この記事の3行要約
- ChatGPTのGPTsにCSV形式のデータを渡す方法と、その設計思想を初心者にもわかりやすく解説
- 構文は一つずつ書く時代じゃない。“データを預けることで、言語のパターンを設計する”時代だ
- 本記事では、CSV構成のポイント、読み込ませる方法、GPTs設計との接続方法まで丁寧に整理しています
こんにちは、リュウセイです。
ChatGPT活用支援サービスをやっています。
当記事では、ChatGPTのGPTs(ジーピーティーエス)作成に役立つ「CSVファイルの作り方」について解説します。
CSVファイルは、独自性の高いGPTsを作成する上で必須アイテムです。
具体的にどのようなデータをCSVで与えると良いのか?についてまずは詳しく見ていきましょう。
また記事の最後では、ChatGPTの解析に適したCSVに修正してくれるGPTsの共有リンクを提供しています。GPTsプロンプトも公開しているので、ぜひ最後まで記事を読んでください。
独自性の高いChatGPTのGPTsを作るには「ビッグデータ」が超重要

独自性の高いGPTsを作るには、何が必要だと思いますか?
もちろんプロンプトも重要ですが、それと同じ以上に重要なのが「ビッグデータ」です。
ビッグデータとは
ビッグデータとは、非常に大量で多様なデータの集まりのこと。例えば、インターネットの検索履歴やSNSの投稿、オンラインショッピングの購入履歴など、日々増え続ける情報が含まれる。これらのデータは、企業や研究者が分析して、消費者の行動パターンを理解したり、新しい製品やサービスを開発するために使われる。最近では、AIや機械学習を使ってビッグデータを効率的に活用することが注目されている。
正直、プロンプト自体はAIでも書けるため、再現はしやすい方です。
しかし、ビッグデータの場合は希少価値の高いデータであるため、再現は難しいと言えます。
ビッグデータを与えることで、独自性の高いGPTsを作成できる
ビッグデータを与えることで、他には無い独自性の高いAIエージェント(GPTs)を作成できます。
GPTsにビッグデータを与える際に気を付けることは「適切なファイル形式を選ぶこと」です。
結論を言うと、GPTsに対応しているファイル形式の中では「CSVファイル」が最もおすすめですね。
GPTsが対応しているファイル形式
- テキストファイル:.txt
- ドキュメントファイル:.pdf, .doc, .docx
- スプレッドシート:.csv, .xlsx
- プレゼンテーションファイル:.ppt, .pptx
- 画像ファイル:.jpg, .jpeg, .png
- コードファイル:.py, .js, .html, .css, .json, .md, .ts, .tsx, .jsx
- その他:.zip
GPTsにアップロードできるファイルのうち、ビッグデータに最も適したファイルは「CSV」です。
