ChatGPTのDeep Research(AI)での出力結果をそのまま掲載しています。ChatGPTのDeep Researchはハルシネーション(誤った情報の生成)が少なくなるよう調整されていますが、あくまで参考程度に読んでください。当記事は検索エンジンに登録していないため、このブログ内限定の記事です。
序章:小さなモデルへの大きな期待
とあるIT企業の会議室。新入社員の山田さんは、最近耳にした「小規模言語モデル(SLM)」という言葉について先輩の田中さんに質問してみることにしました。
山田: 「田中さん、ニュースで“MicrosoftのPhi-4という小規模言語モデルが、大規模モデルを凌ぐ性能を発揮”って見たんですけど、小規模言語モデル…SLMって一体何ですか? 大規模なLLM(Large Language Model、大規模言語モデル)とどう違うんでしょうか?」
田中: 「いい質問だね。SLMは小規模言語モデル(Small Language Model)の略で、要するにパラメータ数(モデルの頭の良さを決める変数の数)が比較的少ないコンパクトなAIモデルのことだよ。一方、LLMはパラメータが何十億・何千億と多くて、大量のデータでトレーニングされている。 (Large Language Models(LLMs) vs. Small Language Models(SLMs)| Rackspace Technology) (Large Language Models(LLMs) vs. Small Language Models(SLMs)| Rackspace Technology)例えば、ChatGPTみたいな最新LLMは数千億~1兆以上のパラメータを持つとも言われているけど、SLMは数億~数十億程度の規模に抑えられているんだ。」
山田: 「規模が全然違うんですね。でも性能もだいぶ違うんじゃないですか? 大規模なほうが頭が良くて、小規模モデルはあまり賢くないとか…。」
田中: 「確かに従来は“大は小を兼ねる”で、大規模モデルは文章の流暢さや知識の網羅性で勝り、小規模モデルはどうしても理解力や精度で劣るとされてきたんだ (Large Language Models(LLMs) vs. Small Language Models(SLMs)| Rackspace Technology) (Large Language Models(LLMs) vs. Small Language Models(SLMs)| Rackspace Technology)。でも最近、その前提が揺らぎ始めている。小さいモデルでも工夫次第でびっくりするほど高性能になってきているんだよ。」
山田: 「えっ、それは興味深いです!工夫次第というのは…?」
田中: 「例えばこれを見てごらん。」
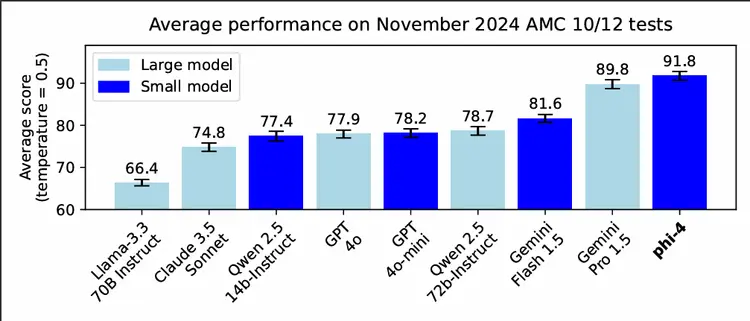
山田: 「本当だ…!Phi-4って14億…じゃなくて140億パラメータですよね?それでGoogleの超巨大モデルよりスコア高いなんて。 (Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning | Microsoft Community Hub)どうしてこんな“小さな”モデルが“大きな”モデルに勝てるんでしょう?」
田中: 「Phi-4が強い理由はいくつかある。Microsoftの説明によると、高品質の合成データを使った学習や、厳選された実データの投入、さらにはポストトレーニングの工夫など、データと訓練手法を徹底的に改善した成果らしい (Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning | Microsoft Community Hub)。要は、“質の高い学習”で小さな脳みそを効率よく鍛え上げたんだね。それによって数学のような複雑な推論が必要な分野で大規模モデルに匹敵する力を引き出したというわけさ。」
山田: 「なるほど…小さくてもトレーニング次第で侮れないんですね。他にもそんな例はあるんですか?」
