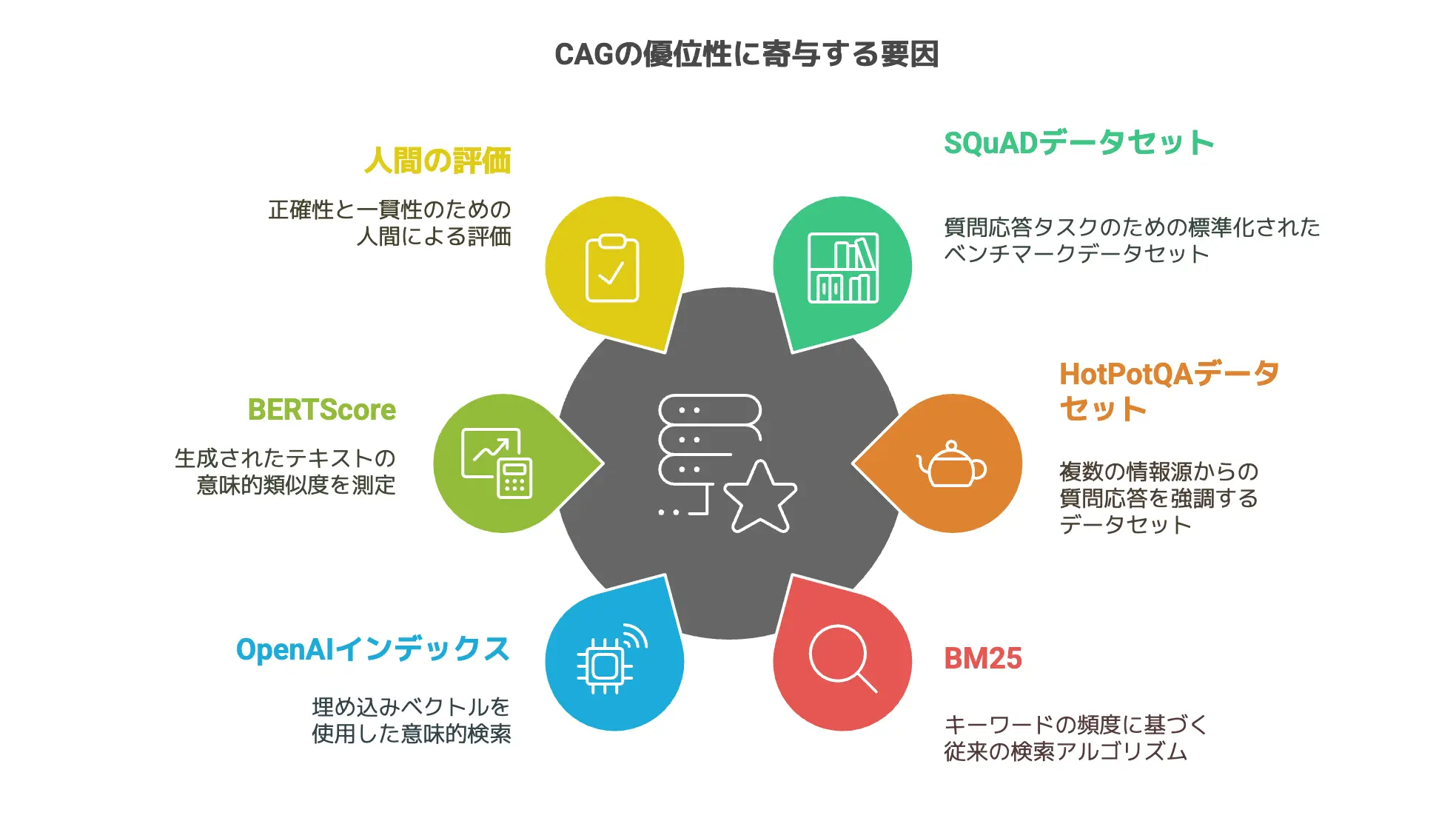
具体的な実験事例:SQuADとHotPotQA
最後に、CAGが実際にどのような実験データセットでテストされ、どんな結果を出しているのかを紹介します。
論文で取り上げられている代表的なQAデータセットとして、SQuADとHotPotQAが用いられています。
これらのデータセットは、質問応答タスクのベンチマークとして広く使われており、RAGとの比較もやりやすいという特徴があります。
RAGのベースラインはBM25とOpenAI Indexes
実験では、RAGの比較対象として「スパース検索:BM25」と「デンス検索:OpenAI Indexes」が利用されています。
- BM25
これは従来からある検索アルゴリズムで、キーワードの頻度や文書長の正規化を使って関連性を評価します。
単語ベースのスコアリングなので、人間のニュアンスを汲み取るような検索は苦手だけど、シンプルで計算が軽いのが利点です。 - OpenAI Indexes
こちらは埋め込みベクトルを使ったデンス検索の仕組みを想定しており、意味的な関連度を考慮して文書を探せるのが特徴です。
単純なキーワードマッチではなく、文章全体の意味づけをベクトル空間に落とし込んで照合するので、表現が違うが意味は近いといったケースを拾いやすいというメリットがあります。
RAGを実装する際、この2種類の検索アルゴリズムを使ったシステムをベースラインとしておき、「トップ1件だけ文書を渡す場合」「トップ3件渡す場合」「トップ5件、10件……」といった具合に複数パターンで評価が行われたとのこと。
これによって、検索段階で候補を何件拾うかによって回答精度や速度がどう変わるかも見られています。
結果をザックリ言えば、CAGはどのパターンと比べても高精度かつ高速だったというのが論文の主張です。
当たり前と言えば当たり前ですが、RAG方式における検索精度と速度の限界を、CAGは「検索しない」という方法で一気に抜き去ってしまうわけですね。
特に、BM25のようなスパース検索はキーワードマッチが厳しく、クエリによっては間違った文書を拾いがちで、回答の精度が落ちる傾向があったようです。
OpenAI Indexesのデンス検索は精度こそ上がるけど計算コストも上がり、やはり検索遅延は避けられないという結果に。
このように、RAGの代表的な検索器を相手にしても、CAGは十分な比較優位を示すことに成功したようです。
ただし、これはあくまで「参照文書数が一定に収まる」実験設定であり、無限に文書が増えるケースではまた別の話でしょう。
いずれにせよ、SQuADやHotPotQAのような定番QAタスクで、CAGがRAGより優秀な指標を出したことが非常に興味深いわけです。
なぜCAGが優位?BERTScoreなど評価指標の分析
では、なぜここまでCAGがRAGより優位だと結論づけられたのか。
論文の中で使われている評価指標のひとつにBERTScoreがあります。
これは生成テキストの類似度をBERT(別の大規模モデル)を使って測り、参照回答との意味的類似度を数値化するメジャーな方法です。
RAGはどうしても検索した文書の品質に左右されます。
もし検索で微妙に違う文書を引き当ててしまうと、モデルはそこからズレた回答を作ってしまい、BERTScoreが下がる。
一方のCAGは、最初に対象文書を完全にまとめて読み込むため、検索段階でのミスがないんですね。
さらに複数文書を俯瞰的に扱える分、複雑な文脈を踏まえた正確な回答を作りやすいという強みもあります。
もうひとつは、回答の一貫性や文脈のつながりにもCAGが強いと言われています。
RAGだと検索結果ごとに文脈が切り替わる可能性があるのに対し、CAGは最初から全体を読んでいるので、回答がブレにくい。
論文でも、CAG方式で生成された回答の方が文章として整合性を保ちやすいという事例が示されています。
このあたりはBERTScoreだけではなく、他の指標や人間のアノテーション(回答を人間が見て正しさをチェック)などでも評価され、「CAGは高精度だね」と結論付けるに足る根拠が提示されています。
だから論文タイトルにもあるように「Don’t Do RAG」、つまり「RAGを無理にする必要はないよ」と言っているわけです。
大量の文書を処理するときのCAGの強さ
SQuADやHotPotQAというと、ある程度ボリュームのあるQAデータセットですが、実際にはもっと膨大な文書を扱う場面もあるでしょう。