CSVとは
CSV(シーエスブイ)とは、Comma-Separated Values(カンマ区切り値)の略で、データを表形式で保存するためのファイル形式の一つ。各行がレコードを表し、各フィールドはカンマで区切られている。例えば、エクセルの表のようなデータを簡単に保存・読み込みできる。日常では、例えば連絡先リストや売上データの保存に使われることが多い。CSVは、多くのアプリケーションでサポートされているので、データ交換に便利。
CSVは「大量のデータを格納できる」かつ「シンプルなデータ形式」なので、GPTsに大量の学習をさせるファイル形式として優れています。
また、初心者でも無料のツールを使うことで簡単に作成できるという利点もあります。
CSV以外のファイル形式でビッグデータを与えるとどうなる?
CSV以外でも、例えば「.txt」や「.json」などでビッグデータを与えることはできます。
しかし、大量のデータを最もスムーズに解析できるのはCSV形式であるため、最適なのはCSVです。
データ種別に応じたファイル形式を選択することで、ChatGPTはよりデータを解析しやすくなり、回答精度も高まります。
ファイルのアップロード以外でのビッグデータの与え方
ビッグデータはCSVで与える以外にも様々な方法があります。
ここでは全てを詳しく解説しませんが、ざっと確認してみましょう。
- APIを使用する
- 概要:外部データソースやデータベースから直接データを取得するためのAPIを利用する。
- 利点:リアルタイムでデータを取得・更新できる。
- 例:RESTful API、GraphQL
- データベース接続
- 概要:GPTsをデータベースに直接接続し、SQLクエリなどでデータを取得する。
- 利点:大量のデータに対して効率的なクエリ実行が可能。
- 例:MySQL、PostgreSQL、MongoDB
- クラウドストレージ
- 概要:クラウドストレージサービス(例:AWS S3、Google Cloud Storage、Azure Blob Storage)を利用してデータを保存し、そこから読み取る。
- 利点:大規模データのストレージとアクセス管理が容易。
- 例:Amazon S3、Google Cloud Storage
- ストリーミングデータ
- 概要:ストリーミングデータプラットフォームを使用してリアルタイムデータをGPTsに送信する。
- 利点:リアルタイムでデータの処理が可能。
- 例:Apache Kafka、Amazon Kinesis、Google Pub/Sub
- データパイプライン
- 概要:ETL(Extract, Transform, Load)ツールを使用して、データの抽出、変換、ロードを自動化する。
- 利点:データの前処理やクリーニングが容易。
- 例:Apache NiFi、AWS Glue、Google Dataflow