田中: 「あるよ。例えば2023年にはスタンフォード大学などのチームがVicuna-13Bっていうオープンソースのチャットボットを公開した。パラメータ130億規模だけど、ChatGPTに迫る性能だと評価されたんだ。 (Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality | LMSYS Org)実験ではGPT-4を審査員にしてChatGPT(GPT-3.5相当)との回答品質を比較したら、VicunaはChatGPTの90%のクオリティに達したという結果が出ている (Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality | LMSYS Org)。」
山田: 「130億でChatGPTの90%ですか!?すごい…。ChatGPTの中身は非公開だけど、おそらくその何倍も大きいモデルですよね。」
田中: 「そうだね。さらに驚くのは、Mistral AIというスタートアップが出したMistral-7Bというモデルで、これはわずか70億パラメータしかないのに、Facebook(Meta)のLlama2-13B(130億)をあらゆるベンチマークで上回ったと報告されている。 (Mistral 7B | Mistral AI)つまり、小さいモデルがそれまで一回り大きかったモデルの性能を超えちゃったわけだ。データの選び方やモデル構造の工夫次第で“小さくても強い”モデルが作れることを証明した例だね。」
山田: 「小型で強いなんて、“ジャイアントキリング”ですね! となると、オープンソースのコミュニティでも盛り上がっていそうです。」
田中: 「まさにその通り。2023年以降、オープンソースのLLMコミュニティは大盛り上がりさ。 (Meta Llama 2 brings new opportunity for enterprises | TechTarget)Metaが公開したLlama2なんて、商用利用も可能なオープンモデルとしてリリースされたから、企業も含めて誰でも使える。MicrosoftがパートナーになってAzureクラウドで提供したり、AWSやHugging Faceでも使えるようにしたりと、広く普及するようになっている (Meta Llama 2 brings new opportunity for enterprises | TechTarget)。Futurumの調査担当Mark Beccue氏も『オープンソースはエコシステム全体にとって非常に重要。みんなに刺激を与えるから』とコメントしているよ (Meta Llama 2 brings new opportunity for enterprises | TechTarget) (Meta Llama 2 brings new opportunity for enterprises | TechTarget)。実際、Llama2の登場でLLM市場の競争が激化したとも言われている。 (Meta Llama 2 brings new opportunity for enterprises | TechTarget)」
山田: 「オープンソースだと世界中の開発者が改良に参加できますもんね。そういえば、オープンなモデルと閉じたクラウドAIって性能差は今どれくらいあるんでしょう?」
田中: 「Gartnerのアナリストによれば、現時点ではOpenAIやGoogleなどのクローズド大型モデルがまだ優位だけど、その差はLlama2のようなオープンモデルによって確実に縮まりつつあるそうだ (Meta Llama 2 brings new opportunity for enterprises | TechTarget)。要するに、“今は大規模クローズドモデルが若干リードしているけど、オープンモデルが急速にキャッチアップしている”状態だね。例えば、オープンモデルは専門分野に特化させれば、その分野では大規模モデル以上の精度を出せることも多い。実際、金融分野ではBloomberg社が自社専用のLLM「BloombergGPT」(500億パラメータ)を一から作り上げて、自社の金融タスクで他のモデルを大きく上回る成果を出したんだ ([2303.17564] BloombergGPT: A Large Language Model for Finance)。こうしたドメイン特化型の取り組みは各業界で進んでいて、“自前の小~中規模モデルで自社ニーズに最適化する”動きがあるんだよ。」
山田: 「Bloombergまで自前モデルを…!企業がモデルを自作する時代なんですね。」
オンプレミス導入で何が変わる?~企業への影響
