この記事の3行要約
- ChatGPTでの“深掘りリサーチ”手法と、それを活かした自律型AIの作り方を実例つきで解説
- AIに“考えさせる”のではなく、“考え続けさせる”設計こそが、新時代の構文的仕事術だ
- 本記事では、リサーチ構文・プロンプト設計・ツール連携まで、実践型ワークフローを網羅しています
こんにちは、リュウセイです。
ChatGPT活用支援サービスをやっています。
今回は「Deep Research(ディープリサーチ)」という、OpenAIが2025年2月3日にChatGPT Proプラン向けにリリースした自律型AIエージェントについて、ものすごく深掘りしてみます。
「Deep Researchって何?」と思う方も多いでしょう。
なにせ普通のウェブ検索とはまるで違う、まさに“検索の常識を覆す”レベルの新時代ツールなんです。
記事の後半では、僕自身が実際にDeep Researchを使ってみた様子や、調査レポートの所要時間なども含めて紹介します。
そのため一通りの仕組みを理解した上で、実際の使用感をぜひチェックしてみてください。
それではさっそく、今回のメインテーマである「自律型AI『Deep Research』の衝撃」について、導入からガッツリ見ていきましょう!
ちなみに当記事は、Deep Researchを使ってDeep Researchを徹底的に調査させた結果を基に書いています。間違いなくこれからの記事執筆の要になるでしょう。
当記事は、筆者の下書きとChatGPTを合わせて執筆しています。しっかりファクトチェック済みです。
Deep Researchとは何か?

ここではDeep Researchの概要を、できる限り初心者目線で分かりやすく整理していきます。
OpenAIが2025年2月3日に突如として実装したこのDeep Researchは、既存の「ChatGPTのブラウジング機能」とはまったく別物と捉えたほうが良いでしょう。
それはどういう意味なのか。
まず、Deep Researchは「自律型リサーチャー」とも言うべき新モードのAIです。
一般的なウェブ検索だと「キーワードを入力して瞬時に結果を返す→ユーザーがさらに深掘りしたい場合は再度追加で検索」という流れが普通ですよね。
しかしDeep Researchはマルチステップで検索や情報解析を繰り返し、自動で膨大なデータを集め、最後に論文のような詳細レポートをまとめ上げてくれるという機能を持ちます。
つまり、ユーザーが「ざっくり依頼」を出せば、AI自身が必要に応じて検索キーワードを変えたり、途中で資料を読み解いたり、Pythonなどでデータ分析をしたりしながら、最終的に一本の包括的な“リサーチ成果”を提示してくれるんです。
また興味深いのは、検索に要する時間。
通常の検索AIは数秒〜十数秒ほどで回答を生成することが多いですが、Deep Researchは最短5分、長い場合は30分程度かかることもあると言われています。
時間はかかるけれど、その分「人間の調査員が数時間〜数日をかけて行うような本格的リサーチ」をたった一度のクエリで完結させてしまおうというわけですね。
さらに、OpenAIはこのDeep Researchを「汎用人工知能(AGI)への一歩」として位置付けています。
要は“AIが自ら知識を獲得し、統合し、深く考えながら新たなインサイトを生み出す”という世界に近づくための大きな階段だというのです。
言葉だけ見ると夢物語のようですが、既に一部の専門家からは「AGIの入り口を感じる」という声もあり、実際にリリース初期の段階で大きな反響を呼んでいます。
ここからは、そんなDeep Researchがいかに従来の検索AIと異なるのか、そしてなぜ“自律型リサーチャー”という評価を受けているのかを順を追って解説していきます。
従来の検索AIとの違い
従来の検索AI、たとえばチャット形式での簡易ブラウジングをイメージしてみてください。
ChatGPTやBing Chatなどにはすでにウェブ検索機能(ブラウジング機能)が存在し、「最新のニュースを見たい」とか「いま東京は雨かどうか確認したい」といった用途には非常に便利です。
しかしそれらは本質的に1回の検索で取得できる情報が限られており、ユーザーから追加の質問が飛んできた時に再度検索をかけるという、いわば逐次的なやり方しかできません。
もちろん、これでも十分便利です。
ただし以下のような課題がありました。
- 一度の検索では得られる情報がある程度限られる
- もし深いリサーチをしたいなら、ユーザー自身が何度もキーワードを変更しながら検索する必要がある
- 大量の情報をまとめて取得しても、最終的な「包括的レポート」になるまでには人間の手が要る
ここがDeep Researchと決定的に異なる部分。
Deep Researchでは、ユーザーから大まかな「お題」や「ゴール(目的地)」を渡されると、AIが自動で何十ステップもの検索と解析を繰り返し、膨大なサイトを読み込み、必要に応じてPythonでデータを処理し、最終的に長文の調査レポートを作成してくれます。
しかも、出力結果には「どの情報源を参照したか」がしっかり明示されているため、ただ単に「AIが言ってるから正しいんでしょ」ではなく、根拠や出典リンクをユーザー自身が確認できるんです。
引用元のサイトがWikipediaばかりだと心配になるかもしれませんが、少なくとも透明性が保たれているわけですね。
さらに特筆すべきは、ブラウジングという1回の処理の中で「複数のサイト間の対比」や「コードを使ったデータ分析」まで一気にこなす点にあります。
こうした従来の検索AIとの大きな違いをまとめると、「Deep Researchは一度に大量かつ多層的な作業をAIが自ら判断して遂行する」というところに尽きます。
通常の検索のように「即答」を求めるものではなく、時間をかけて“本格調査”をしたい時に力を発揮するイメージでしょう。
“自律型リサーチャー”としての強み
ではなぜDeep Researchが“自律型リサーチャー”と呼ばれるまでに評価されているのか、その強みをもう少し掘り下げましょう。
大きく分けて3つの強みがあります。
- マルチステップで自律的に検索・検証を進められる
単発のクエリではなく、AIが自ら計画を立てて「これだけでは不十分だから別のキーワードを試そう」「データが足りないから追加で別のサイトも巡回しよう」と判断する。
必要なら途中の手順をやり直し(バックトラック)することすらある。 - 多様なツールを統合して使える
Deep Researchにはウェブブラウザ・Python実行環境・画像/PDF解析ツールなどが内蔵されている。
たとえば数字の統計を見つけたら即座にPythonでグラフ化し、その結果を要約してレポートに反映できる。
画像やPDFを解析する場合でも、文字情報を抽出して要点をまとめるなどワンストップで処理可能。 - レポート形式のドキュメントを最終成果物としてまとめる
出力結果は「〜だと思います」といった会話文ではなく、きっちり構成された長文ドキュメントであることが多い。
参照元URLや参照元文献を添付するだけでなく、調査の過程で得られた知見を論理的につなげた分析レポートを作成。
つまりユーザーにしてみれば、「調査結果を結論だけでなくプロセスや根拠付きで知る」ことができるのがありがたい。
さらに細かい話をすると、Deep Researchの内部モデルは「o3」モデルと呼ばれる次世代の大規模言語モデルをベースにしているらしく、強化学習(RL)によって複雑なタスクをこなせるよう訓練されているようです。
これは「与えられたゴールを達成するために、どんなステップを踏めばいいか」というアクションを自律的に学習する仕組みだと言われています。
例えば、難しい質問を受けたときに「1回の検索では解決できないから、複数の資料を横断する必要がある」と判断すれば、それをAIの判断で連続的に実行するわけですね。
しかも行動ステップごとに適切な報酬を与えることで、次第により良いリサーチ戦略を獲得していく。
そこが従来の「人間が都度プロンプトを工夫して指示しなければならないChatGPT」とは大きく違う点です。
こうして見ると、Deep Researchはまさに「AIが自発的に調べ、考え、まとめる」というイメージに近い存在です。
もちろん実際にはまだ完璧ではなく、誤情報を混ぜる(幻覚を起こす)こともある程度は残っていますが、OpenAI曰く普通のChatGPTより誤情報は減っているとのこと。
総合すると、Deep Researchは“自律型リサーチャー”としての強みを下記のようにまとめられます。
- ユーザーがざっくり依頼→あとは全自動で検索と分析を繰り返してくれる
- コード実行や多様なファイルの解析など、幅広いツールを1つの仕組みで活用
- 最終的に論文のようなドキュメントとして成果を提示し、引用元のリンクも明示
これらはAIが一気に高い次元の検索を担う時代の幕開け、と言えるでしょう。
Deep Researchの主な機能と特徴

ここからは、Deep Researchが具体的にどのような機能を提供しているか、そしてそれぞれがどんな特徴を持つのかを解説します。
前章で述べたように、Deep Researchは単なるブラウザ検索ではなく、「ウェブ検索+データ解析+レポート生成」を丸ごと自動化するのがポイント。
しかも、AIが自律的に複数ステップを踏んで情報を集めるという点が肝です。
OpenAIによる公式な機能概要は以下のようにまとめられています(専門家向けの用語も多いので、ここではできるだけ噛み砕いて紹介しますね)。
マルチステップのリサーチフロー
最大のキーワードが「マルチステップ」です。
つまり、Deep Researchはユーザーからのプロンプトを受け取ったら、その内容をもとに「どんな手順を踏めば答えにたどり着けるか」をAI自身が計画します。
この計画を「プランニング」と呼びますが、具体的には下記のような流れを辿ることが多いと言われています。
- ゴールの把握と事前ヒアリング
何を調べたいのか? どんな成果を期待しているのか? 画像やPDF資料はあるか?