- Webクローリング
- 概要:ウェブクローラーを使用してウェブサイトからデータを収集する。
- 利点:ウェブ上の広範なデータを収集可能。
- 例:BeautifulSoup、Scrapy、Puppeteer
- ファイル転送プロトコル(FTP/SFTP)
- 概要:FTPまたはSFTPを使用して、サーバー間で大容量ファイルを転送し、そこから読み取る。
- 利点:セキュアなファイル転送が可能。
- 例:FileZilla、WinSCP
- メッセージキュー
- 概要:メッセージキューシステムを使用してデータを非同期的に送信する。
- 利点:分散システムでのデータ処理が容易。
- 例:RabbitMQ、Amazon SQS、Apache ActiveMQ
- サードパーティデータ統合ツール
- 概要:サードパーティのデータ統合ツールを使用して様々なデータソースを一元化する。
- 利点:複数のデータソースを統合して効率的に管理。
- 例:Zapier、Integromat、MuleSoft
CSV以外でも色んな方法がありますが、上記はどれも初心者には難易度が高く、最も簡単なのはCSVを作成してアップロードすることです。
ChatGPTが解析しやすいCSVファイルの基本項目11個
GPTsにCSVファイルをアップロードして学習させる上では、「GPTsの解析に適したCSVファイル構造にすること」が重要です。
GPTsの解析に適したCSVファイル構造とは、以下の通りです。
基本項目11個
- 項目が設定されている
- 項目分けが適切に行われている
- 数字が「カンマ区切り数値」になっていない(整数または浮動小数点数)
- 空白セルには「NaN」が入力されている(欠損値データとして認識できる)
- セル内でテキストが改行されていない
- セル内のデータ(テキスト、数値など)が簡潔に表記されている
- UTF-8エンコーディングで保存されている
- 各列のデータ型が一貫している
- セル内のカンマやダブルクオートは適切にエスケープされている
- 重複データが排除されている
- データが少量であるか(ファイルサイズ:~5MB、レコード数:~10,000行)
それぞれ順番に見ていきましょう。
1. 項目が設定されている
CSVファイルの1行目には、各列の項目名(ヘッダー)を設定することが重要です。
これにより、GPTsがデータの構造を理解しやすくなります。
例えば、「名前」「年齢」「性別」といった具合に、各列の内容を明確に示すヘッダーを付けましょう。
項目名があることで、データの意味や関連性がGPTsにとって明確になり、より適切な解析ができます。
2. 項目分けが適切に行われている
データの特性に応じて、適切に項目を分けることが大切です。
例えば、「氏名」を「姓」と「名」に分けたり、「住所」を「都道府県」「市区町村」「番地」などに分割したりすることで、より詳細な分析が可能になります。