それからしばらくして、山田さんと田中さんに上司から社内プロジェクトの相談が持ちかけられました。内容は「社内向けAIチャットボットにクラウドのLLMではなく小規模モデルを活用できないか検討せよ」というもの。二人は早速ディスカッションを始めました。
山田: 「うちの会社でもSLMをオンプレミス(自社設置環境)で使うメリットがあるか検討することになりましたね。田中さん、企業がクラウドのLLMではなく、こうしたSLMを自前で運用することで具体的に何が良くなるんでしょうか?」
田中: 「一言で言えば、コストとデータの安心感、それにカスタマイズの自由度だね。まずコスト面だけど、外部のクラウドLLMを大量に利用すると利用料がバカにならない。API経由で呼び出すたびに課金されるからね。でも自社でモデルを持てば、一度インフラを整えちゃえばあとは社内のサーバーで動かすだけで、追加の従量課金は発生しない。 (Rethinking Enterprise LLM: Secure, Cost-Effective AI)」
山田: 「確かにクラウドのLLM、例えばOpenAIのGPT-4だと、応答トークン数に応じて費用がかかりますね。具体的なコスト差ってどのくらいなんでしょう?」
田中: 「ケースバイケースだけど、極端な例を紹介しよう。AIの業界メディアによると、あるスタートアップがMetaのLlama2(オープンモデル)を自前運用してテストしたら約1200ドルのコストがかかったのに、同じテストをOpenAIのGPT-3.5で行ったらわずか5ドルで済んだそうだ (Open Source vs. Closed Models: The True Cost of Running AI)。このケースではオープンモデルの方がむしろコスト高だった。逆に、イギリスのPermutable.aiという企業がGPT-4を自社サービスでフル活用すると年間100万ドル(1億数千万円)かかる、これは自社でオープンモデルを運用する場合の20倍ものコストだと試算したという話もある (Open Source vs. Closed Models: The True Cost of Running AI)。つまり使い方次第で雲泥の差なんだ。」
山田: 「1200ドル vs 5ドル!?それはまた極端ですね…。でも逆にGPT-4ではクラウド利用が20倍高いという例もあるとは…。どういうことでしょう?」
田中: 「簡単に言うと、どの規模のモデルをどれだけ使うかで経済性が変わるんだ。小さいモデルでも、高速に大量処理しようとするとGPUマシンの費用が結構かかる。一方、OpenAIのGPT-3.5クラスはOpenAI側が大規模インフラで効率よく運用してるから、一回あたりはすごく安い (Open Source vs. Closed Models: The True Cost of Running AI)。でも、最高性能のGPT-4はAPI料金自体が高額設定だから、たくさん使うと合計は非常に大きくなる。 (Open Source vs. Closed Models: The True Cost of Running AI)それなら自前のモデルを回したほうがトータル安上がり、というケースが出てくるんだよ。」
山田: 「なるほど、用途によるわけですね。自社運用だと使い放題になるメリットがあるけど、小さいモデルでも馬鹿にならないコストがかかる場合もあると。それでもDellの分析では、クラウドよりオンプレのほうが3年間で見て2~3倍安く済むなんて報告もあるとか (Dell PowerEdge on prem GenAI)。」
田中: 「そう、Dellが試算したケースではAzure上でLLMを動かすコストは、同等のオンプレ構成の約2.72倍に達したそうだ (Dell PowerEdge on prem GenAI)。AWSでも同じ比較をしたらなんと3.8倍という数字が出たらしい (Dell PowerEdge on prem GenAI)。もちろん前提条件によるけど、長期的・大規模利用ならオンプレの初期投資を回収してお釣りがくる場合が多いということだね。」
山田: 「コスト以外ではデータ安心感って言ってましたね。」