論文でも触れられていましたが、もしあなたが「ニュースアーカイブの何万記事も取り込みたい」と考えたら、CAG単体ではコンテキスト上限的に厳しいかもしれません。
しかし、数万件レベルではなく数百件〜数千件くらいまでの文書なら、適切に前処理・圧縮を行うことでCAGで扱える可能性があるとされています。
特に、重複や類似度の高い文書をまとめておくとか、本当に必要な箇所だけを抽出してキャッシュ化するといった工夫をすれば、CAGの枠内に収められるシーンも多いと思います。
そうなるとRAGのように文書検索を回さなくても済み、推論時間の速さと高精度回答の恩恵を受けられますよね。
また、CAGを段階的に適用するハイブリッド方式の議論も少し出てきます。
つまり、最初にざっくり文書を絞り込む検索をやって(ここは単純なキーワード検索でもいい)、その後にCAGでキャッシュを作るというアプローチです。
そうすれば膨大なドキュメントをすべてキャッシュする必要はなく、ある程度筋の良いサブセットだけをCAGで扱うことが可能になります。
いずれにせよ、大量の文書を扱う場面でも「RAG一択」ではなくなりつつあるということで、CAGはRAGに代わるエコシステムを生み出しうると論文では主張されています。
どちらも極端に振り切った形ではなく、状況に合わせて組み合わせるのが理想なのかもしれませんが、少なくとも「検索不要でこんなに高速高精度な回答ができる」ことに多くの研究者が驚いているのは確かでしょう。
CAGが向いている状況とメリット
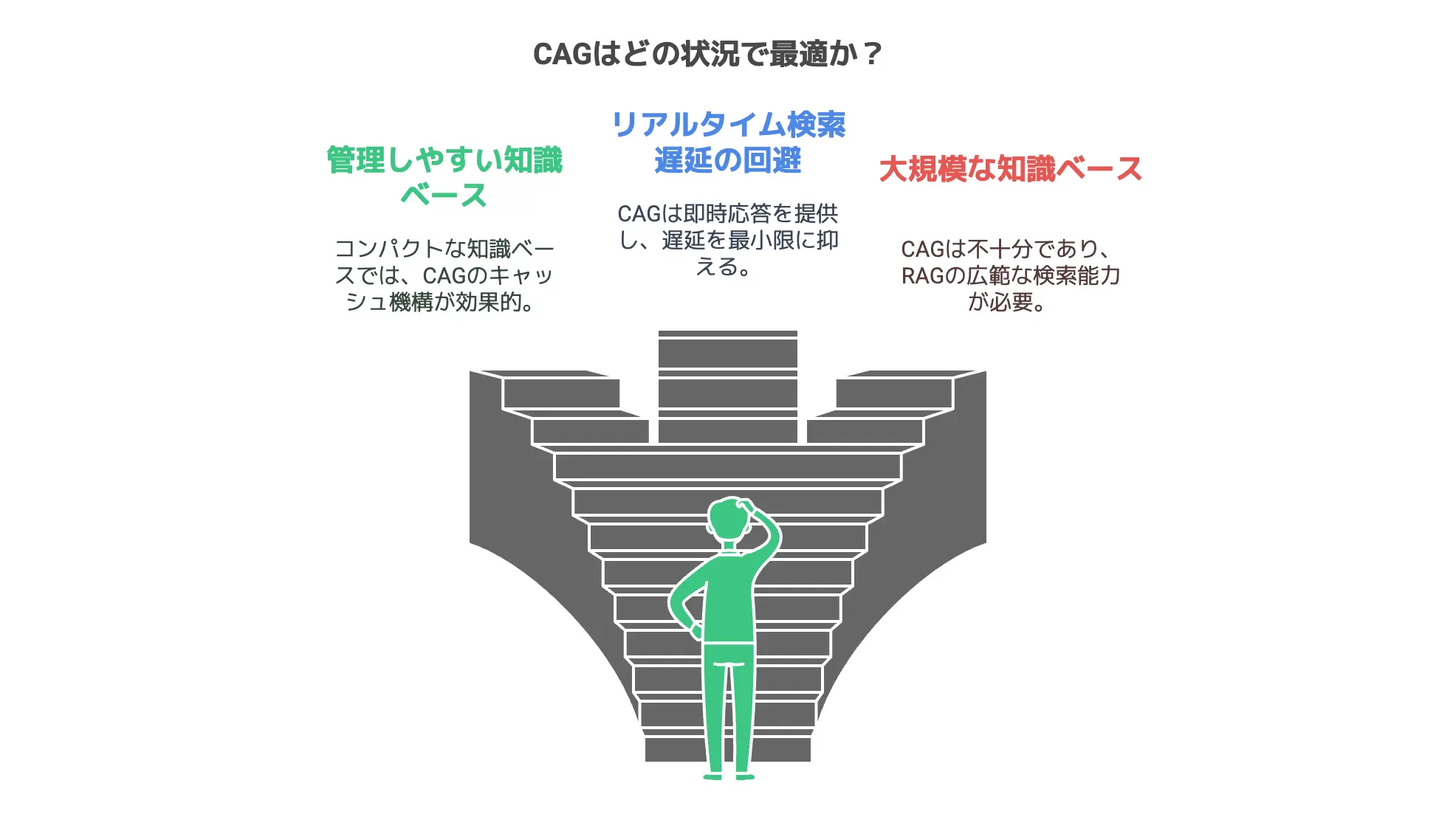
ここからは、CAG(Cache-Augmented Generation)が具体的にどんな状況で有効に機能するのかについて書いていきます。
一言で「CAGなら検索が不要です!」と言っても、やはり全てのケースでCAGが最適解というわけではありません。
しかし、RAG(Retrieval-Augmented Generation)の課題を正面から解消する方法として、CAGは明らかにインパクトのある手法だと感じます。
特に、以下のような要件を持つシステムではCAGがとてもマッチする可能性があります。
「大規模な外部検索が必要なく、知識ベースの内容がある程度限られている」だとか、「ユーザーからのクエリ数が多く、いちいち検索していたらレスポンス遅延が気になる」ような場面です。
こうした状況下では、事前にキャッシュを作成しておけば、後は高速かつ安定的に回答を出せるCAGの強みが際立ちます。
さらに、「管理が簡単」かつ「シンプルなアーキテクチャで済む」というのもCAGを導入する大きな魅力。
RAGだと検索エンジン部分をどう構築するかがシステムの複雑さを増やしますが、CAGでは少なくとも検索器の運用は不要になるからです。
では、具体的にどのような状況でCAGの真価が発揮されるのか。
これから3つの視点で検討してみましょう。
管理しやすい知識ベースならCAGがおすすめ
あなたのビジネスで扱う知識ベースが、ある程度コンパクトで管理しやすいという状況なら、CAGは断然おすすめです。
なぜなら、CAGの大前提として「コンテキストウィンドウに収まる程度の文書量」もしくは「最初の段階でまとめてキャッシュできる程度の知識規模」が必要だから。
これがもし何千万件ものドキュメントを抱える大規模検索システムなら、CAG単独で全部を内包するのは物理的に厳しい場合もあるでしょう。
しかし、たとえば社内のFAQや限定的な業務マニュアル、あるいは特定分野の研究論文だけなど、ドメインが明確に限定された知識ベースなら、先に一括で取り込んでしまうのが圧倒的に楽です。
こういった運用形態の一例を、もう少し噛み砕いて考えてみましょう。
- 自社FAQの例
あなたの会社でよく寄せられる質問集をまとめたFAQ文書があるとします。
ページ数にして50や100程度、トークン換算でも数万から十数万くらい。
これなら長文LLMのコンテキストに収まるレベルに整理することが可能かもしれません。
事前にそれらをKVキャッシュ化しておけば、ユーザーがFAQに関する質問を投げても、CAG側は検索なしで瞬時に回答を生成できるようになるのです。 - 専門領域の小規模知識ベース
例えば「医学論文のうち、特定疾患に関するものだけ」「建築法律のうち、特定地域と用途に絞ったものだけ」など、絞り込みがはっきりしているデータセットならば、CAGに向いていると考えられます。