適切な項目分けは、GPTsがデータの構造をより正確に理解し、効果的な解析を行うための基盤となるのです。
3. 数字が「カンマ区切り数値」になっていない
数値データは、カンマ区切りではなく、単純な整数または小数点表記にすることが重要です。
例えば、「1,000,000」ではなく「1000000」と表記します。
これは、カンマがCSVファイルの区切り文字として使用されることが多いため、数値内のカンマが誤って解釈される可能性があるからですね。
単純な数値表記にすることで、GPTsが正確にデータを読み取り、計算や分析を行うことができます。
4. 空白セルには「NaN」が入力されている
データに欠損値がある場合、空白のままにせず「NaN」と入力しましょう。
これにより、GPTsは欠損値を適切に認識し、処理することができます。
「NaN」を使用することで、データの欠損が意図的なものであることが明確になり、GPTsはそれに応じた適切な処理や補完方法を選択できるようになります。
※「NaN」は「Not a Number」の略です。
5. セル内でテキストが改行されていない
CSVファイル内のセルでテキストを改行すると、GPTsがデータを正しく解釈できなくなる可能性があります。
そのため、セル内のテキストは一行で記述することが望ましいですね。
長文の場合は、適切な区切り文字(例:セミコロン)を使用するか、別の列に分割することを検討しましょう。
これにより、データの一貫性が保たれ、GPTsによる解析の精度が向上します。
6. セル内のデータが簡潔に表記されている
データは可能な限り簡潔に表記することが重要です。
不要な情報や冗長な表現は避け、必要最小限の情報を明確に記述しましょう。
例えば、「はい」「いいえ」の代わりに「Y」「N」を使用したり、長い文章を要約したりすることが効果的です。
簡潔な表記は、GPTsがデータを効率的に処理し、本質的な情報に焦点を当てた解析を行うのに役立ちます。
7. UTF-8エンコーディングで保存されている
CSVファイルは「UTF-8エンコーディング」で保存しましょう。
UTF-8は、多言語対応の国際的な文字コード規格であり、様々な言語や特殊文字を正確に表現できます。
これにより、GPTsは異なる言語や文字セットを含むデータを適切に解釈し、処理することができるのです。
文字化けや解析エラーを防ぐためにも、UTF-8エンコーディングの使用は重要な要素となります。
ちなみに、Googleスプレッドシートで作成したCSVは自動的にUTF-8エンコーディングで保存されるため、エンコーディングの心配は不要です。
8. 各列のデータ型が一貫している
「年齢」列はすべて数値、「名前」列はすべてテキストというように、同じ列内でデータ型を統一します。
これにより、GPTsはデータの構造を正確に理解し、適切な処理や分析を行うことができます。