田中: 「うん、一番のポイントとも言える。クラウドAIサービスのリスクとしてよく言われるのが、“社外にデータを送ると情報漏洩の恐れがある”という点だ。 (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)実際、Samsungでは社員が秘密のソースコードをChatGPTに入力してしまい、それが外部に漏れる事件が起きた (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)。その後Samsungは社内でChatGPT等の利用を禁止し、自社専用の生成AIを開発すると発表したんだ (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)。他にも (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)アメリカの大手銀行(バンクオブアメリカ、シティ、ドイツ銀行、ゴールドマンサックス、ウェルズファーゴ、JPMorganなど)も従業員によるChatGPT利用を制限していて、機密データの流出を警戒している (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)。」
山田: 「社外のAIに社内情報を入れるのは怖い、と…。ChatGPTに入れたデータは消せないって言いますしね。」
田中: 「その通り。Samsungの社内調査でも、社員の65%が“生成AIの利用はセキュリティリスクだ”と答えたそうだ (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)。クラウド上のAIに一度投入した情報は自分達では完全に制御できないし、削除要求しても応じてもらえるか不透明だ。 (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)最悪、サービス提供者のバグや設定ミスで他のユーザーに見えちゃう可能性もゼロじゃない。オンプレミスAIならデータは社内に留まるから、少なくとも第三者のサーバーに機密情報が流出する心配はグッと減るわけだ (Rethinking Enterprise LLM: Secure, Cost-Effective AI)。」
山田: 「情報管理部門も安心しますね。それに通信できない環境やネットワーク遮断環境でも使えますし。」
田中: 「うん、オフラインやエッジ環境でも使えるのはオンプレAIの強みだ。実はMicrosoftの事例で、日本のHeadwatersという会社がPhi-4-miniっていう小型モデルを工場などのエッジ端末に組み込んで、ネット接続が不安定な場所や機密性が特に高い現場で活用している。 (Empowering innovation: The next generation of the Phi family | Microsoft Azure Blog)ネットが頼れなくてもAIが動くし、外部に情報を出さないから安心だ、と (Empowering innovation: The next generation of the Phi family | Microsoft Azure Blog)。まさにオンプレミスAI運用の安全性を活かした使い方だね。」
山田: 「社内の閉じたネットワークや端末でAIが自己完結してくれると、クラウド利用禁止のポリシーがある現場でも導入できますね。セキュリティ面では文句なしと。」
田中: 「注意点があるとすれば、自前でAIを持つならその管理責任も自分たちにあるということかな。クラウドAIなら向こうが最新の安全対策(例えば不適切な発言をフィルタする仕組みとか)を実装してくれるけど、自前モデルだとそれも自分でやらないといけない。例えば、社員が社内LLMに変な指示を出して機密情報を引き出そうとするのを防ぐとか、偏った出力をしないよう学習データに気を遣うとかね。MicrosoftもPhiシリーズ向けにAzure AI Content Safetyっていう不適切内容フィルターの仕組みを提供してて、どんなモデルにも適用できるようにしている (Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning | Microsoft Community Hub)。そういうのもうまく活用する必要はあるだろうね。」
山田: 「セキュリティ・プライバシーの懸念はオンプレ運用でかなり緩和できるけど、モデルのガバナンスは自分達で頑張る必要がある、と。」
田中: 「そういうこと。でも総合的に見れば、社内データとAIを安心して融合できるオンプレミス運用は魅力的だよ。社外クラウドAIは便利だけど、常に“このデータ送って大丈夫かな”というリスク判断が付きまとうからね。」
未来展望:小規模モデルはどこへ向かう?