そもそも必要な文献がそこまで多くないのに、RAGを導入して大掛かりな検索エンジンを整備するのはオーバーエンジニアリングかもしれません。
それよりも、さっとキャッシュを作ってスピード回答ができる体制を敷く方がコスパが良いです。
こういったケースでは、RAGのメリット(無限に広い知識を検索できる)がさほど必要ではないわけです。
むしろ、検索のオーバーヘッドが邪魔になりかねないので、CAGで「不要な検索を全て省いて効率アップしたい」というニーズと合致するはず。
また、管理しやすい知識ベースであるがゆえに、文書の更新頻度が低いこともCAGにはプラスに働きます。
RAGだと追加・修正があるたびにインデックスの更新を考えなければいけませんが、CAGではキャッシュを再度作り直すだけで済むという単純さ。
もし月に1度しか改訂がないなら、そのタイミングでまとめてキャッシュを再構築してしまえば良いわけです。
このように、規模がそれほど大きくなく、頻繁な更新もない知識ベースをお持ちの場合は、CAGの方がシンプルかつ高速に運用できる可能性が高いです。
結果として、文書選択ミスや検索遅延からも解放されるので、RAGで苦労していたポイントが一気に緩和されるかもしれません。
リアルタイム検索の遅延を避けたいケース
リアルタイム性が重視されるシーンでも、CAGは強い味方になります。
RAGにおいてリアルタイム検索がネックになるのは、クエリごとに外部検索が走る仕組みだから。
ユーザーが質問を投げるたびにデータベースとの通信が発生し、大量文書の中から候補を選んでLLMに投げ込むわけです。
いくら検索アルゴリズムが高速化したとはいえ、重い処理やネットワーク遅延が皆無になるわけではありません。
この「数秒〜数十秒の検索待ち」が、ユーザーにとっては煩わしいと感じられることもしばしばです。
一方、CAGでは最初のキャッシュ作成時にすべて読み込んであるので、クエリが飛んできたタイミングで検索を挟む必要がありません。
ユーザーの質問とキャッシュを合体してLLMが回答を出すだけの流れで済むため、リアルタイムのレスポンス速度を著しく向上できるのです。
実際、前の章でも触れましたが、同じ長文を毎回インコンテキスト学習で読み込むのと、CAGのキャッシュを再利用するのとでは、推論時間に数十倍の開きが出ることも珍しくないと論文に記載があります。
リアルタイム検索が走るRAG方式に対しても、似たような速度的アドバンテージを得られるわけです。
では、どんな具体例が考えられるでしょうか。
- チャットボットやQAシステム
利用者が次々と質問を投げかけるような環境では、毎回検索に数秒かかってしまうとユーザー体験が悪くなる。
CAGなら即レスを実現しやすいので、サポート業務や対話型システムにはうってつけです。 - 対話型アプリケーション
コールセンターのオペレーター支援ツールなどで、オペレーターが質問入力をするたびにレスポンス遅延が大きいとストレスフルですよね。
これもCAGを使って事前キャッシュを準備しておけば、高速に回答を提示してくれます。 - イベント会場やリアルタイムサービス
リアルタイムで大量の質問が飛び交うような場面(オンラインセミナーのQ&Aなど)でも、検索待ちが重なると混雑を起こします。
しかし、CAGなら1度キャッシュを作っておけば、繰り返し高速応答が可能になるので、同時アクセスが増えても比較的対応しやすいでしょう。
このように、「遅延を極力減らしたい」状況においては、RAGの検索ステップが原因で足を引っ張る可能性が高いです。
CAGはその弱点を排除しているので、ユーザーに素早い応答を返さなくてはならないシーンでこそ実力を発揮すると考えられます。
システムをシンプルに維持したいプロジェクト
RAGが嫌われる理由のひとつに、「検索器と生成器を両立させるアーキテクチャの複雑さ」があります。
たとえば企業がRAGシステムを構築する場合、検索に関連するインフラ(データベース、インデックス管理、クローラなど)と、LLMを扱う推論基盤を組み合わせなければなりません。
このとき発生するのが、「検索性能のチューニングがうまくいかない」「新しい文書が追加されるたびにインデックスを更新しなきゃいけない」「検索器と生成器の通信負荷が大きい」などの問題です。
また、トラブルが起きた際に、検索部分が原因なのか、それともモデル側が原因なのかを特定するのもやや面倒になります。