必要ならユーザーに追加で「もう少し焦点を絞ってほしい」と聞いてくる場合もある。 - 検索クエリの作成とウェブアクセス
ユーザーが指示していなくても、AIが「このキーワードが必要そうだ」と判断したら追加で検索をかける。
例えば「市場規模を知りたい」場合、「グローバルマーケットレポート」など関連性のあるキーワードを連続的に試すイメージ。 - 文書・画像・PDFの解析
見つかったデータソースを読み込み、必要なテキスト情報や数値を抽出する。
PDFの場合でも内蔵されたPDF解析ツールで読み込めるので、ユーザーがいちいちPDFをテキスト化する必要はない。
必要に応じて画像から文字や図表データを抽出することもある。 - コードによるデータ分析(Python実行環境)
統計データや表計算を扱う際、Pythonスクリプトを自動生成して実行する。
グラフを作ったり数値の相関関係を解析したりするなど、人間が表計算ソフトで行うような作業をAIが担う。 - 情報の要約・比較検討
集めてきた複数のサイトや文献を突き合わせて、「共通点」「差異」「相反する情報がある場合の整合性」などをAIが考察。
必要とあらば「この部分は不明瞭」と注釈を付けることもある。 - 最終レポートの生成
AIが自らまとめた結論や考察をドキュメント形式で出力。
引用元リンクを挿入し、ユーザーがその根拠をたどりやすい形に仕上げる。
数字情報やグラフの結果も含め、論理構成に沿った“読み物”として完成。
これらがすべて自動化されているという点が、Deep Researchの強烈な特徴です。
仮にユーザーが一切口出しせずとも、AIだけで複雑な調査をやり切れる仕掛けが整っているわけですね。
ただし、このマルチステップ処理は当然ながら高い計算リソースを消費します。
そのため、回答が仕上がるまでに5〜30分程度は待つ必要があるのが普通。
待っている間はチャット画面のサイドバーで「どんなサイトを訪問しているか」や「何を考えているか」がリアルタイムに表示されるという点も、従来の検索AIとは違う部分です。
マルチモーダル対応(PDFや画像解析など)
Deep Researchの強みはウェブ文章だけに依存しない点にもあります。
具体的にはPDFや画像など、テキスト以外の形式も解析対象として扱えるのです。
たとえば、研究論文のPDFをいくつかアップロードし、まとめて分析してもらうことが可能。
これまでは「PDFの文章をコピーしてテキスト化して…」といった面倒な工程を踏む必要がありましたが、Deep ResearchではAIが裏側でPDF解析ツールを使い、文章や図表データを抽出してくれます。
さらに画像ファイル内に埋め込まれたテキスト情報(たとえばスクショの文字情報など)もAIが読み取れるため、ウェブ上にはテキストとして存在しない情報までリサーチが広がるわけです。
また、Python実行環境との組み合わせがあることで、画像のメタデータを解析したり、OCR(文字認識)で抽出した結果を統計的に処理したりもできる。
もちろん、すべてが完璧にこなせるわけではなく「このフォーマットだとまだ解析精度が低い」「画像内の文字が小さすぎて認識できない」などの制限はあるものの、多様なメディアを扱うポテンシャルは非常に高いと評価されています。
特に、学術研究や法務分野で役立つでしょう。
大量のスキャンPDFや画像資料を読み込ませて、一度に整理してもらうだけでも、従来の方法に比べれば画期的な作業効率アップが見込めるわけです。
さらにOpenAIのロードマップでは「数週間以内に視覚要素(図表やグラフなど)をレポート内に埋め込めるようにする」アップデートが予定されているとされています。
これはつまり、Deep Researchが分析結果をグラフや可視化としても提示できるようになり、文章だけでなくビジュアル資料まで包含した“調査報告書”をAIが自動生成する時代が近いということです。
こうしたマルチモーダル対応こそが、Deep Researchの強烈な武器の一つ。
テキストのみの世界に閉じこもらず、あらゆる形式の情報を取り込んで1つのレポートにまとめ上げるという将来像は、大いに期待と注目を集めているポイントです。
Python実行環境でのデータ分析
もう一つ大きな特徴がPython実行環境です。
OpenAIは以前から「Code Interpreter」や「Advanced Data Analysis」という形で、ChatGPTにPythonを実行させる機能を実装していましたが、Deep Researchはその機能をさらに強化・統合しているイメージです。
具体的には、Deep Researchがウェブ上やPDFなどから収集した数値データや統計情報を、必要に応じてリアルタイムでPythonコードを走らせながら分析・グラフ生成してくれます。
たとえば市場規模の推移データが表になっていた場合、AIがそのデータをPythonスクリプトに食わせて「折れ線グラフ」を描画し、そこから得られた傾向を自動的に要約してレポートに組み込むわけです。
従来であれば、人間がExcelやプログラミングを使って手動で解析し、結果を見ながらまとめる必要がありました。
しかしDeep Researchは一連の作業を完全に自動化できる可能性が高い。
要するに、ユーザーが「こんな角度からデータを見てほしい」と細かく指示しなくても、AIが自律的に統計分析を行い、「ここはトレンドが顕著ですね」「この部分に相反するデータがあるので要追加検証」といった考察ポイントをレポートに盛り込むことまでやってのけるのです。
これが本当に上手く機能すれば、ビジネスインテリジェンス(BI)領域での応用は計り知れません。
実際、一部のユーザーからは「競合分析にDeep Researchを使ったら、人間のアナリストが数日かける仕事が数時間で済んだ」という報告もあります。
ただし現時点ではPythonツールの利用や外部ライブラリの扱いに制限があり、非常に高度な分析になるとまだ一部対応が難しいケースもあるそうです。
それでも、検索AIとプログラミングツールがシームレスに連携するという仕組みが広く普及すれば、データサイエンティストやアナリストの働き方を大きく変革しうるでしょう。
AIが膨大な情報源をめぐりながら、必要に応じてコードを実行し、得られた洞察をまとめてくれる――これこそDeep Researchが持つ最大の魅力かもしれません。
Deep Researchの利用方法

続いては実際にどうやってDeep Researchを使うのかをまとめます。
「AIがすごいのは分かったけど、ユーザーはどんな操作をするの?」という疑問を持つ方も多いと思うので、UIのイメージや提供プランなどと併せて説明していきます。