プロジェクト会議の後、山田さんと田中さんは社内カフェでコーヒーを飲みながら、SLMとLLMの今後について話を続けました。
山田: 「今日話を聞いて、小規模モデルが思った以上に使えることが分かりました。今後さらに進化したら、本当に巨大なLLMはいらなくなるんでしょうか?」
田中: 「うーん、どうだろうね。おそらく両方とも進化して共存していくんじゃないかな。OpenAIやGoogleみたいな大手は、引き続き莫大な資源を投入して“より賢くて汎用な超大規模モデル”を追求していくだろうし、実際そういうモデルは最先端の難しい問題を解くのに必要だと思う。でも同時に、Metaや各オープンソースコミュニティが主導する形で“効率の良い小型モデル”の研究もどんどん進むはずだ。例えばGoogleだって、スマホで使える音声モデルとか、小型の多言語翻訳モデルとかを研究しているしね。実際、Googleは新しい超巨大モデルGeminiを開発してるけど、それとは別にモバイル用の小型モデルも内部では作っているはずだよ。」
山田: 「競争環境としては、どうなりそうですか? OpenAI vs オープンソース連合みたいな構図でしょうか。」
田中: 「興味深いのは、Microsoftが両方に足を突っ込んでいることだね。彼らはOpenAIと提携してAzure経由でGPT-4なんかを企業に提供する一方で、自社でもPhiシリーズみたいなSLMの研究開発を進めてる。 (Empowering innovation: The next generation of the Phi family | Microsoft Azure Blog)WindowsにPhi-4-miniを組み込んで省電力で高度なAI機能を提供しようなんて動きもあるくらいだ (Empowering innovation: The next generation of the Phi family | Microsoft Azure Blog)。つまり“クラウドの大型AI”も“ローカルの小型AI”もどちらも重要と見ているわけだ。
一方、Meta(Facebook)は完全にオープン路線で来ている。Llama2を(一部制限付きだけど)無料で公開して、誰でも製品に統合できるようにした (Meta Llama 2 brings new opportunity for enterprises | TechTarget)。これには「オープンソースがAI業界の標準になってほしい」というザッカーバーグ氏の狙いがあるとも言われているね。実際ReplitのCEOは、ザッカーバーグ氏がLlama2を公開したことについて『Zuckは度胸がある』と賞賛してたし、Llama2は公開後数か月で3000万回以上もダウンロードされたらしい (Meta Made Llama 2 AI Model Open-Source Because 'Zuck Has Balls' - Business Insider)。それだけ多くの人や企業が飛びついたということだ。
対するOpenAIやGoogleは慎重だ。彼らはモデルをオープンにはしないけど、その代わり信頼性や品質でリードしようとしている。OpenAIは最近GPT-4 Turboっていうモデルを発表して、従来のGPT-4より3倍も安い価格で使えるようにしたんだ (Open Source vs. Closed Models: The True Cost of Running AI)。これなんかは明らかに、オープンソース系にユーザが流れるのを防ぐための値下げ戦略だと思うよ。価格競争も含めて、ユーザー獲得合戦が激しくなっているんだ。」
山田: 「AIモデルの世界もまるでスマホのOS戦争とかブラウザ戦争みたいですね…。」
田中: 「本当にね。あとHugging Faceも重要な存在だ。彼らはモデルそのものを作っているわけじゃないけど、オープンモデルの“プラットフォーム”を提供している。数多くのモデルがHugging Faceのリポジトリで公開・共有され、企業もそれをベースに試せるし、Hugging Face自身も企業向けに専用環境でモデルをホスティングするサービスを始めている。いわば“AIモデル界のGitHub”だね。こうした基盤があるおかげで、オープンソースモデルの普及が加速している面は大きいと思う。
今後を考えると、企業のAI投資は二極化する可能性がある。つまり、『最高峰の汎用モデルは外部のクラウドAIを使うが、それ以外の多くの社内ニーズにはオープンソースのSLMを活用する』というハイブリッド戦略だ。 (Open Source vs. Closed Models: The True Cost of Running AI)実際、多くの企業が“社内AIラボ”を作ってオープンモデルをチューンし、自社データを組み込む動きを見せているし、一方で高度なやりとりには依然としてGPT-4クラスの力が必要だからOpenAIと契約…なんて例もある。
それと、専門特化モデルにもチャンスが大きい。さっきBloombergGPTの話をしたけど、他にも医療分野とか法務分野とか、それぞれの領域に特化した言語モデルを作るプロジェクトが増えているんだ。日本企業でもNTTが日本語特化の比較的軽量なLLMを開発していたりする。 (CPUで動く超軽量モデルも、NTTが国産LLM「tsuzumi」を2024年3 …)各社が自分たちの強みのデータを使って、小さくても高性能なモデルを持つようになると、業界ごとに“小さなモデル群”が充実してくるかもしれないね。」
山田: 「そうなると、もはや“一社が最強モデルを独占”という感じではなくなりますね。みんなが得意分野のAIを持ち寄るような。」
田中: 「その通り。AIの民主化なんて言葉もあるけど、まさに小規模モデルの台頭はAI技術の民主化につながっていると思うよ。誰もが手の届くモデルでイノベーションを起こせるようになる。それを支えるコミュニティや企業もどんどん出てきている。例えば、スタートアップのMistral AIは創業直後に1億ドル以上の資金調達をして話題になったけど、彼らのミッションは“小さくても賢いモデルで業界をリードする”ことだしね。オープンな取り組みに投資マネーも集まっている。