一方、CAGのメカニズムは「LLM + KVキャッシュ」がメイン構成で、検索のステップがほぼ存在しません。
よって、システムとしては非常にシンプルに済むわけです。
- 運用保守が楽
先述した通り、RAGのように検索インデックスを都度更新する必要がなく、キャッシュさえ作り直せばOKです。
同じ知識ベースを運用する限りは、1回作ったキャッシュを長期間使い回せます。 - 故障箇所の切り分けが単純
検索器が無いので、もし回答が悪いと感じた場合は、単純に「キャッシュ化した文書が不足または誤っている」「モデルの推論精度がいまいち」というところに絞られます。
分析がしやすく、トラブル対応がスムーズになるでしょう。 - 実装コストが下がる
一から検索システムを導入しようとすると、それなりにノウハウや技術力が必要です。
しかしCAGなら、LLMとキャッシュ管理部分さえ実装できれば、後はクエリとキャッシュを組み合わせるだけなので、比較的楽に開発が始められるかもしれません。
特に、スタートアップ企業や小規模チームで、あまり大掛かりなシステムを組めないケースでは、CAGの方が導入しやすい気がします。
「検索エンジンの実装なんてハードルが高いし、そこまで大規模な文書量でもない」という状況なら、まずCAGを試してみるという判断は大いにアリでしょう。
総合的に見ると、「管理が簡単」「開発や保守がしやすい」「デバッグも分かりやすい」という3拍子が揃うのがCAGの魅力。
RAGから移行するにしても、検索器を外してキャッシュ生成に特化したパイプラインを作るだけなので、大幅に楽になる可能性が高いです。
こうして見ると、CAGは単なる技術的手段にとどまらず、システムをスリムかつ高速に維持したいというプロジェクトの理想形にも近いのかなと、僕は感じています。
長文LLMがCAGをさらに進化させる可能性
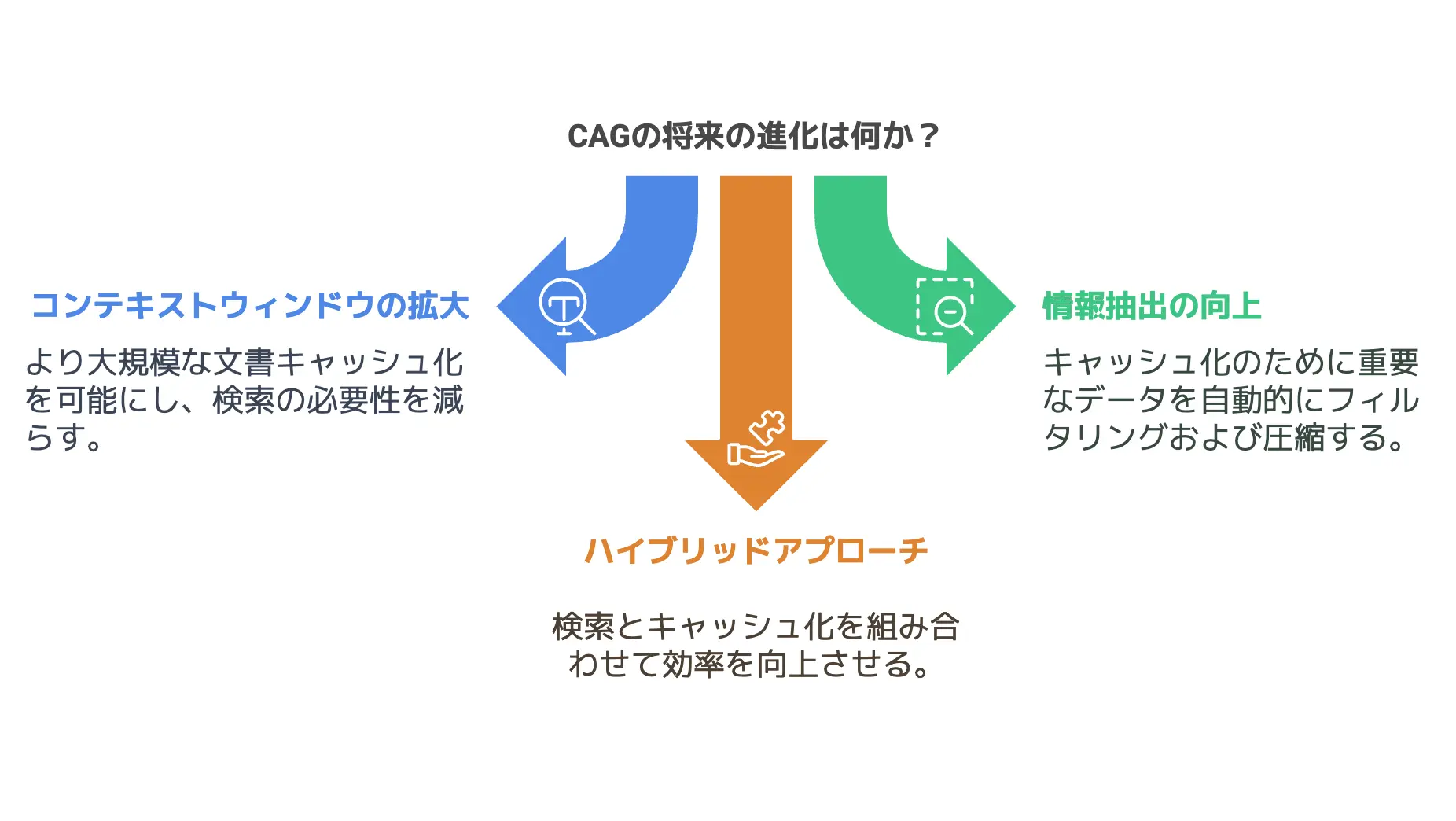
ここまではCAGの具体的な運用シーンやメリットを見てきましたが、今後のLLM(大規模言語モデル)の進化によってCAGがどう発展するのかも気になるところです。
なぜなら、現在主流の大規模言語モデルでもコンテキストウィンドウは数万トークンが限界というケースがほとんど。
しかし、近い将来にはコンテキストウィンドウがさらに拡大し、数十万、数百万トークンを扱えるモデルが登場してくるかもしれません(ちなGoogleのGeminiは100万トークン以上を扱えます!凄すぎ!)。
そうなると、CAGの弱点だった「キャッシュに取り込める文書量の限界」がもっと緩和されるでしょう。
それだけでなく、情報抽出能力のさらなる向上や、ハイブリッドアプローチの可能性など、いろいろな拡張が見込まれています。
CAGは「そもそも検索しない」という概念で始まりましたが、今後の研究では検索とキャッシュを組み合わせたハイブリッドアーキテクチャの議論も活発化するかもしれません。
ここでは3つの視点から、CAGの未来に思いを馳せてみましょう。
コンテキスト長の拡大が意味する未来
今日のLLMでありがちな悩みは、コンテキストウィンドウがすぐオーバーしてしまうこと。
特にCAGのやり方で「大量の文書を一度に読み込む」場合、上限を超えると物理的にキャッシュを作れません。
しかし、モデルの拡大や新たなアーキテクチャの登場によって、数十万〜数百万トークンを扱うことが可能になれば状況は一変するはずです。
たとえば、あなたが数百ページ分の資料をCAGでキャッシュ化しようとしても、今は無理でも将来は一度で全部ぶち込めるかもしれない。
そうなれば、単にFAQや小規模データだけでなく、大量の書籍や研究文献をほぼリアルタイムで網羅するのも夢ではなくなります。
これが実現すると、RAGの「幅広い情報を検索できる強み」があまり強みにならなくなる可能性がありますよね。
なにせ検索なしで何十万トークンを読み込めるなら、あえて検索エンジンに頼らなくても、まとめてキャッシュ化したほうが早い&正確になるからです。
つまり、長文LLMの急速な進化がCAGの適用範囲を爆発的に拡張するかもしれません。
もちろん、メモリコストや計算コストとの兼ね合いはありますが、技術は常に進歩し続けるので、数年後には今日の常識を超えたモデルが出てくる可能性は高いと思います。
結果として、「RAGが活躍するシーンが大幅に減っていく」という未来像もあり得るわけです。