事前設定
Deep ResearchはChatGPTのUIから利用できます。
ただし、リリースされた2025年2月3日時点では「ChatGPT Pro」プラン(月額200ドル)のユーザー限定でこの機能が解放されているので注意しましょう。
【アップデート速報】2025年2月26日にPlusユーザー等にも解禁されました。
具体的な操作の流れを簡単にまとめると
- ChatGPTにアクセスし、ログインする
ProプランでなければDeep Researchのオプションがそもそも表示されない。
地域によってはまだ使えない場合(英国・スイス・EEA圏など)もある。 - 適当なモデルを選択し、入力ボックスにある
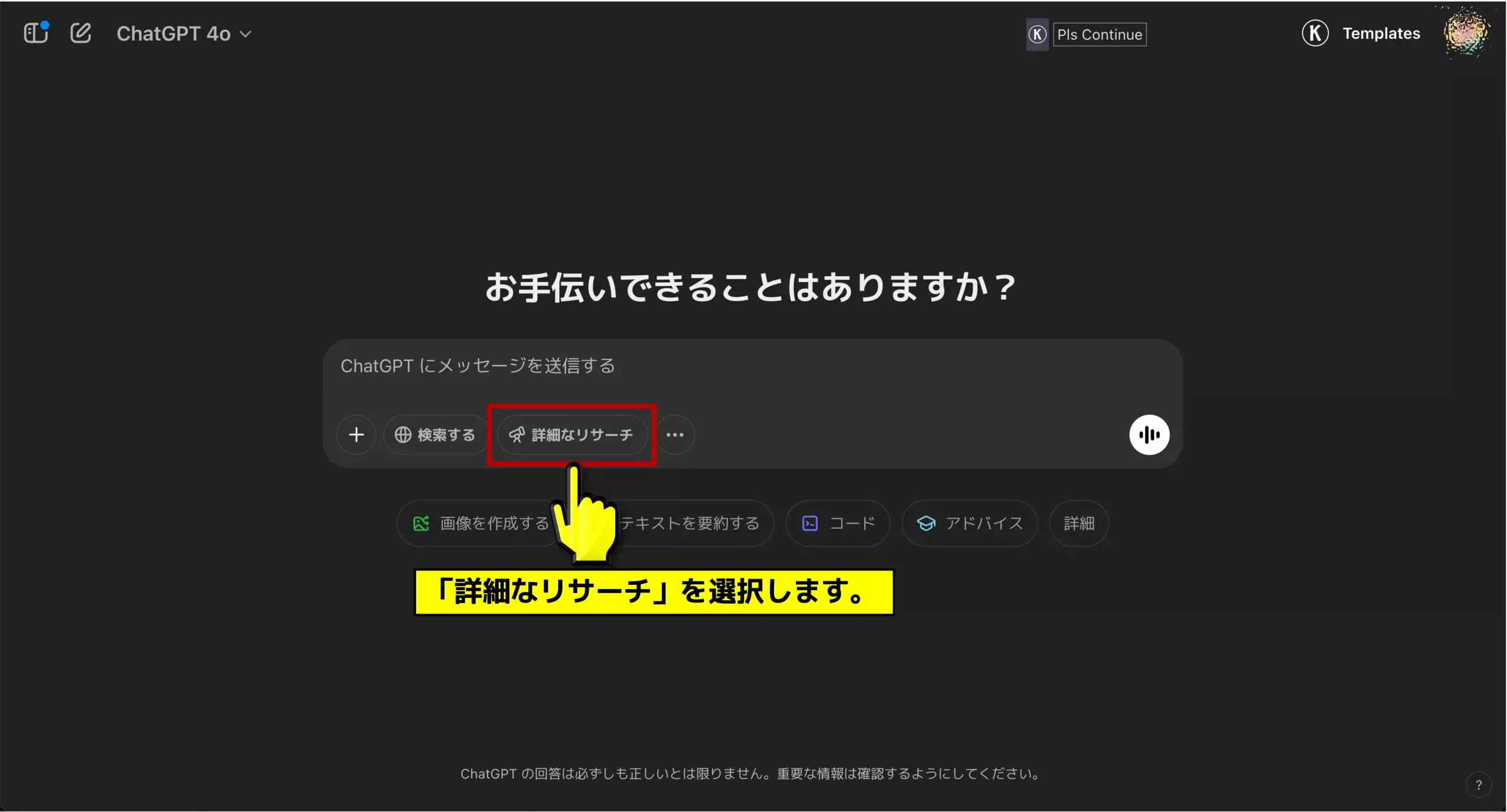
詳細なリサーチボタンを押す
何でも良いのでモデルを選択すると、プロンプトを書いている入力ボックスに「詳細なリサーチ」というボタンが表示されている(UIは時期によって変更の可能性あり)。
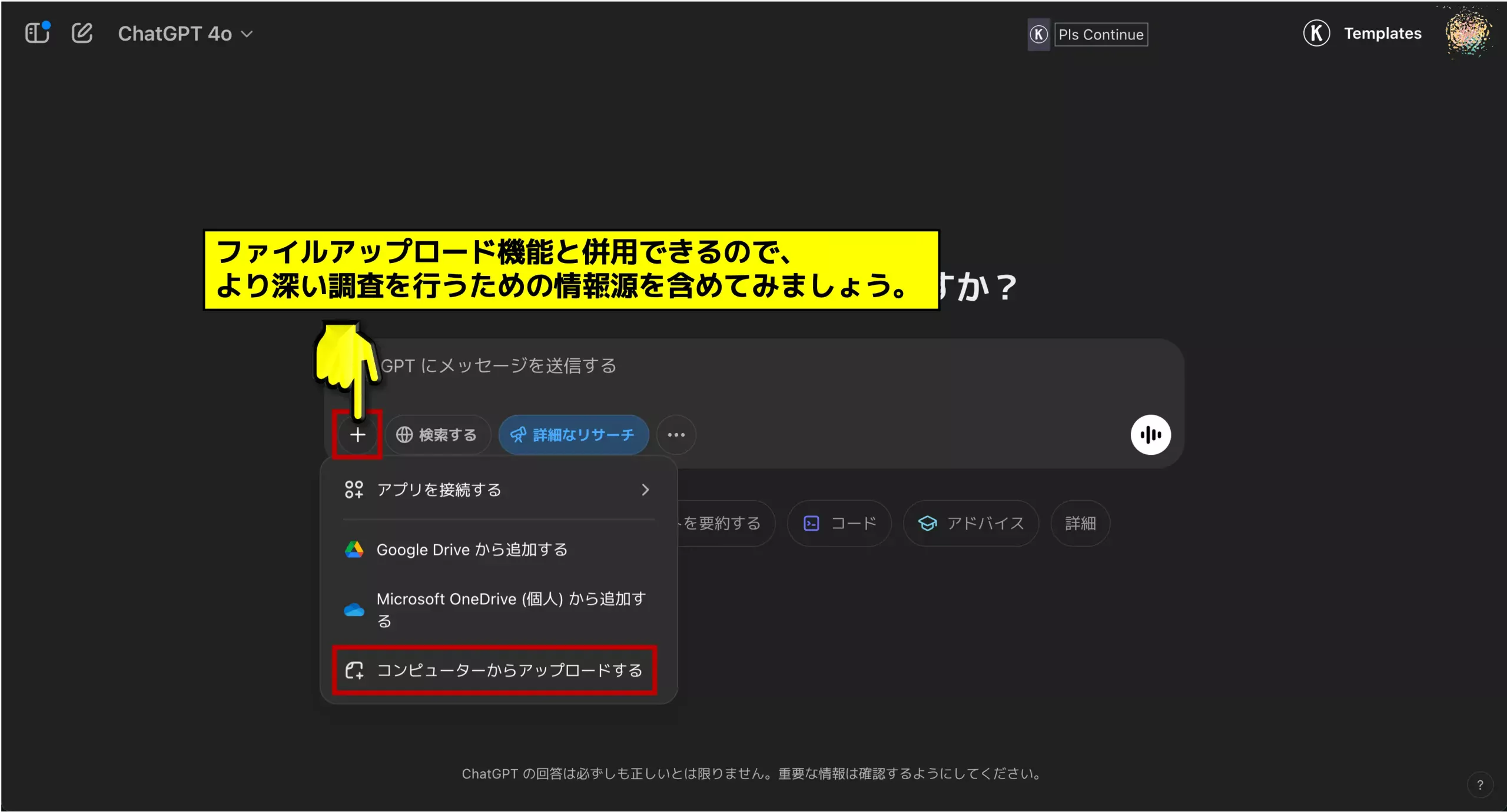
現状ではどのモデルを選んでもDeep Researchを使えるが、将来的にどうなるかは不明(o1-pro-modeでも選択できるが動作はしない)。 - 質問(プロンプト)や参照資料をアップロード
例えばPDFや画像ファイルを添付すると、Deep Researchがそれらを解析対象に含めてくれる。
質問が複雑な場合は、Deep Research側が追加ヒアリングのフォームを出してくることもある。 - 調査がスタートし、サイドバーなどで進捗を監視できる
5~30分程度かかるのが一般的。
ChatGPT画面で調査終了を待ち、完了すると長文レポートが投稿される。
なお、アップロードできるファイル形式やサイズには制限があるため、あまりにも巨大なPDFや大量の画像を投げ込むとエラーになることも。
また、依頼内容によっては調査時間が激増する可能性もあるため、ChatGPTのように即座に答えが返ってくるわけではない点に留意が必要です。
実行からレポート生成までの流れ
Deep Researchを選択し、質問を投げて実行ボタンを押すと、しばらくの間はAIが裏側でリサーチ作業をします。
この間、通常のChatGPTのような即時応答はありません。
ユーザーは「進捗バー」や「サイドバー上のメッセージ」で、AIがどんな段階にいるかを把握できる仕組みになっています。
例えば、「今は関連文献を検索中です」「次に取得したデータをPythonで分析しています」といったステータスがリアルタイムに更新される。
こうした経過を眺めながら、「こんなに時間かかるなら途中でキャンセルしようかな…」といった判断をすることも可能です。
一般的な所要時間は5分〜30分程度。
軽めのリサーチなら数分で済む場合もありますが、複雑なテーマを投げると想像以上に時間がかかるケースがあります。
なにせAIが数十サイトを自動巡回し、さらにPython分析やPDF解読まで行うわけですから、処理量が膨大になるのも頷けます。
調査が完了すると、ChatGPTの画面にレポートが投稿されます。
これは単なる会話形式の文章ではなく、セクション見出しや箇条書き、表組み、引用リンクなどを含んだ“長文ドキュメント”のスタイルです。
中には1万文字以上の大ボリュームになったという報告もあるくらいで、ユーザーとしては下調べの手間が大幅に減る可能性があるでしょう。
ただし、このレポートにはあくまでAIが収集・解釈した情報が詰め込まれているので、100%鵜呑みにするのは危険。
公式にも「引用元を自身で検証することが推奨される」と記載があります。
要は、Deep Researchによって“初期ドラフト”的なリサーチ資料を一気に作ってもらい、最終的な検証や微調整は人間が行う、という使い方が理想的でしょう。
提供プランと対応地域
前述のように、Deep Researchはリリースされた2025年2月3日時点で「ChatGPT Pro」(月額200ドル)のユーザーしか利用できません。
【アップデート速報】2025年2月26日にPlusユーザー等にも解禁されました。
月100回 → 月120回までDeep Researchのクエリを実行可能という上限も付いています。
今後は、ChatGPT PlusやTeam、Enterpriseプランにも段階的に開放される予定とのこと。
ただ、地域制限があるようで、イギリスやスイス、EEA圏(欧州経済領域)のユーザーは現状は対象外になっているとも言われています。
この地域制限は法律やデータ保護の問題が影響している可能性があり、OpenAIが順次クリアにしていく計画があるそうです。
また、提供形態としては当面「Web版のChatGPT」での利用が中心ですが、公式コミュニティの発表によると「モバイルアプリやデスクトップアプリでも対応予定」とされています。
つまり将来的にはスマホからDeep Researchにアクセスし、ちょっとしたテーマでもすぐに高度なリサーチをかけられるようになるかもしれません。
一方、現在の200ドル/月という価格設定は「高い」という批判も少なくありません。
特に一般ユーザーや個人事業主にとっては簡単に手を出せる金額ではないので、このあたりの価格改定や無料トライアルの導入などが行われる可能性もあります。
いずれにせよ、Deep Researchが広く普及するにはコスト面と地域展開の2つが大きな課題と言えるでしょう。
Deep Researchに使われている高度な技術のポイント

ここまでで、Deep Researchがどういったプロセスで情報を収集・分析し、そして長大なレポートを出力できるのかをお話ししてきました。
では具体的に、その裏側にある技術的なエンジンはどのような仕組みになっているのでしょうか。
ここからは少し専門的な話にも触れつつ、初心者でも概念をイメージしやすいよう噛み砕いて解説していきます。
Deep Researchの技術的要点は、大きく分けて3つに整理できます。
- 「o3」モデルと強化学習(RL)による自律推論
- 出典リンクと引用管理の仕組み
- 幻覚(誤情報)を減らすための工夫
特に1の強化学習は、Deep Researchという“自律型”リサーチャーを成立させるための核心部分とされています。
また、2の出典リンク管理は、AIが参照元を明示するうえでの技術的工夫が凝らされており、誤情報や不透明な引用問題を少しでも緩和するための仕掛けでもあります。
