ChatGPTのDeep Research(AI)での出力結果をそのまま掲載しています。ChatGPTのDeep Researchはハルシネーション(誤った情報の生成)が少なくなるよう調整されていますが、あくまで参考程度に読んでください。当記事は検索エンジンに登録していないため、このブログ内限定の記事です。
「テキストで指示したら、その通りの画像をAIが描いてくれたら…?」
そんな夢のような体験を実現するのが、Googleが提供する新モデル 「Gemini 2.0 Flash Experimental」 です。これはチャットしながらネイティブに画像を生成・編集できる実験的AIモデルで、2025年3月に開発者向けプレビュー版として公開され、大きな話題を呼んでいます (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master) ([B! 人工知能] Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更 (ITmedia AI+))。テキストによるやり取り(対話)で直接画像を作り出せるこの技術は、「ChatGPTのように会話できて、しかもプロのイラストレーターのように絵も描けるAI」とも言えるでしょう。
(テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master) 例えば、上の画像は何の変哲もないダイニングテーブルの写真です。その右側にユーザーが「Can you add some flowers to the table?(テーブルの上に花を飾ってもらえますか?)」と指示を出すと、Gemini 2.0 Flashがテーブル上に花瓶と花が載った画像を返してくれました (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。このように、元の画像に対する変更指示も、ただ文章で伝えるだけで瞬時に実行してくれるのです。写真編集ソフトを使わずとも対話形式で画像を加工できる点は、初心者にも直感的で魅力的ですよね。

では、この“Gemini 2.0 Flash Experimental”とは具体的に何者で、どんな仕組みで画像を生成しているのでしょうか?そして既存の画像生成AIと比べて何が優れているのか?本記事では、その概要から技術的特徴、活用事例、さらに今後の可能性まで、対話形式の物語を交えながら初心者にも分かりやすく徹底解説します。
概要:Gemini 2.0 Flash Experimentalとは?
まずはGemini 2.0 Flash Experimentalの全体像を押さえましょう。Gemini(ジェミニ)とは、Googleが開発した次世代の大規模言語モデル(LLM)ファミリーの名称です。中でもGemini 2.0 Flashは、2024年12月に発表された最新モデルで、テキストだけでなく画像など複数のデータ形式を扱える「マルチモーダルAI」です (グーグル「Gemini 2.0 Flash Thinking」とは? o1対抗推論モデルの「スゴイ実力」 |ビジネス+IT) (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。従来はテキスト応答が中心でしたが、Experimental版ではついに会話の中で直接画像を生成・編集する機能が搭載されました (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。
Gemini 2.0 Flash Experimentalは2024年末に一部テスター向けに限定公開された後、2025年3月12日にGoogle AI Studio上で開発者なら誰でも試せるプレビューとして解禁されました (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog)。無料で利用可能なこともあり、公開直後から多くのユーザーが実際に画像生成を試し、その高い表現力にSNS上でも驚きの声が相次いでいます ([B! 人工知能] Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更 (ITmedia AI+))。例えば「画像のアングルを変えてほしい」「この写真に日本語の文字を入れて」といった要望にも違和感なく応えてくれるとの報告があり、その完成度の高さが話題になりました ([B! 人工知能] Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更 (ITmedia AI+))。
では、「ネイティブに画像生成」とはどういう意味でしょうか?実はこれ、一つのAIモデルがテキストと画像の両方を直接生成できることを指します。多くの既存サービスでは、チャットAI(テキスト担当)と画像生成AI(画像担当)は別々で、裏側で連携して動いていました (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。たとえばChatGPTで画像を出力する際は、チャットAIが文章を解釈し、それを別の画像生成モデル(例:OpenAIのDALL·E)に渡す必要があったのです。しかしGemini 2.0 Flashではテキストも画像も一つの統合モデル内で処理できるため、ユーザーの指示に対してより正確かつ一貫性のある応答が可能になっています (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。これは米国の大手テック企業としても初の試みであり、競合他社に対して一歩リードした革新的ポイントです (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat) (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。
まとめると、Gemini 2.0 Flash Experimentalは「チャットしながら画像も作れるGoogleの最新AIモデル」です。その場で会話の文脈を理解し、必要に応じてテキスト回答も画像回答も返せる柔軟さが特徴となっています。それでは次に、このモデルがどのような技術によってそれを実現しているのか、詳しく見ていきましょう。
技術解説:どうやって画像を描いているの?