もちろんRAGの「どんなに大きいデータでも検索できる」強みは消えませんが、CAG側のキャパシティがどんどん増えるなら、よりシンプルな手段があればそちらに流れるのは自然な流れかもしれません。
情報抽出能力の向上とハイブリッドアプローチ
長文LLMが進化するにつれ、情報抽出能力が飛躍的に向上することも期待されています。
今でもLLMはある程度の要約や構造化をこなせますが、もっと高度な自動的フィルタリングや圧縮ができるようになれば、CAGの手前で文書を自動整理してキャッシュに入れるという流れが理想的に構築できるかもしれません。
どういうことかというと、たとえば「巨大な文書コレクションのうち、本当に必要そうな部分だけを自動で抽出し、圧縮した上でキャッシュ化する」という仕組みです。
これは「検索の事前段階」と「CAGの事前読み込み」を組み合わせるハイブリッドのようなイメージですが、単なるキーワード検索よりもさらに高度に、LLMが意味的に重要なパートだけを抜き出してまとめる可能性もあります。
現状でも類似のことをやっているシステムはありますが、今後さらにモデル自身が情報を取捨選択し、キャッシュ向けに最適化した形へ変換してくれるようになれば、実質的に検索器なしで巨大データにアクセスできる未来が見えてきます。
これはインテリジェントなテキスト圧縮+要約とも言えるし、一種の自己検索的アプローチとも考えられます。
要するに、CAGとRAGのいいとこ取りを狙っているわけですね。
「従来の検索エンジンを入れずとも、LLMが自律的に文書を整理してキャッシュを作ってしまう」という世界が実現したら、検索エンジン技術が大きく再定義されることになるかもしれません。
もちろんまだまだ先の話かもしれませんが、情報抽出能力の向上がCAGを新たな段階へ引き上げるシナリオとしては十分に plausible(あり得る)だと感じます。
研究で語られるCAGの拡張と新たな活用アイデア
論文タイトルが示すように、「Don’t Do RAG」はいささか挑発的なフレーズです。
しかし、その内側には「RAGに固執しなくてもLLMの使い道はどんどん広がる」というポジティブなメッセージが込められていると、僕は(NotebookLMを使って)読んでいて感じました。
実際、CAGをベースにした研究や実装例はまだ多くはないですが、以下のような拡張アイデアが今後登場するかもしれません。
- 分散キャッシュ
大規模クラスタ環境で、複数のLLMノードがそれぞれのKVキャッシュを分散管理し、必要に応じて相互参照する仕組み。
これが実現すると、より大量の文書を扱いながらも検索器を持たないというハイブリッドシステムが組めそうです。 - オンライン更新
追加文書や修正箇所をリアルタイムにキャッシュへ反映するための高速アルゴリズム。
たとえばKVキャッシュの一部を再計算するだけで済むように工夫し、頻繁な更新にも耐えられるCAGを目指す。 - 高度な文書管理ツールとの連携
ドキュメント管理システム(DMS)などと直接連携して、CAGがキャッシュに取り込める文書を自動選択し、バージョン管理や差分管理を行う。
RAGの検索が不要になっても、文書管理自体は必要なので、そのプロセスをツールでサポートする研究も進むでしょう。
こうした拡張は、CAGが「RAGの対抗馬」という枠組みを超えて、LLM運用全般に大きな変化をもたらす可能性を示唆しています。
もちろん、すべてがスムーズに進むわけではないでしょうし、RAGがすぐに消えることはありません。
しかし「検索に頼らずに大規模知識を取り扱う」という思想は、長文LLMの普及とともに確実に勢いを増すのではないでしょうか。
将来的には「検索」というステップが主役の座を譲り、「キャッシュに頼るアーキテクチャ」が標準になる日が来るかもしれません。
そのときこそ、CAGがRAGに代わる基本的なやり方として位置付けられるのではないか。
そう考えると、この論文が問いかける「Don’t Do RAG」という言葉は、なかなか重みのある先見性を持っているように感じますね。
RAGに頼らない時代?これからの知識活用戦略
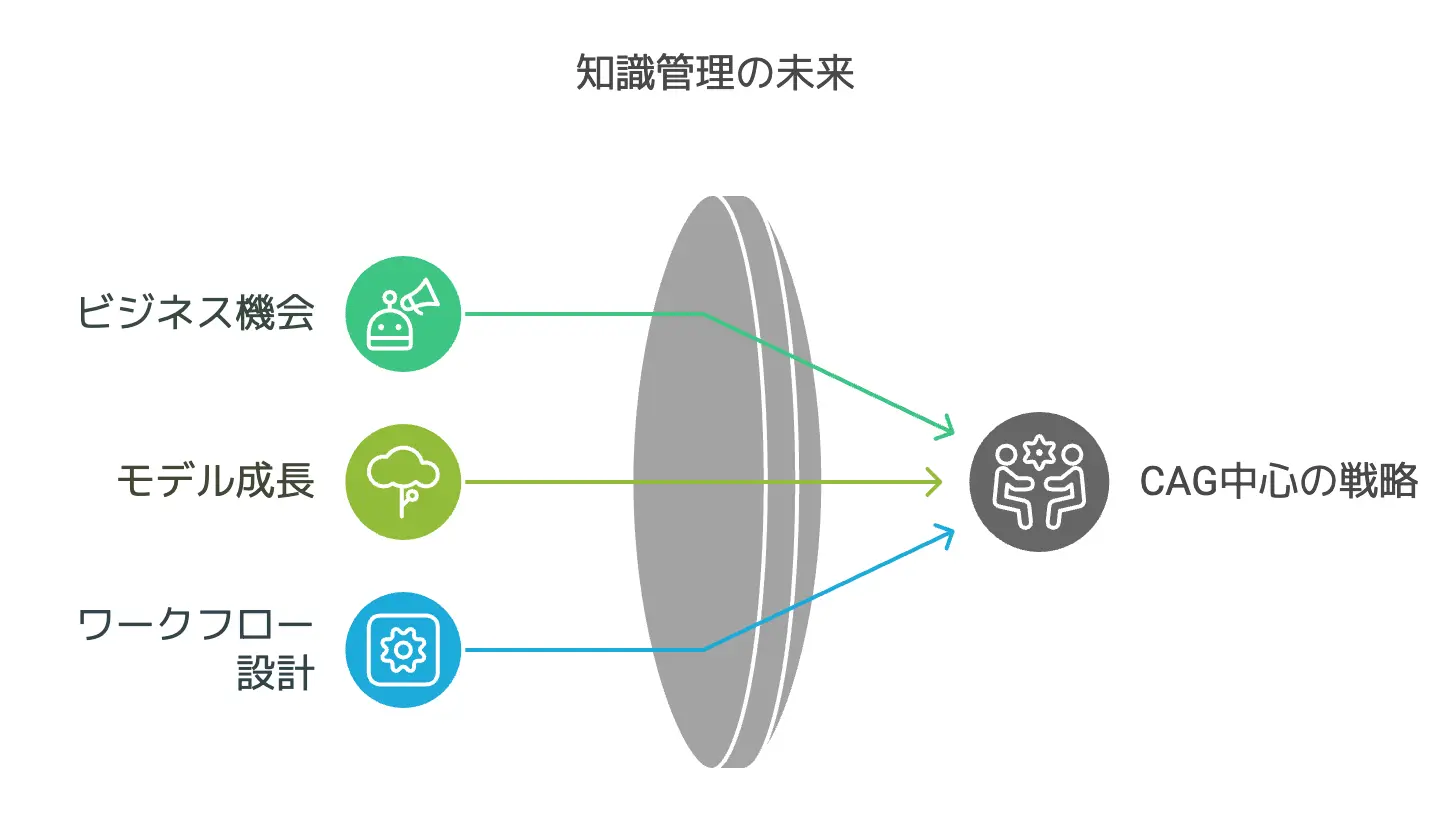
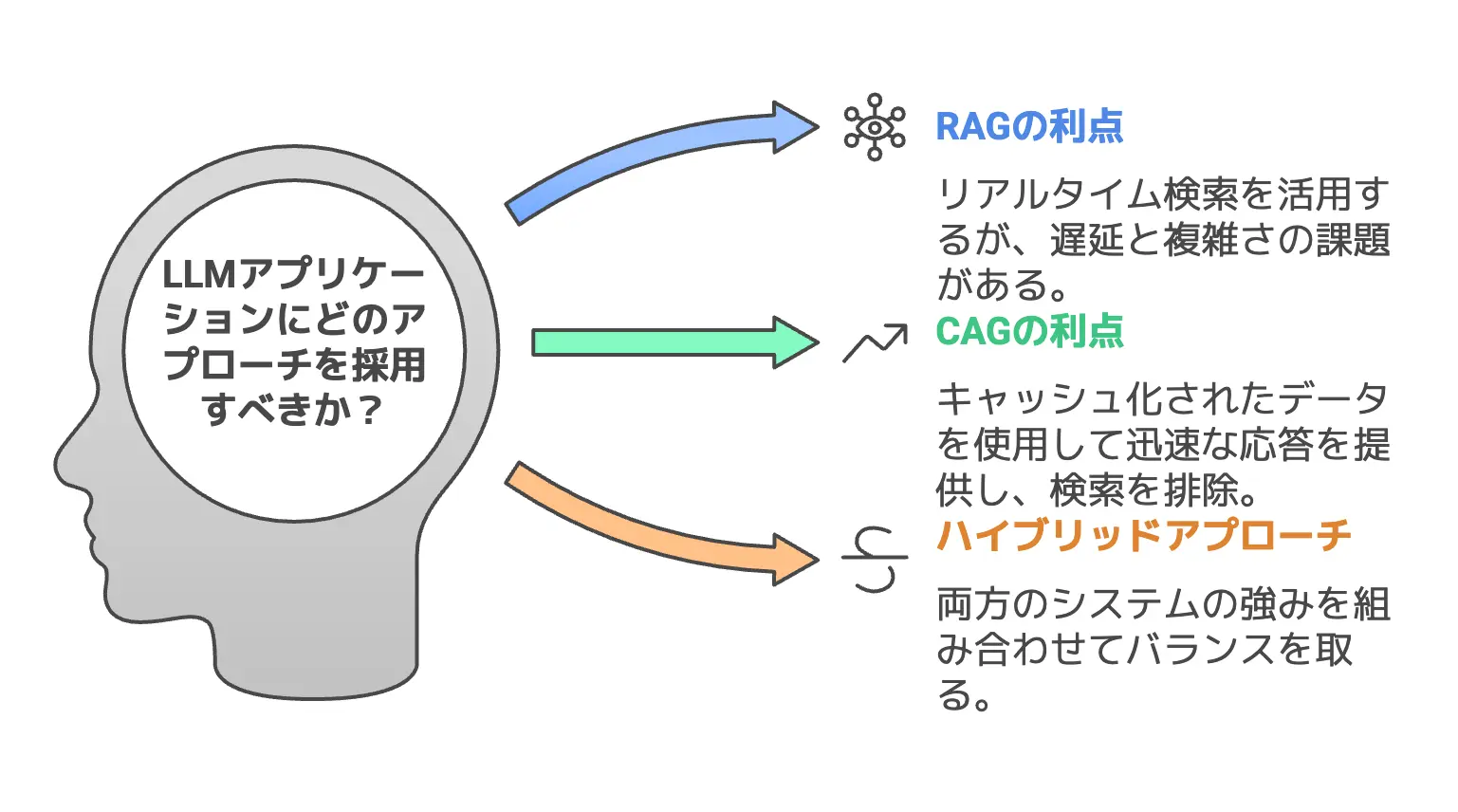
ここまで説明してきたように、CAGはRAGと比べて検索遅延やエラー、システム複雑性などを劇的に軽減できる可能性を秘めています。
では、僕たちが「知識活用戦略」を考えるうえで、どのようにCAGを取り入れていけばいいのでしょうか。