そして3の幻覚抑制は、従来のChatGPTから大きく進化したポイントの一つであり、特に複雑なリサーチにおいて「あれ、AIがデタラメを言ってるんじゃないか?」という不安を減らすための改良が行われていると言われています。
それでは順を追って見ていきましょう。
「o3」モデルと強化学習による自律推論
「o3」モデルとは、OpenAIがGPT-4に続く次世代の大規模言語モデルとして開発した「o1」の進化系として位置付けられています。
o1自体は、従来のGPTシリーズ(GPT-3.5やGPT-4など)に比べて特にツール操作やマルチステップ推論を得意とするように設計されているので、それを強化したのが次期o3ですね。
Deep Researchは、このo3モデルを強化学習(RL:Reinforcement Learning)で追加チューニングした上で、“エージェントフレームワーク”と組み合わせて動いていると公表されています。
従来のChatGPTは主に「単発の文章生成」を想定した学習をメインにしていたのに対し、このDeep Researchに搭載されているAI(o3)は「複数のツールを呼び出しつつ、複数ステップにわたる目標をクリアしていく」行動指針を学習しているというわけです。
強化学習で何が変わるのか?
強化学習をざっくり言うと、「AIがある環境(ここではインターネットやPythonなどのツール群)で一連の行動を行い、その結果によって報酬を与えて性能を向上させる」という学習手法です。
具体的には、下記のような流れで行われると言われています。
- タスクを与えられたAIが、まず自分で検索クエリを考案してみる。
- 結果として得られた情報を解析し、その情報がどの程度タスクの達成に貢献したかを評価。
- 良い行動(有益な検索キーワードを発行した、正確なデータを扱った等)は報酬を得る。無駄な行動や誤情報につながる行動は報酬を得られない(時には負の報酬)。
- 報酬を最大化するように試行錯誤を繰り返し、やがてタスク達成への行動パターンをAIが自律的に身につける。
この過程を数多く繰り返すことで、AIは「例えば市場分析ならまずどんなデータにあたるべきか」「研究論文をクロールするときにどういうサイトを優先すべきか」を自力で学んでいくわけです。
さらにPythonを使った統計分析やPDF解析などのステップについても、「状況によってどんなツールを呼び出せば報酬が高まるか」を学習し、上手い連携を取れるようになります。
これが従来のChatGPTには見られなかった自律性をもたらし、Deep Researchとしての大きなアドバンテージになっているのです。
エージェントフレームワークとの組み合わせ
Deep Researchが採用しているアーキテクチャは、いわゆる「LLM + ツール呼び出し」を超えた形態です。
単に「AIにブラウザ検索させる」だけではなく、AIが自分で考えながらツールを連続的に呼び出すという意味合いで、しばしば「エージェントAI」と呼ばれます。
これはAuto-GPTやLangChainといったオープンソース界隈でも話題になった仕組みですが、Deep ResearchはOpenAI公式の大規模学習を経て磨き上げられた形になっているという点が強みでしょう。
具体的には、Deep Research内部で次のようなやり取りが起きていると推測されます。
- 設定された目標を踏まえ、AIが「今はウェブ検索を使おう」と決断
- 得られた検索結果を読みながら、「不足情報がありそうだから、次はPDF解析ツールを呼び出そう」と判断
- PDF解析から数値データが得られたら、続けてPython実行環境で統計処理をする
- それらを総合して記事を書き上げる上で、「ここは追加で異なるキーワード検索が必要だ」と再度ブラウザツールを呼ぶ
…といった具合で、必要に応じてステップが何度も行き来する。
この柔軟さと自主性こそが、“深いリサーチ”を成し遂げるための仕掛けです。
そしてこれを強化学習で訓練することで、ただ単にユーザーの指示をなぞるだけではなく、AIが状況に応じて最適解を探る行動を獲得したと言われています。
出典リンクと引用管理の仕組み
続いて、Deep Researchの出典リンク・引用管理について見ていきましょう。
従来の検索AIやチャットボットでも、ある程度「参考URL」を提示する仕組みはありましたが、Deep Researchでは「参照元の表示」と「引用箇所の紐付け」がさらに強化されていると言われています。
1. 情報ソースの多層集約
Deep Researchは1回の調査フローで数十〜数百の情報ソースを巡回する可能性があります。
その中で、
- ウェブサイトの主要コンテンツ
- PDFドキュメント内の該当箇所
- 画像解析から抽出したテキスト
などをすべてAIが読み込み、必要な部分をレポートに反映していきます。
そしてレポートの各節ごとに「この節は○○というサイトからの情報をまとめました」といった形で引用元が記載され、リンクをクリックすればユーザーはそのソース元を直接確認できる仕組みになっているわけです。
これにより、「AIがどこから話を引っ張ってきたのか分からない」という不透明感を少しでも減らすことができますし、誤情報が混入した場合でも検証しやすい利点が生まれます。
2. 自律型エージェントの思考過程ログ
もう一つ面白いのは、調査中のサイドバーなどに「AIが今どのサイトを閲覧しているか」「どういうキーワードで再検索しているか」といったプロセスが表示される点です。
OpenAIは「透明性の確保」としてこの仕組みを導入しているらしく、「AIが裏側で何を考えているのか」を一定レベルで可視化しているようです。
ただしこの思考過程ログには、AI自身の中で交わされる詳細な計画がすべて書かれているわけではないとされ、内部の解析までは全てが公開されているわけではありません。
それでも、少なくともどのサイトや文献を訪れているかは大まかに分かるため、ユーザーが理解を深めるうえで助けになるでしょう。
3. 引用の正確性と今後の課題
とはいえ、すべての引用リンクが100%完璧に一致するわけではなく、ときにAIがリンク先を誤記しているケースもあるようです。
ユーザーの試用事例でも「リンクを踏んだら該当文章が見当たらない」という報告があり、OpenAIも現時点で「Deep Researchが完全無欠ではない」と認めています。
今後は、「引用先のテキストをハイライト表示する」など、さらにユーザーが検証しやすい仕組みを充実させる計画があるとの見方もあります。
要は、AIが出典を示すだけでなく、「具体的にどの一文や段落を引用したのか」を明示できれば、さらに信頼度が上がるわけですね。