データ型の一貫性は、解析の精度と効率を高める重要な要素なのです。
9. セル内のカンマやダブルクオートは適切にエスケープされている
CSVファイル内でカンマやダブルクオートを含むデータを扱う場合、適切なエスケープ処理が必要です。
例えば、テキストにカンマが含まれる場合は、そのセル全体をダブルクオートで囲みます。
また、テキスト内にダブルクオートがある場合は、それを二重にします。
このエスケープ処理により、GPTsはデータの区切りと内容を正確に識別し、解析の精度を保つことができるのです。
10. 重複データが排除されている
データセット内の重複は、解析に支障をきたす可能性があります。
完全な重複行は削除し、部分的な重複がある場合は必要に応じて統合や修正を行いましょう。
重複データの排除により、ChatGPTの解析精度は向上します。
11. データが少量であるか
ファイルサイズは5MB程度、レコード数は10,000行程度までに収めましょう。
それ以上になると、処理時間が増加するため、解析が複雑になります。
そもそもCSVはシンプルなデータ形式なので、どちらかと言えば10,000行を超えないように意識することが重要ですね。
ChatGPTの解析に適したCSV作成において、意味がないこと8つ
ChatGPTの解析に適したCSV作成において、「やっても意味がないことリスト」は以下の通りです。
意味がないことリスト
- セルを結合する
- 「テキストデータ」と「数値データ」以外を含める
- ハイパーリンク(テキストや画像に埋め込まれたリンク)を含める
- セルやテキストに色付けする
- 文字サイズを変更する
- セルのサイズを変更する
- 複数のシートを用意する
- 「何もデータが無い」ことを示すために空白セルを使用する
順番に見ていきましょう。
1. セルを結合する
CSVファイルはカンマで区切られたテキスト形式のファイルであるため、セルの結合は無意味です。
CSVに変換する際に自動的にセルの結合は解除され、セル内データは結合されていたセルの第一セルに全て移管されます。
そうなると空白セルが生まれることになり、正しく解析できません。
CSVファイルでは、各データポイントが明確に分離されたセルに配置されるべきです。
2. 「テキストデータ」と「数値データ」以外を含める
CSVファイルは「テキストデータ」と「数値データ」だけを扱う形式です。
例えば、「画像、音声、動画」などの非テキストデータを含めても解析できないため、意味がありません。
画像は別ファイルとしてアップロードして解析させましょう。
3. ハイパーリンクを含める
CSVファイルにハイパーリンク(テキストや画像に埋め込まれたリンク)を含めることは無意味です。
CSVはプレーンテキスト形式であり、リンクをクリック可能な状態で保存することができません。
リンクは単なる文字列として保存されるため、ユーザーは手動でコピー&ペーストして使用する必要があります。