結論としては、RAGを完全に捨てる必要はなくても、CAGを軸にしたワークフローへ大きくシフトするという選択肢が見えてくるはずです。
ここでは3つの観点から、CAGがもたらす新たなビジネスチャンスや、モデル成長による普及予想、そして検索フリー時代の設計ポイントを見ていきましょう。
CAGで実現できる新たなビジネスチャンス
まず、CAGの登場によって生まれるビジネス機会は幅広いと予想されます。
- 高速QAサービス
例えば企業が顧客向けに提供するチャットbotや問い合わせ窓口。
今まではRAGで検索ステップがボトルネックになっていた場合でも、CAGなら瞬時応答を実現できる可能性があります。
結果として、顧客満足度が向上し、同じ人員でも処理できる問い合わせ件数が増えるかもしれません。 - 専門分野への特化型ソリューション
例えば医療や法律、金融など、限られた文書だけを集中的に扱うケースではCAGの強みが最大限に発揮されるでしょう。
特定分野の知識ベースをキャッシュとして作り込んだLLMコンサルタントサービスを提供すれば、今までRAGで苦戦していたプロジェクトでもスムーズに導入が進むかもしれません。 - エッジデバイスやオフライン環境での応用
検索にインターネットアクセスを要するRAGと違い、CAGは事前にキャッシュを作っておけばオフラインでも動作可能なシステムを組める可能性があります。
もちろんLLM自体をどこで動かすかの問題は残りますが、少なくとも外部データベース検索が不要なら、ネットワーク接続の不安定な環境でもある程度対応できるという利点が考えられます。
このように、「検索に依存しない」ことが新しい顧客体験やサービス形態を生む要因になりうるわけです。
特定企業の内部文書をまとめてCAG化して「高速AIコンサルツール」として売り出すなど、アイデア次第でビジネスチャンスは大きいでしょう。
大規模言語モデルの成長とCAGの普及予想
次に、大規模言語モデルがさらに進化したとき、CAGはどれだけ普及するのかという視点です。
先ほども触れたように、LLMのコンテキストウィンドウが拡大し、メモリ使用量や計算コストとのバランスを取りながらも、より多くの文書を一度に読み込める時代が来るかもしれません。
そうなれば、「RAGの強みが縮まる」という図式がさらに加速するでしょう。
「新しい情報を検索して取得する」よりも、「元から膨大な情報をひとまとめにしておき、モデルがカバーしている状態」を好むシステム設計が増えるはずです。
実際、今でもクロスドメインな検索を必要とする場面を除けば、CAGで十分まかなえるケースは少なくありません。
ここにコンテキスト長の飛躍的向上が加われば、CAGは一般的な知識タスクのスタンダードになるかもしれない、というのが論文の示唆する未来像。
また、ハードウェアの進化も見逃せないポイントです。
GPUやTPUなどの高速演算環境がさらに進化して、CAGのキャッシュ作成プロセスやLLM推論自体がもっと高速&低コストになっていけば、個人単位でもCAGが使いやすくなるかもしれません。
RAGほどのインフラがいらないのであれば、中小企業や個人が「自分専用のCAGシステム」を持つのも夢ではありません。
こう考えると、大規模言語モデルの拡張はCAGの普及を強力に後押しする要因になると言えるでしょう。
RAGが不要というわけではないですが、「限られた範囲で最大限の性能を発揮するCAG」の活用範囲は今後ますます広がっていくと予想できます。
検索フリー時代のワークフロー設計ポイント
では、「RAGからCAGへ」流れが進むと仮定したとき、具体的にどんなワークフローが生まれるのか。
個人的には、以下のような設計ポイントを意識すると良いのではと考えています。
- 文書選定と前処理
まず、CAGに適した文書をどうやって選ぶかが重要。
全部詰め込むのではなく、必要な領域やトピックを絞り込んだうえで、ノイズ除去や重複排除、要約などの前処理を丁寧に行うのがベストです。 - キャッシュ生成のタイミング
どのタイミングでKVキャッシュを作り直すのかという点も設計の要。
リアルタイム更新が必要なシステムなのか、それとも週1回や月1回程度で十分なのか。
ここを見誤ると「キャッシュ更新が追いつかない」という事態にもなりかねません。 - メモリ容量とスケール
長文LLMの活用はメモリや計算資源を食う可能性が高いです。
現状のLLMに見合った文書サイズを選び、もし数万〜数十万トークンを超える場合はパーティショニングや段階的キャッシュ化を検討するのも一つの手でしょう。 - 既存RAGとの併用検討