出典リンク機能は、Deep Researchの大きな特色かつ強みですが、まだ発展途上でもあるということを理解しておく必要があるでしょう。
幻覚(誤情報)を減らす工夫
この章の最後に、Deep Researchが行っている幻覚(Hallucination)対策について見ていきます。
ChatGPTなどの大型言語モデルは、以前から「それらしく書くけど実は事実ではない」という誤情報を平然と生成してしまう問題が指摘されてきました。
1. 幻覚の原因
幻覚が起きる主な原因は、AIが文脈上“それっぽい回答”を作り出すために推測を混ぜ込んでしまうことです。
特に信頼性の低い情報ソースを読み込んだときに、情報の真偽を十分評価できずにそのままレポートに載せてしまうという危険もあります。
また、英語圏以外の言語やマイナーな話題の場合には、参照できる信頼性の高いデータが少ないために、推測ベースの文章を生成しがちという傾向もあるようです。
この点はDeep Researchでも完全には解決できていないのが現状です。
2. Deep Researchの対策
OpenAIは、この誤情報問題に対して以下のような取り組みを実装していると言われています。
- (A) マルチソース参照と照合
同じ話題について複数のウェブサイトや文献を参照し、相互に照合して矛盾がないかチェックする。
もし大きく食い違うデータが出てきた場合は「どちらが正しいか分からない」と注釈するように学習させている。 - (B) 出典リンクの明示によるユーザー検証支援
ユーザー自身が「この情報は本当に正しいの?」と疑問を感じたときに、引用リンクを辿って確認できる仕組みを整備。
AIの回答をうのみにせず、人間が裏取りをするハードルを下げている。 - (C) 不確実性表現の強化
Deep Researchは回答時に「〜かもしれません」「〜である可能性が高いです」など、不確実性を表現する度合いをやや高めに設定しているとの声もある。
従来モデルに比べて断定的な言い回しを減らすことで、ユーザーが過信しないように促す狙いがある。 - (D) 強化学習を活用した検索ソースの信頼評価
どの情報源を優先して参照するかを、学習プロセスの中で信頼度の高いサイトを優先するよう調整している可能性が高い(詳細は非公開)。
少なくとも明らかに怪しいフォーラムなどはスコアが低く設定されると推測される。
3. まだまだ課題は残る
とはいえ、実際に使ったユーザーからは「誤情報を混ぜ込むことは依然としてある」というフィードバックが出ています。
出典リンクを貼ってはいても、中にはリンク先が実は全然違う内容だったり、文献を正しく理解していなかったりするケースもあるとのこと。
要するに、Deep Researchが幻覚をゼロにできているわけではなく、あくまで以前より改善された程度に留まります。
結局は「AIの提出する情報を人間が検証する」というステップが、まだまだ重要だということです。
将来的には、より高度な確率推定や信頼性スコアの可視化などが進んで、幻覚の問題がさらに軽減されるかもしれませんが、現段階では「完全には解決されていない」という認識で使うのが無難でしょう。
Deep Researchのユーザーからの評価と懸念点

Deep Researchは2025年2月3日のリリース直後から大きな話題となり、専門家や一般ユーザーのあいだで“驚き”と“懸念”が同居する状況になっています。
ここでは主なユーザーの反応を、ポジティブとネガティブの両面から整理し、さらに料金面での不満についても触れてみましょう。
称賛の声:リサーチ効率の大幅向上
多くのユーザーが驚いているポイントとして、「従来数時間かかる調査を数十分で終わらせてしまう」というパワフルさがあります。
- 研究者や学術系ユーザー
「文献レビューを1回のDeep Research実行でだいたい網羅してくれるため、論文執筆の下調べが桁違いに楽になった」という声がある。
特に英語文献が多い領域ではAIが英語サイトを横断的に読んでくれるので、言語の壁もある程度緩和されるというメリットが指摘されている。 - ビジネスアナリストやコンサルタント
競合分析や市場調査、特許侵害リスクのチェックなど、複雑なデータを扱う業務で「人間が何日もかけていた作業の初期ドラフトを、数時間以内に仕上げられる」と評判。
もちろん最終的には専門家が確認する必要があるが、「下準備」にかかるコストと時間が大幅に削減されるのは大きい。 - 一般ユーザーでも“やり込む”人
ショッピングや大きな買い物(車・家電など)の比較検討にDeep Researchを使うことで、多数のレビューサイトやスペック一覧を横断的にまとめてくれると評価するケースがある。
「自分で十数サイトを見て回る手間が丸々省ける」と喜ぶ声も。
ただし、そもそもそれほど徹底した検索を行わないライト層は、これほどの機能は必要ないかもしれないという意見もある。
こうした称賛は総じて「AGIの片鱗を感じる」「AIがここまで自律的にまとめてくれるとは想像以上」という興奮を伴って語られることが多いです。
特に1万文字以上のレポートが一発で返ってきたときなど、多くのユーザーは驚愕するようです。
批判的意見:ソースの信頼性と現実的な活用
一方、Deep Researchのリサーチ内容を見て「結局ソースの信頼性はAI任せか?」という懐疑が根強くあります。
AIがたまたまアクセスしやすかったサイト(例えばWikipediaや個人ブログなど)に偏ってしまい、玉石混交のデータをまとめてしまうリスクもあるわけです。
- 「あまりにも膨大な内容を吐き出すため、ユーザーが逆に検証に時間を取られるのではないか」という声
深く調べたい人にとっては良いが、一から全部リンクを踏んで確かめる時間があるなら最初から手動でやっても同じ? と皮肉るユーザーもいる。
ただし、少なくともAIが要約しているために網羅性が高いという点を評価する意見もあり、賛否両論。 - スキー板のオススメのような「そこまで徹底調査したくない商品」への活用は現実的か
一部のユーザーは、「大枚はたいてDeep Researchに依頼して、大量の引用リンク付きレポートを読んでまでスキー板を選びたいか?」と疑問を呈する。
これは要するに使いどころが限定されるという意見とも言える。 - 誤情報混入(幻覚)のリスクは完全には消えていない
先ほど紹介した幻覚抑制の工夫はあれど、実際に使ってみると「全体的には素晴らしいが、細部でミスが散見される」という報告も散見される。
特に最新のニュースや専門家がまだ議論中の領域では、AIが複数の情報源をうまく取捨選択できず、中途半端な形で結論を出すケースがある。
こうした批判や懸念は、「Deep Researchが万能のリサーチエンジンとは言い切れない」ことを示唆しています。