一方、大規模モデルの最先端競争も続くだろうね。より少ないデータで学習できる新原理の研究とか、画期的なアルゴリズムの発見とかがあれば、また局面は変わるかもしれないし。Googleのエンジニアが『OpenAIの秘密主義はAI研究を5年停滞させた』なんて批判したりもしてるけど、逆に言えばそれくらいオープンvsクローズドの思想の違いが大きくなっているんだ。 (Meta's open source approach to AI puzzles Wall Street, techies love it)」
山田: 「私たちとしては、どっちに振り切るというより上手に両方使い分けるのが現実的なんでしょうね。」
田中: 「うん、経営層もそこを理解してくれるといいね。『とりあえず何でもChatGPT』ではなく、社内で回せるところはSLMで、高度な部分だけクラウドLLMに任せるとかね。幸い、この頃は例えばAzureやAWSのクラウド上でもLlama2みたいなオープンモデルを自社専用で動かせるサービスが出てきている。クラウドに置くけどデータは外に出さず自社テナント内だけで処理できる形だ。そうやってクラウド提供側もニーズに合わせて柔軟になってきているから、選択肢は増えているよ。」
山田: 「色々教えていただいてありがとうございます!小規模言語モデルがこんなにも可能性に満ちたものだとは知りませんでした。なんだか、“小さいけれど世界を変える”存在になりそうですね。」
田中: 「うん、SLMはこれからの企業AI戦略のキーになるかもしれない。『小さなモデルが起こす大きな変化』…なんてね。僕らも社内で上手に活用して、コストもリスクも減らしつつAIの恩恵を最大化できるように頑張って提案しよう!」
二人はそう言って笑い合い、これから始まる社内プロジェクトへの意気込みを新たにするのでした。
参考文献・情報源
- Microsoft Tech Community: 「Introducing Phi-4: Microsoft’s Newest Small Language Model…」 (Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning | Microsoft Community Hub) (Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning | Microsoft Community Hub)他
- Microsoft Azure 公式ブログ: 「Empowering innovation: The next generation of the Phi family」 (Empowering innovation: The next generation of the Phi family | Microsoft Azure Blog) (Empowering innovation: The next generation of the Phi family | Microsoft Azure Blog)他
- TechCrunch: 「Samsung bans use of generative AI tools like ChatGPT…」 (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch) (Samsung bans use of generative AI tools like ChatGPT after April internal data leak | TechCrunch)
- BloombergGPT 論文 (arXiv:2303.17564) ([2303.17564] BloombergGPT: A Large Language Model for Finance)
- TechTarget: 「Meta Llama 2 brings new opportunity for enterprises」 (Meta Llama 2 brings new opportunity for enterprises | TechTarget) (Meta Llama 2 brings new opportunity for enterprises | TechTarget)
- AI Business: 「Open Source vs. Closed Models: The True Cost of Running AI」 (Open Source vs. Closed Models: The True Cost of Running AI) (Open Source vs. Closed Models: The True Cost of Running AI) (Open Source vs. Closed Models: The True Cost of Running AI)
- Rackspaceブログ: 「LLMs vs. SLMs」 (Large Language Models(LLMs) vs. Small Language Models(SLMs)| Rackspace Technology) (Large Language Models(LLMs) vs. Small Language Models(SLMs)| Rackspace Technology)
- 他、RedditやBusiness Insiderでの有識者コメント (Meta Made Llama 2 AI Model Open-Source Because 'Zuck Has Balls' - Business Insider)等。