どうしても広範な検索が必要な業務や、リアルタイムに更新される膨大なデータを扱う場合、RAGを完全に捨てるのは難しいかもしれません。
この場合、コアとなる知識領域はCAGで対応し、それ以外はRAGや通常の検索エンジンを使うといった棲み分けを考えることになります。 - 運用監視と評価
CAGは検索がない分、回答の内容をチェックする手段がRAGとは異なります。
「回答が誤っていた場合に、キャッシュのせいなのか文書選定のせいなのか?」といった監視体制を構築する必要があります。
BERTScoreや他の自動評価指標などを活用しつつ、人間が定期的にサンプリングして検証するなど、適切な運用を心がけたいところです。
このような設計ポイントを押さえれば、検索フリー時代のワークフローをスムーズに構築できるはず。
特に、大規模LLMが標準化された世界では、CAGが「デファクトスタンダード」となる可能性すら感じます。
今はまだ黎明期ということもあり「Don’t Do RAG」がどこまで広まるかは未知数ですが、着実にCAGを受け入れる土壌は出来上がってきているように思えます。
個人的考察
ここでは僕が「RAGからCAGへの移行」について感じることを、もう少し踏み込んで書いてみます。
あくまで個人的な考察なので、あなたの現場の状況に合わせて取捨選択して読んでくださいね。
CAGが登場したことで、検索に頼って知識を補強するという発想そのものを見直すタイミングが来た気がしています。
もちろんRAGには「常に最新の情報を動的に拾える」という大きなメリットもあるので、一方的にRAGを否定するのは早計でしょう。
しかし「検索が全部いいとは限らないよね?」という点は、今回の論文やCAGの実験結果を通じてより広く認識されてきたと思います。
個人的には、これからAI活用が一層進んでいく中で、ユーザー体験やシステム運用の簡便さというのがますます重要視されると考えています。
RAGよりCAGの方が圧倒的にユーザーにとって応答が速くなり、かつ運用者側も管理しやすいなら、その方向に自然と流れていくのが世の常なのではないでしょうか。
では、具体的にどんな疑問や懸念が残るのか。
ここから3つの観点で個人的な所感をまとめてみます。
既存のRAGから完全移行は可能なのか
まず、すでにRAGを導入している企業やプロジェクトがCAGへ移行するのはどの程度簡単なのか。
結論から言えば、場合によるとしか言いようがありません。
- 知識ベースが大きすぎる場合
大規模RAGシステムを運用している企業だと、CAGを導入しようにもコンテキストウィンドウに入り切らないデータが山ほどあるかもしれません。
そうなると、CAGのメリットを享受するには前処理・圧縮が大掛かりになり、結果的にRAGより手間がかかったりする可能性も否定できません。 - 検索が必要なユースケース
最新ニュースやSNSの投稿など、常時更新されるデータソースを扱うケースでは、RAGのリアルタイム検索能力が必須です。
そういった場合、CAG単独で運用するのは難しいので、既存RAGを一部残しつつハイブリッドにするという形が現実的かもしれません。
一方で、RAGで無理やり検索を回していたけど、実はデータ量がそこまで多くないというケースもあるはず。
そういうところは、CAGへ完全移行するとシステムが一気に楽になり、回答精度や応答速度も向上する恩恵が大きいでしょう。
結局のところ、「どれだけの文書量を扱うのか」「更新頻度はどうか」「検索が絶対必要か」といった要件を見極めることが最初のステップですね。
運用コストや開発手順はどう変わるのか
次に気になるのが、CAGの運用コストと開発手順です。
RAGでは検索システムとLLMを組み合わせる複雑さがある一方、CAGではキャッシュ生成という手間が必要になります。
- キャッシュ作成のコスト
多数の文書をまとめてLLMに読み込ませ、KVキャッシュを生成するわけなので、初回の準備フェーズは決して軽くはありません。
ただ、一度作ってしまえば再利用できるという意味で、トータルコストは大幅に下がる可能性があります。 - 開発フローの違い
RAGでは「検索エンジンの導入→索引作成→LLMとの連携テスト→本番リリース」という段階を踏みますが、CAGでは「文書前処理→LLMへの読み込み→キャッシュ生成→推論テスト→リリース」という感じ。