結局、AIが準備してくれたレポートはすごく便利だけれど、最終的な信用判断や意思決定は人間が慎重に行う必要があるというわけですね。
月額200ドルのPro限定への不満
さらに、ユーザーコミュニティやSNSでは「月額200ドルのPro版限定」という料金設定が度々批判の的になっています。
- 個人ユーザーには手が届きにくい
月200ドルは年間換算で2,400ドル(日本円で30万円以上)になるわけです。
企業や大きなプロジェクトで使うには納得の面もあるかもしれませんが、個人利用者や小規模事業者にはかなりの負担になる。 - Proプランを契約したのに一部地域で使えない問題
英国・スイス・EEA圏のユーザーは現時点でDeep Researchにアクセスできないという話もある。
「契約しているのに機能が制限されている」という不満が出るのも当然といえば当然。 - 今後、さらに高額プランが出るのではという不安
一部ユーザーは「これが標準化されたら、さらに強化版のDeep Research 2.0が月500ドルや1,000ドルになるのでは?」と疑念を抱いている。
つまりOpenAIが“高機能=高額”の路線で突き進むなら、ユーザー層が限定されてしまうのではという懸念だ。
【追記】Plusプラン等でも月10回まで使えるようになったので、ハードルは下がりましたね。
OpenAI自身は「いずれはChatGPT PlusやTeamなどにも段階的に開放する」と言及していますが、具体的な時期や値下げの見通しは明らかになっていません。
現状では早期アクセスに相応のコストを求めているとも見られ、一般ユーザーへ広く普及するかどうかは今後の料金体系次第と言えるでしょう。
Deep Researchの活用事例と想定ユースケース

Deep Researchは汎用的なリサーチ支援AIとして設計されているため、ビジネス・学術・日常など幅広い分野での活用が期待されています。
ここでは具体的な事例やユースケースをいくつか紹介しながら、どのように便利なのかを考えてみましょう。
ビジネスインテリジェンスや競合分析
企業やコンサルティングファームなどでは、市場動向の分析、競合製品の比較、特許侵害リスクのチェック、顧客嗜好の調査などに膨大な時間を費やすケースが多々あります。
そこにDeep Researchを導入すれば、以下のようなメリットがあると考えられます。
- 市場規模や成長率、主要プレイヤーの動向などを網羅的に取得し、それらをグラフや表で可視化した包括レポートを自動生成。
- 競合企業のウェブサイトや公開資料、メディア記事などを横断し、製品スペックや価格戦略を比較。
- 法律や規制面の情報を確認して、新規事業で懸念される法的問題を早期に発見(例えばEUのGDPR対応が必要かどうか、など)。
企業にとっては、人間のアナリストが数日かける初期調査を大幅に短縮できるインパクトがあります。
また、「抜け漏れ」が少ないという利点も大きいです。
AIが決められた範囲内で片っ端から情報を拾ってきてくれるので、たとえ人間のアナリストが疲れや時間の都合で見落としがあったとしても、Deep Researchなら比較的網羅的に調べてくれます。
実例:製薬会社のケース
ある製薬企業が“新薬候補のスクリーニング”を試験的にDeep Researchに任せたところ、通常はチームが数週間かける作業をわずか数時間で終え、10種類の有望化合物候補を抽出できたという事例が報じられています。
もちろん最終チェックは人間が行ったものの、調べ物の初期段階を機械に任せたことで、専門家はその後の詳細分析に集中できたわけです。
学術研究・技術開発への応用
研究者やエンジニアの世界では、論文・特許・技術文書の大量読解が日常茶飯事。
Deep Researchはこれらの資料収集や要約作業を強力にサポートします。
- 学術分野
文献レビュー(関連研究の整理)を自動化し、新しい研究テーマに着手する際の下調べを短縮。
PDF形式の論文をまとめてアップロードし、Deep Researchに「このテーマに関する重要な発見や未解決の課題を教えて」と依頼すれば、AIが複数の論文を横断して要点を報告書にしてくれる。 - 工学・エンジニアリング
新しい技術基準やISO規格などを大量に参照しなければならないときにもDeep Researchが有用。
例えば回路設計の例で、「○○という素子の採用事例を海外の専門サイトから拾ってきて比較してほしい」「データシートPDFを読んでパラメータ差をまとめてほしい」といった使い方が可能。
Python実行環境と連携すれば、簡単なシミュレーションや数値計算もセットで行えるため、より深い技術検討が一度に進む。
文献レビューの例
たとえば言語学や化学などの分野で、新しいテーマを研究したいときに過去の先行研究をざっくりと網羅したいケースがありますよね。
従来なら、いくつもの学術データベースを走り回って論文をダウンロードし、それらを読み込むだけで何日もかかる……というのが普通でした。
ところがDeep Researchなら「2024年10月1日までに公開された論文や特許情報を検索し、○○という仮説に関するデータを要約してほしい」と依頼すれば、AIが公的論文データベースや各種プリントサーバ等を巡回して重要論文を列挙し、主要な結論点までまとめてくれる可能性があるわけです。
もちろん細部まで間違いなくまとめられるかは別の問題ですが、全体像を把握する下準備としては非常に有効でしょう。
日常生活での大きな買い物や意思決定
実はDeep Researchは、OpenAIが公式に「目の肥えたショッピング客」もターゲットユーザーに含めていると公表しており、高額商品や複雑な比較検討が必要なシーンに対応する意図があるそうです。
- 車を買うときの比較
複数の車種を跨いでスペック・燃費・ユーザーレビューを収集し、メリット・デメリットを表形式にまとめてくれる。
ユーザーがYouTubeレビュー動画まで見る手間をAIが肩代わり、要点を文字起こししてレポート化してくれる場合もある。 - 家電や家具の購入
海外サイトや個人ブログなど、点在する口コミ情報を一度にかき集めて、どの機種がどう評価されているかを一覧化。
ネット上に散らばる「隠れた評判」を発見してくれることがあるため、見落とし防止の意味でも嬉しい。 - 住宅探しや保険商品の比較
不動産情報サイト・保険比較サイトのデータを横断的に収集し、価格や条件など複雑な指標でランキング。
ただし地域や法律に関する制約が絡むと誤情報リスクが高まる可能性がある。