ハイパーリンクを活用したい場合は、HTMLや他のリッチテキスト形式を使用するべきです。
4. セルやテキストに色付けする
CSV形式では、セルやテキストに色を付けることができません。
色付けはデータの視覚的な整理や強調に役立ちますが、CSVファイルではこれを実現する方法がないため、色に依存した情報伝達は避けるべきです。
データの視覚的強調が必要な場合は、CSVファイルをスプレッドシートソフトで開き、そこで色付けを行うのが良いでしょう。
5. 文字サイズを変更する
CSV形式では文字サイズの変更は意味がありません。
CSVファイルはプレーンテキスト形式であり、フォントや文字サイズの情報を保持することができません。
フォーマット情報が必要な場合は、スプレッドシートソフトやワードプロセッサを使用し、適切なファイル形式で保存するべきです。
6. セルのサイズを変更する
セルのサイズ変更もCSV形式には適用できません。
CSVは単純なテキストファイルであり、各セルの内容はカンマで区切られているだけです。
セルのサイズや形状の情報を含むことはできないため、視覚的なレイアウト調整はスプレッドシートソフトで行う必要があります。
7. 複数のシートを用意する
CSVファイルは単一シートのデータのみを扱う形式です。
Excelや他のスプレッドシートソフトでは複数のシートを持つことができますが、CSV形式ではこの情報を保持することができません。
複数のシートが必要な場合は、各シートを別々のCSVファイルとして保存するか、Excel形式など他の形式を使用する必要があります。
8. 「何もデータが無い」ことを示すために空白セルを使用する
CSVファイルでは、空白セルは単にデータがないことを示しますが、解析時に意味が通じにくい場合があります。
何もデータがないことを明示するためには、「NaN」を使用しましょう。
NaNを入力しておくことで、データ解析時に欠損値として認識できるため、解析精度が上がります。
ChatGPTが解析しやすいCSVファイルの具体的な例
ChatGPTが解析しやすいCSVの構造について、具体例を基に見ていきましょう。
先に「良くない例」を挙げて、その後に「改善例」を挙げるという構成で解説しますね。
また例として提示するCSVは、分かりやすいように色付けしてありますが、実際には色付けは不要です。
良くない例①
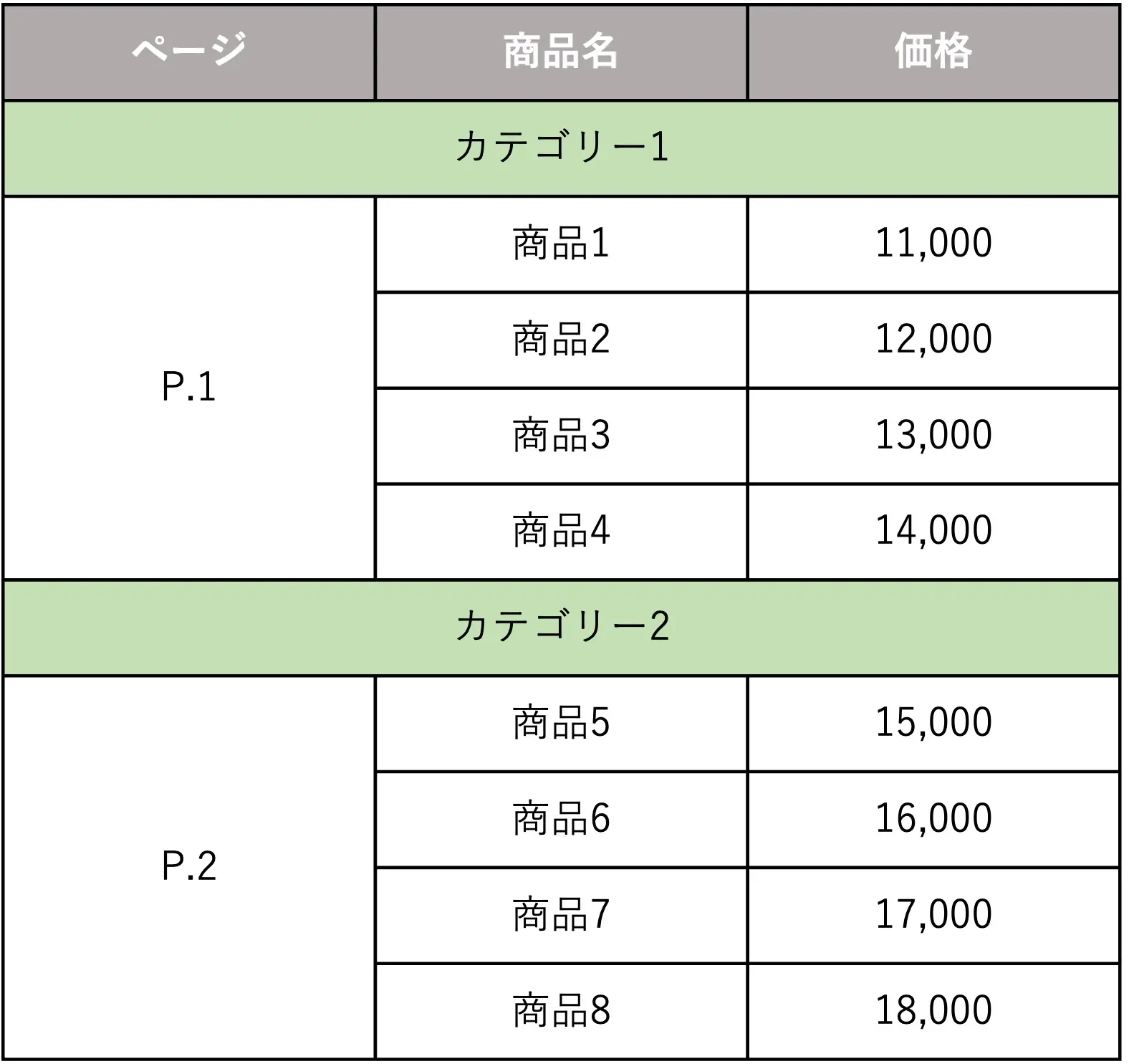
人間が見る分には綺麗に整っていますが、ChatGPTの解析においてはデメリットとなります。
具体的な修正点としては以下のとおりです。
修正点
- セルの結合が使われているため、結合を解除する
- 「ページ」のP.1とP.2の表記を整数に直す
- 「価格」の金額にカンマ(,)が入っているため、整数に直す