どちらにせよ作業ステップはあるのですが、検索部分の調整やメンテナンスがないだけCAGはシンプルとも言えます。 - 運用面の注意
文書が頻繁に変わる場合は、そのたびにキャッシュを再作成する必要があります。
逆に言えば、頻繁に変わらない文書ならキャッシュ更新の手間がほとんどなく、ある程度固定した知識ベースを運用していく分には相当ラクでしょう。
大まかに見ると、長期的には検索と生成の両方を調整し続けるRAGより、CAGの方がメンテナンスコストが安くなる場面が多いんじゃないかと思います。
特に小規模プロジェクトなら、「キャッシュを作るだけでいいなら楽だな」という印象を持つでしょう。
もっとも、大規模組織であればあるほど、文書管理のプロセスや権限管理、更新フローなども含めて検討が必要です。
CAGはあくまで「LLMに文書を突っ込む」方法なので、オフィシャルな文書が勝手に改ざんされないようなルール作りなど、細かい運用設計をきちんとしておくことは不可欠ですね。
さらなる研究・実装に期待する点
最後に、CAGが今後さらに成熟するうえで期待するポイントを挙げてみます。
- キャッシュ自動更新技術
ユーザーが新たな文書を追加した際、AIが自動で内容を解析してキャッシュの差分更新を行う仕組みがあると最強ですね。
一度生成したキャッシュに部分的なパッチを当てるみたいなイメージで、大掛かりな再計算をせずに済む技術が広がることを期待しています。 - キャッシュ容量の軽量化
KVキャッシュが巨大になりすぎると、それはそれでメモリ負荷が大きい問題も考えられます。
そこで、キャッシュをコンパクトに圧縮しながら、再展開を高速に行うテクニックがもっと進歩するといいですよね。 - ハイブリッドモードの洗練
どうしても検索が必要な領域とCAGを併用する際、シームレスに切り替えられるフレームワークが求められます。
たとえば「まずはCAGでカバーできるところまで回答しつつ、足りない分だけRAGを呼び出す」みたいなダイナミック制御があると便利でしょう。 - 評価指標の多様化
BERTScoreなどで回答の品質を測る手法は一般的ですが、実際のビジネスや現場では回答の正確性だけでなく、文書内のソース引用や一貫性も重視されます。
CAGは検索がないのでソースを特定しづらいかもしれませんが、キャッシュ元の文書URIや該当部分をハイライトする機能などが必要になる場面も多いでしょう。
こうした研究や実装が進むほど、CAGはより実務にフィットした形で普及していくと思います。
「Don’t Do RAG」というフレーズは衝撃的ですが、個人的には「RAGを完全に消し去る」という意味ではなく、新しい選択肢としてCAGをもっと積極的に検討しようというメッセージに近いと捉えています。
総じて、RAGとCAGは互いに補い合う関係であり、その中でCAGが伸びしろを大きく秘めているのが現状ではないでしょうか。
まとめ
- 記事内で登場したRAGの課題と、CAGがそれをどのように解決するかを振り返る
RAGはリアルタイム検索による遅延やエラー、検索と生成のアーキテクチャを統合する複雑さが問題でした。
一方、CAGは事前にすべての文書をLLMに読み込んでキャッシュ化することで、検索ステップを廃止し、それらの課題を大幅に緩和しています。
リアルタイム性や高速応答性が求められるシーンでは、とくにCAGのメリットが光るでしょう。 - 検索に頼らない長文LLMの強みと、KVキャッシュを活用するメリットを再確認
KVキャッシュはLLMが大規模文書を解析した結果を事前保存する仕組みで、推論時は検索なしでクエリと結合して高速回答が可能となります。
さらに、長文LLMのコンテキストウィンドウ拡大が進むほど、CAGの適用範囲は拡大すると考えられ、将来的にはRAGの優位性が少なくなるシナリオも想定されます。 - 今後の大規模言語モデルの進化によって、CAGがどのように幅広い分野で使われるようになるかを展望し、実際の運用や導入のヒントを整理する
CAGは管理可能な文書量をまとめて読み込むなら大きな効果を発揮しますし、システム構成をシンプルに保てるという利点もあります。
大規模LLMのさらなる成長やハードウェア進化と相まって、キャッシュを軸にしたワークフローが当たり前になる時代が来るかもしれません。
一方で検索の必要が完全に消えるわけではなく、RAGとCAGのハイブリッドが最適なケースもあるため、両者の特性を正しく理解したうえで導入を検討することが大切です。
最後まで記事を読んでいただき、ありがとうございました!