とはいえ、正直なところそこまで徹底した分析を要しないシーンでは、Deep Researchはオーバースペックかもしれません。
たとえば「来週の天気を知りたい」程度の用途なら、即時検索のほうが速いですし、報告書が5,000文字も出てきても邪魔になるだけです。
ただ、「数十万〜数百万円単位の買い物で後悔したくない」というケースなら、Deep Researchが提示する詳細レポートは非常に役立つ可能性があります。
複数のサイトを繰り返し閲覧する時間や精神的コストを減らせるわけですから、長期的には価値ある投資になると考えるユーザーもいるでしょう。
Deep Researchを実際に試してみた

ここまで概念や機能、活用事例を挙げてきましたが、「じゃあ実際に使うとどんな感覚なの?」と思う方も多いでしょう。
ここでは僕(リュウセイ)が自身のX(旧Twitter)アカウントでポストしたDeep Research試用の様子を、簡易的にご紹介してみます。
Deep Researchが僕のアカウントに来た瞬間、早速調査を開始。
ちなポスト文では「モデルとしては情報によるとo3-mini-highで動くらしい。」とかほざいていますが、正確には「o3」です(後述します)。
最初なのでまずは簡単なプロンプトを投げてみる。
調査タスクが正常に立ち上がると、プログレスインジケーター(進捗具合をゲージで表してくれるやつ)が表示されます。
プログレスインジケーターが表示されなかった場合はタスクが正常に始まっていない証拠なので、もう一度プロンプトを投げるなど対応してください。状況によってすぐにプログレスインジケーターが表示されないこともあるので、プロンプトを送信した後は少し様子見しましょう。
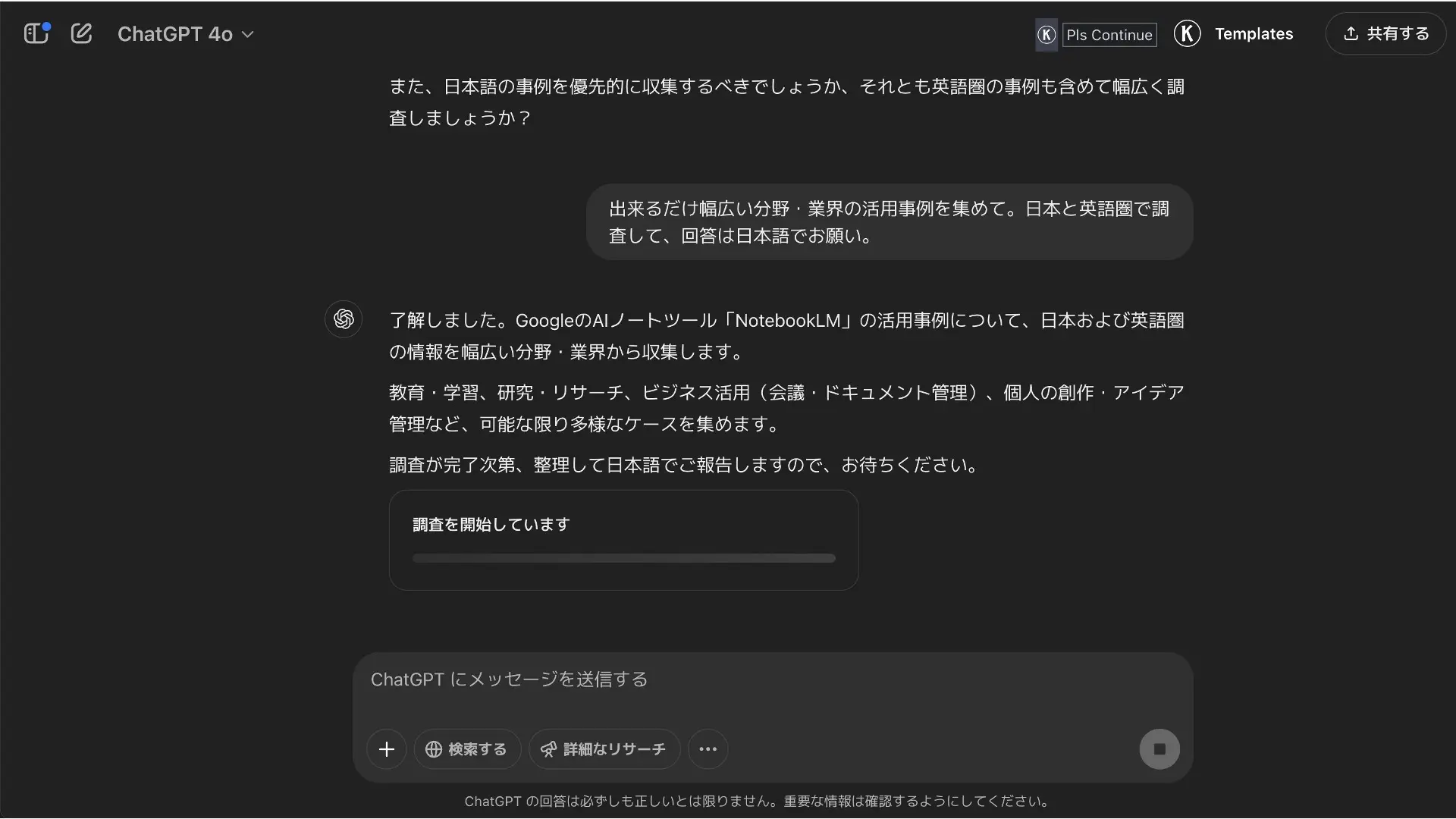
タスクが開始されると、右側にサイドバーが展開され、裏側で動くDeep ResearchのAIエージェントの軌跡を見ることができます。
調査内容によって時間は異なりますが、今回では5分ちょっとで調査が終了し、ちょうど5,600文字のレポートを出してくれました。
上記の初使用時では簡易的なプロンプトで実行させたため、次は同じテーマでプロンプトをさらに練り込んだバージョンで試してみたところ、1.1文字越えのレポートを出してきました。

他の人のポストによると、「2万文字越え」や果てや「4万文字越え」のレポートが一発で生成されたなどの報告も見受けられ、Deep Researchのヤバさがよく分かります。
現状ではProプランでしか使用できない「o1-pro-mode」でも3万文字越えの一発出力は厳しいため、それと同等以上の文字数を出してくるDeep Researchはバケモンですね。
Deep Researchで使われているAIモデル
ここまでで既に解説しましたが、Deep Researchで使われているAIモデルは「o3(オースリー)」というモデルです。
o3は現状の「ChatGPT o1」の進化系とされており、o1(オーワン)よりもガチヤバな性能を誇っているそうです。
Deep Researchがリリースされた2025年2月3日時点では、o3は下記の2バージョンが実装されています。
- o3-mini(オースリー ミニ)
- o3-mini-high(オースリー ミニ ハイ)」
これら2つは「o3のプレビュー版」のような位置付けであり、完全体o3ではありません。
「完全体o3」は現時点でまだリリースされていないのですが、先述の通りDeep Researchを介して実質的に解禁されました。
つまり(現状では)Deep Researchを使用することで、o3を先行体験できるということ。
こればっかりは実際に自分で使ってみないとその凄さってのは分かりづらいと思いますが、「"Deep Research ✖️ o3"は破壊力抜群」とだけ言っておきますね。
レポート出力と所要時間
実際の調査開始から完了までの所要時間ですが、僕が最初に試した時では5分ちょいで終わり、その後も何回か別テーマで使ってみた結果としておよそ数分〜10分程度で終わるケースが多かったです。
とはいえ「もっと重いテーマを投げれば30分以上かかる可能性もある」という話があるので、現段階では「短いと数分、長いと数十分」というイメージでしょう。
サイドバーにはリアルタイムで“調査中”の様子が表示され、「複数サイトを巡回中」「Python分析に移行中」といったステータスが細かく更新されるところがユニークでした。
この辺りのユーザー体験は、通常のChatGPTの即時応答とは明らかに違っていて、まさに「AIが裏で頑張ってるんだなぁ」と思わず見入ってしまう感じです。
実際に出力されたレポートは、数千文字〜1万文字を超えるという事例もありました。
実体験として1.1万文字以上の出力もありましたし、他の人の報告では3〜4万文字越えも一発で出してきたという情報もあります。
つまり、高度なテーマを与えれば与えるほど、Deep Researchは多くの情報を吸い上げて“結果レポート”を膨らませる傾向があるわけです。
ただし、一度にそれだけ大量の文章が返ってくるので、読み手が消化するのにも時間がかかることは否めません。
レポートを全部精読してリンク先もチェックしようと思えば、それこそ何時間かかるんだという話になります。
もちろん、それをやってでも徹底的に比較検討したい場面では非常にありがたいのですが、ライトユーザーには過剰かもしれませんね。
使ってみた感想と注意点まとめ
感想まとめ
- 「圧倒的に長文が出力される」
通常のChatGPTやBing検索だと、長くても数千文字が限界というイメージでしたが、Deep Researchはそれを軽く上回る。
5,600文字はまだ控えめな部類で、条件次第では1万文字超えも普通にある。 - 「サイドバーで見える“思考過程”が面白い」
何を考えて検索キーワードを組み立てたかなどが断片的に分かるので、AIが仕事をしている様子が実感しやすい。 - 「短めの調べ物には向かない」
あくまで大きな買い物や複雑なリサーチ案件など、「時間をかけてでも綿密に調べたい」領域に特化している感じ。
注意点・リスクまとめ
- 誤情報(幻覚)の可能性はゼロではない
リンクが存在しない、情報がズレているなどの事象に遭遇したユーザー報告もある。
結局、AIの出力を人間が最終チェックする必要がある。 - 時間と計算リソースがかかる
大規模な調査では、5〜30分くらい待つだけでなく、月100回のクエリ上限も意外とすぐに達してしまうかもしれない。
必要性の高いテーマに絞って使う運用が望ましい。 Proプラン(月200ドル)の契約が前提→ 2025年2月26日にPlusプランにも開放!