ちなみに、上記の構造で作成したファイルをCSVにすると、以下のような表示になります(色は無視してください)。
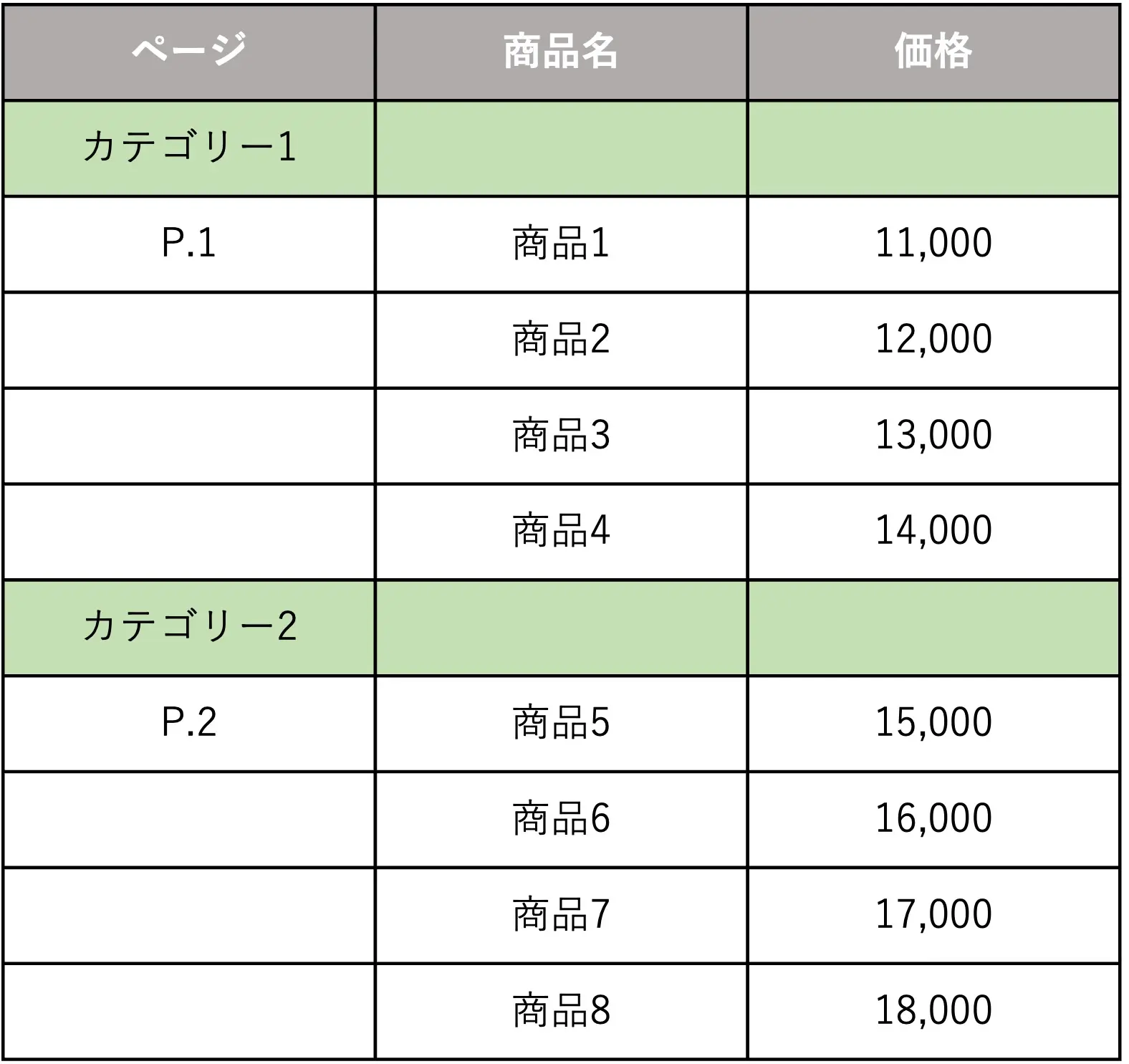
このようにセルの結合が無視され、結合されていたセルの第二セル以降は全て「空白セル」となります。
上記の場合、「商品2〜商品4、商品6〜商品8」のページが認識されず、そして「商品名」にはカテゴリーが無い状態です。
空白には「NaN」を入力するのが(Pythonのpandasの場合)基本ですが、その入力が無いため、ChatGPTは正しく解析できません。
上記の例の場合は、次の通りに改善すると良いでしょう。
改善例①
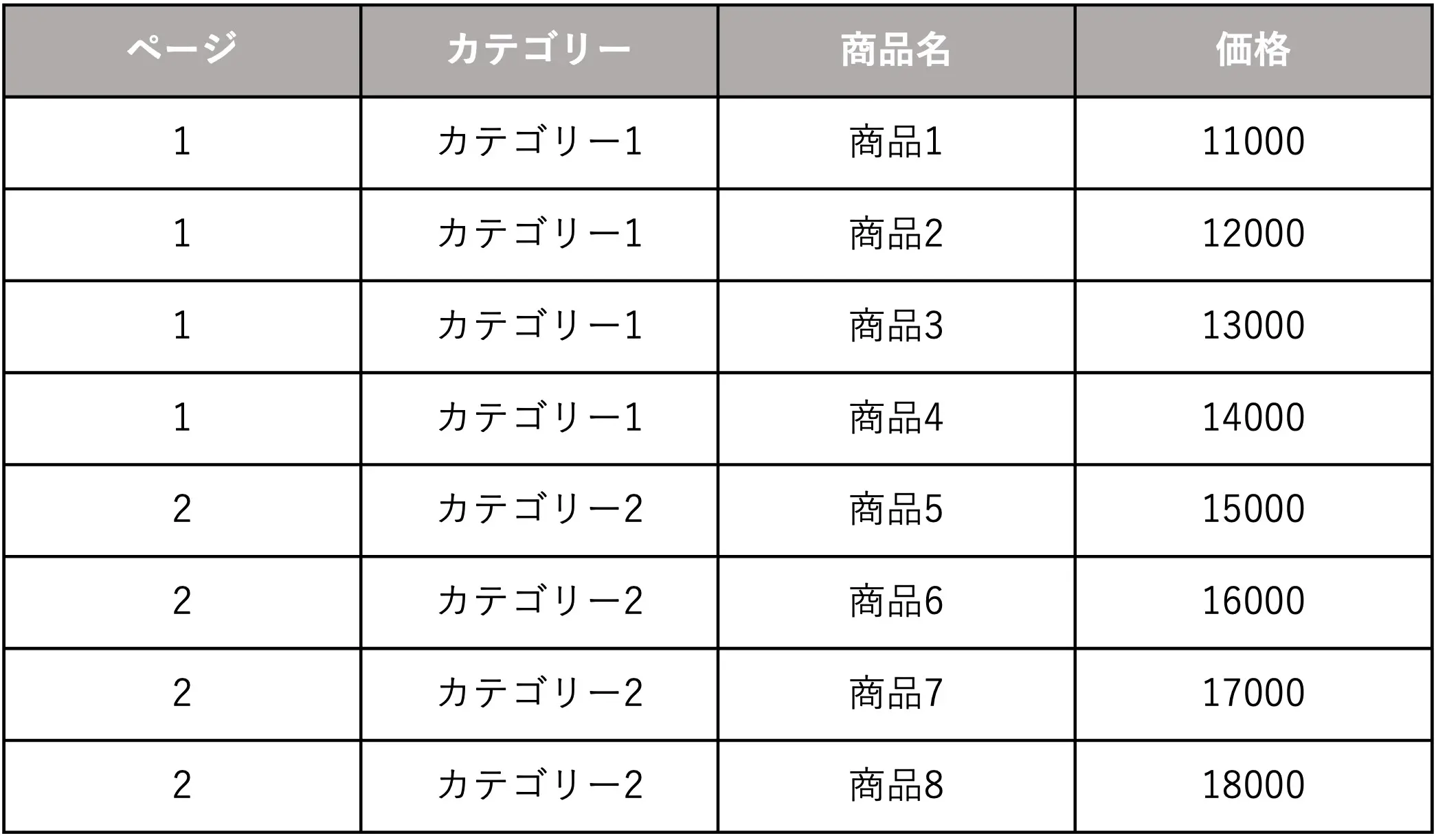
改善点
- 「ページ」の数値を整数にし、商品ごとに表記した
- 「カテゴリー」の列を新たに作成した
- 「価格」の数値を整数にした
こんな感じで修正すれば、ChatGPTはCSVを解析しやすくなり、より正確なデータ抽出が可能になります。
絶対に空白のセルは作らず、上記で言えばページやカテゴリーの表記を商品ごとに1つ1つ入力しておくことが理想です。
手間ですが、その手間のおかげで精度の高いGPTsを作れるということですね。
良くない例②
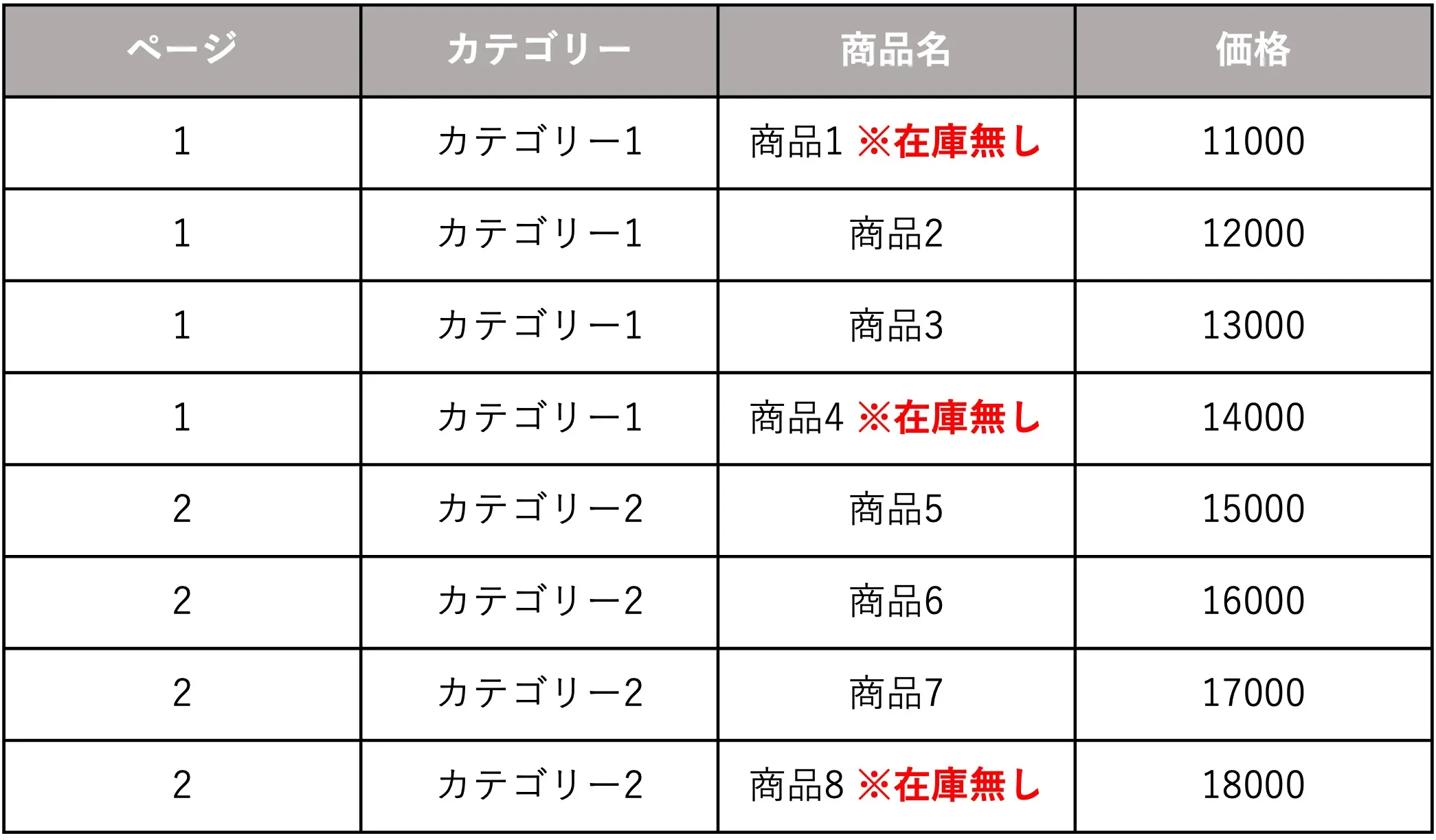
修正点
- 商品の隣に在庫情報が記載されているが、これだと例えば「商品1 ※在庫無し」が商品名として認識されるため、項目分けを行う必要がある
データには2つ以上の情報を含めないことが鉄則です。
上記の例だと、本来は「商品1」という商品名であっても、ChatGPTは「商品1 ※在庫無し」が商品名だと誤認します。
「商品1」と「※在庫無し」の2つのデータが1つのデータに含まれているため、次の通りに改善しましょう。
改善例②
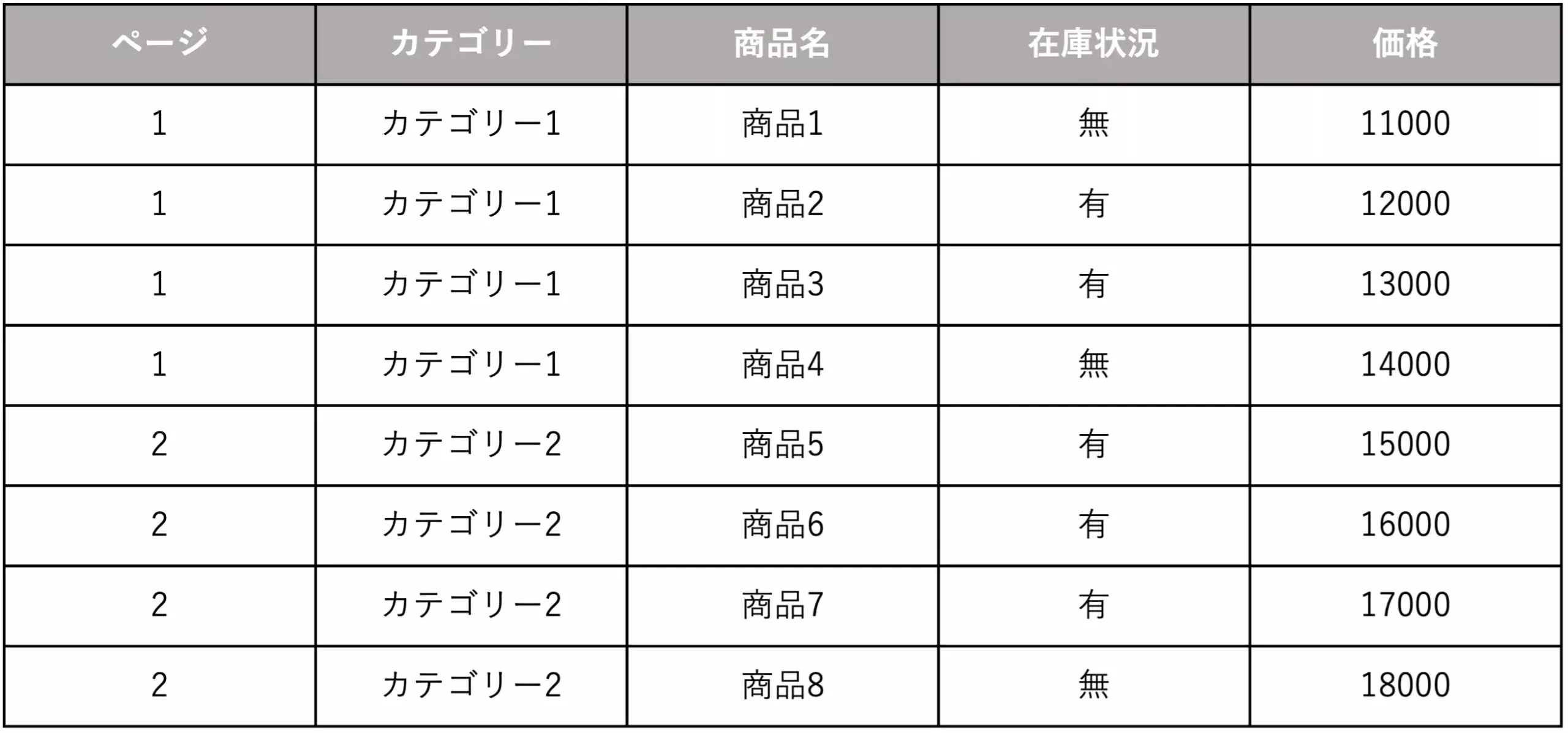
改善点
- 「在庫状況」という新しい項目を作成し、商品名を正しく認識できるようにした
「商品名」の中に在庫状況のデータも同時に含めないようにすることで、それぞれのデータが独立性を持ち、ChatGPTはよりデータを解析しやすくなります。
ついつい補足情報として付け加えてしまいがちですが、どんなに細かい情報であっても、「データは1つ1つ独立させる」という鉄則は頭に入れておきましょう。
CSVファイルを簡単に作成できるオススメのツール
CSVファイルを最も簡単に作れるのは「Googleスプレッドシート」です。
もちろんExcelでもいいですが、アカウントさえあれば無料で利用できるGoogleスプレッドシートが便利ですね。
流れとしては、Googleスプレッドシートで作成したデータをCSV形式でダウンロードするだけです。
GoogleスプレッドシートでCSVファイルを作成する手順