このコストが見合うかどうかはユーザー次第。
個人利用で「ちょっと調べものしたい」程度なら、投資回収が難しいケースも多いと思われる。
総合すると、僕が試用してみた限りでは「使いどころを絞ればすごく強力な味方になる」という印象を受けました。
逆に言うと、何でもかんでもDeep Researchに頼むのは現実的ではなく、通常の検索と上手く使い分けるのが理想的だろうなと感じています。
Deep Researchに期待されること

Deep Researchはまだリリースされて間もない機能であり、ユーザーからのフィードバックやOpenAIのアナウンスを見ても、今後の発展が非常に楽しみな領域です。
ここでは将来的に想定されるアップデートや、OpenAIが言及している計画を中心にまとめてみます。
Operatorとの連携と汎用エージェント化
OpenAIは以前から「Operator(オペレーター)」という別のエージェント機能を検討していると噂されています。
【OpenAIのAIエージェント第2弾】Operatorを解説!ChatGPT Proユーザーの新たな選択肢
Operatorとは、実際にウェブサイト上でアクションを起こしたり、メール送信や予約手配など“現実世界のタスク”までこなすエージェントのことです。
もしDeep Research(リサーチ機能)とOperator(実行機能)が統合されたらどうなるか?
例えば、「旅行プランを徹底的に調べて→最適な組み合わせを提案し→そのまま航空券や宿の予約までやってくれる」といったシナリオが考えられます。
つまり、リサーチだけでなく実務まで丸ごとAIに任せる世界が近づくわけです。
一方で、これはAI安全性の観点から見ると「AIが暴走して大量のメールを送信する」「誤った操作でユーザーに不利益を与える」といったリスクを伴うため、慎重な導入が求められるでしょう。
強化学習でどこまで安全策を取れるか、ユーザー権限をどの程度で区切るかなど、課題は山積みです。
それでも、「Deep Research × Operator」の構想は多くのユーザーが期待している将来像の一つと言えます。
アクセス可能データソースの拡充
もう一つの大きな展望は、アクセスできるデータソースの範囲拡大です。
- 有料データベースへのアクセス
現状、Deep Researchは主に「無料で閲覧可能なWebコンテンツ」や「ユーザーがアップロードしたファイル」に依存している部分が大きい。
しかし、もし有料の学術論文データベースや高品質な市場レポートなどにもアクセスできるようになれば、より正確で専門性の高いリサーチが可能になる。
ただし著作権やプライバシーの問題をどうクリアするかが課題。 - 企業の内部データベースとの連携
一部では、「企業内部の機密データや社内WikiをDeep Researchに取り込んで、最先端のナレッジマネジメントを実現する」構想がある。
例えば、“社内限定の検索AI”として自社情報をガッツリ横断して調査し、レポートをまとめてもらう。
もちろんセキュリティ対策を厳格にしないと、外部へのデータ流出リスクもあるため、実装には細心の注意が求められるだろう。 - モバイルアプリやデスクトップアプリでの利用
OpenAIは今後、モバイルアプリやデスクトップアプリにもDeep Researchを対応させると発表している。
これにより、「スマホ上で気軽にPDFや画像をアップロード→数十分後に調査レポートが届く」ような使い方がより身近になるかもしれない。
これらの拡充が進めば、深いリサーチのハードルがさらに下がり、ビジネスでも学術でも個人ユースでも新たな活用シーンが見出されるでしょう。
ただし、同時に利用料金の負担やデータの公開/非公開に関する法的問題も無視できないため、実装には段階的に時間をかけることが予想されます。
安全性・信頼性への取り組み
AIが自律的にウェブを巡回し、Pythonコードを実行して様々な作業を行う――
こうした「自律型エージェント」は、便利な反面、暴走リスクやアラインメント問題(AIが人間の意図しない目標を追う可能性)といった懸念を伴います。
- 過剰アクセスやDOS行為
もしAIが誤って膨大なリクエストをサイトに投げ続ければ、そのサイトに負担をかける恐れがある。
OpenAIは一定のリクエスト制限をかけているとされるが、完全に防げるかどうかは不透明。 - 不適切な情報の取得や悪用
Deep Researchが違法サイトや公序良俗に反する情報源を読み込んでしまい、それをレポートにまとめる可能性もゼロではない。
利用者側のモラルや法的コンプライアンスが重要になる。 - 間違った結論を自動行動に繋げてしまうリスク
将来的にOperatorとの連携が進むと、「AIが誤情報を元に取引を実行してしまった」などの事態も起こりうる。
これを防ぐにはヒューマン・イン・ザ・ループ(人間による承認プロセス)を適切に挟む設計が求められる。
OpenAIは「Deep Researchはまだ実験的な段階であり、安全策を一層強化していく」とコミュニティなどで述べているようです。
強化学習をさらに発展させて、人間に有害な方向へAIが行動しないようにするためのアルゴリズム研究も進むでしょう。
実際、Deep Researchの大きな可能性が認められる一方で、それと同じくらい社会的責任や安全性の議論が必要になるのは間違いありません。
まとめ

- Deep Researchは、ChatGPTの新モードとして2025年2月3日にリリースされた、自律型リサーチエージェント。
従来のブラウジングや検索AIと違い、数ステップ〜数十ステップに及ぶマルチステップ調査を自動で行い、最終的にレポート形式のアウトプットを返してくれる。
ウェブブラウザやPDF解析、Python実行環境などを統合しており、多彩なデータソースを横断的に扱える点が特徴。 - 大きく進化したポイント
強化学習(RL)によりツールを自律的に呼び出し、必要な検索や分析を繰り返す仕組み。
出典リンクや思考過程(サイドバー表示)で透明性を高め、ユーザーが検証しやすいよう工夫。
幻覚や誤情報への対策も施されているが、完全な解決には至っていない。 - ユーザーの反応
「1万文字を超える詳細レポートが数十分で出る」として大きな驚きと称賛の声がある。
一方、「月200ドルは高額」「誤情報の混入リスクが消えていない」などの批判的意見も根強い。
使いどころを絞れば非常に強力だが、軽い検索や細かな用途にはオーバースペックという見方も多い。 - 活用事例とユースケース
ビジネスインテリジェンスや競合分析で、企業内の下調べにかかる時間を大幅短縮。
学術・技術開発での文献レビューや特許解析にも応用。
日常生活の大きな買い物などで、複数のレビューサイトを一括要約して比較検討に役立つ。 - 僕自身が実際に試してみた感想
「AIが裏で“本格リサーチ”をしている」感が強く、サイドバーの動きも新鮮。
出力される文量が圧倒的で、使う場面によっては読み切るのに時間がかかるとも感じた。
幻覚リスクへの注意や高額プランへの不満もあるが、大規模調査を要するケースでは非常に助かるツール。 - 今後の展望
Operator連携による汎用エージェント化が進めば、リサーチ結果を基に実行(予約・購入等)までAIが行う未来が見えてくる。
データソースの拡充や企業内部データとの連携などが進むと、さらに活用範囲が広がる。
同時に、安全面や信頼性をどう担保するかが大きな課題となる。
最後に、Deep Researchはあくまで「AIがやってくれるリサーチの初期ドラフト」と捉えるのが無難だと僕は思っています。
AIが繰り返し検索と分析を行うことで、人間の時間を節約してくれるのは間違いありません。
ただし、その結果をどう活かすかはあなたのチェックや最終判断が欠かせません。
Proプラン限定(月200ドル)・月100回までの制限など、ハードルはあるものの、今後さらに改良と価格調整が進めば、検索の常識を一変させる存在になる可能性は大いにあります。
Plusユーザー等にも解禁され、月10回まで使用できます。また、Proプランでは月100回が月120回まで拡張されました。
もし本格的なリサーチを伴うプロジェクトに携わっているなら、Deep Researchが解禁されるエリアやプランが整い次第、ぜひ一度試してみてはいかがでしょうか。
最後まで読んでいただき、ありがとうございました!
ChatGPTの使い方や活用法にお悩みの方は、ぜひ僕にご相談ください!
初回は無料でご対応させていただきます → コチラからどうぞ〜