スプレッドシートの左上にある「ファイル」のタブをクリックし、「ダウンロード」項目の右端にある展開アイコン(右向き矢印)をクリックしましょう。
そして「カンマ区切り形式(.csv)」をクリックして、ダウンロードするだけです。

Excelでも同様の操作でCSVをダウンロードできます。
ChatGPTのGPTsにCSVをアップロードする際の注意点
作成したCSVをGPTsにアップロードする際、必ず「コードインタープリターとデータ分析」にチェックを入れておきましょう。
この機能をONにしておくことで、アップロードしたファイルの処理・解析などが行えるようになります。
最初はチェックが外れている状態なので、忘れずにチェックしてください。


また「コードインタープリターとデータ分析」にチェックを入れることで、Pythonの実行が可能になるため、計算も行えるようになります。
例えば金額の計算などをGPTsにやってもらいたい場合は、ファイルのアップロードをしていなくても、「コードインタープリターとデータ分析」のチェックは必須です。
ChatGPTのファイル解析エラー時の対処法
ChatGPTにファイルをコードインタープリターで起動させる際に、時たま「解析エラー」が発生することがあります。
特にCSVはフォーマットの不一致やデリミタ(区切り文字)の問題が発生しやすいため、他のファイル形式より解析エラーが起きやすいです。
解析エラーが起きても、ChatGPTは再度読み込みを試みます。
しかしそれでも解析エラーが続いてしまう場合は、以下の処置を取りましょう。
- ChatGPTにエラーの詳細を聞き、どのようにCSVファイルの構造を改善したら良いかのアドバイスをもらう
- 新しいチャットを立ち上げて、もう一度ファイルの解析を指示する
またWindowsの「Ctrl + F5」やMacの「command + R」のように、「キャッシュを削除して再読み込み」する方法は有効ではありません。
なぜなら、CSVにおいて解析エラーが発生する主な要因は以下の通りであり、これらはブラウザのキャッシュとは関係がないためです。
- フォーマットの不一致
- デリミタの問題
- エンコーディングの問題
- データの構造的な問題
つまり、「ChatGPTの解析に適したCSVファイルの構造になっていない」ことが1番の原因ですね。
ChatGPTが解析しやすいCSVファイルの基本項目11個を必ず守るようにしましょう。
まとめ
「ChatGPTの解析に適したCSV構造にする」と聞くと何だか難しそうな印象を受けると思いますが、細かい編集が必要なだけで、技術的にはそう難しくありません。
ChatGPTが解析しやすいCSVの作り方を知っておけば、作成できるGPTsの幅が広がるので、ぜひマスターしておきましょう。
当記事を参考にして、より良いGPTsを作成することができれば幸いです。
最後まで記事を読んでくれた
あなたに特別にご案内
プロンプトはコチラ