Gemini 2.0 Flash Experimentalが魔法のように画像を生み出す裏側には、最先端の生成AI技術が詰まっています。ここでは技術的なポイントをいくつかに分けて解説します。
1.単一モデルでテキスト&画像を処理する統合アーキテクチャ
最大の特徴は前述の通り、一つのAIモデル内でテキストと画像の生成を完結している点です (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。これによりテキストから画像への変換がシームレスになり、解釈の齟齬が減ります。具体的には、Gemini 2.0 Flashは大規模言語モデルの高度な推論力と、画像生成モデル(GoogleのImagen 3)の描画力を組み合わせたような構造になっています (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat) (「Gemini」アプリの頭脳が最新モデル「Gemini 2.0 Flash」にアップグレード - 窓の杜)。ユーザーの入力をまず言語モデル部分が深く理解・分析し、それを基に画像生成部分が絵を描き出す、という流れです。以前のGemini 1.xでもGoogleの画像生成モデル「Imagen」を組み合わせたシステムはありましたが、Flash 2.0ではそれがより密接に結合し、事実上ひとつの脳で両方をこなす“ネイティブ”実装になったと考えると分かりやすいでしょう (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。
このアーキテクチャの利点は、テキストと画像の相互理解が深いことです。例えば「黒い猫がソファで眠っている写真に、同じ猫が遊んでいるイラストを並べて」といった複雑な指示も、一つのモデル内で処理されるため統一感のある結果が期待できます。Gemini 2.0 Flashは文章の意味だけでなく、画像の内容や文脈も総合的に把握できるため、テキストと画像を組み合わせた高度なタスクが可能なのです (グーグル「Gemini 2.0 Flash Thinking」とは? o1対抗推論モデルの「スゴイ実力」 |ビジネス+IT) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。これはマルチモーダルAIならではの新次元の能力と言えます。
2.生成画像の特徴:高品質な描画と一貫性ある表現
①リアルで多彩な描写力:Gemini 2.0 Flashの画像生成エンジンは、Googleが誇る最新モデル「Imagen 3」をベースにしており、より豊かなディテールと質感表現が可能です (「Gemini」アプリの頭脳が最新モデル「Gemini 2.0 Flash」にアップグレード - 窓の杜)。写真のような写実的画像から、イラスト調・ピクセルアート調などスタイルも自在に描き分けられます (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。実際、社内評価では視覚的な品質やプロンプト忠実度で最高評価を獲得しているとのこと (〖Google〗ImageFX(Imagen3)とは?使い方や料金、商用利用について解説! | AI総合研究所)。例えば「映画のワンシーンのような猿(サル)がローラースケートをしているところを描いて」と指示すれば、映画の一コマのように背景まで緻密に描かれたサルの画像が得られます。
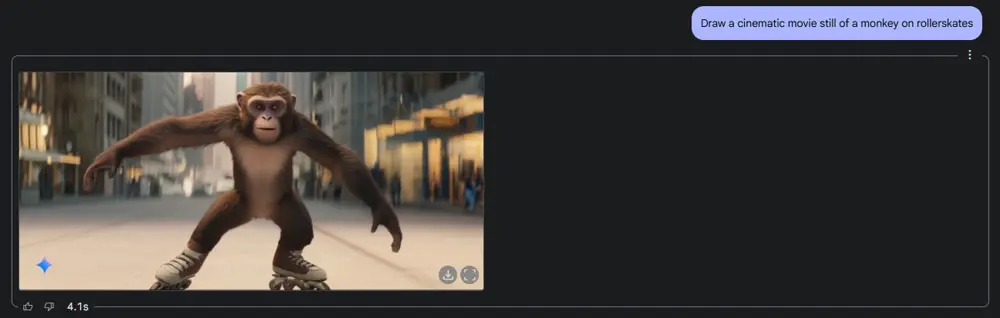
(Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)これはGemini 2.0 Flashがテキストから直接生成した画像の一例です。ユーザーが「映画のワンシーン風に、ローラースケートを履いたサルを描いて」と依頼すると、街中でローラースケートをするサルのリアルな画像が数秒で生成されました(上図) (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)。わずかな会話のやり取りでここまで具体的で高品質なビジュアルが出てくるのは驚きですよね。しかも、生成にかかった時間はわずか約4秒(画面左下に表示)。モデル名の“Flash”が示すように、応答速度も非常に高速で、待ち時間のストレスが少ないのも魅力です。
②文脈を踏まえた一貫性:Gemini 2.0 Flashは会話の文脈やストーリーを考慮して画像を作れるため、複数の画像にまたがる整合性が保たれます (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog)。これは他の画像生成AIには真似しにくい強みです。例えば物語の挿絵を順番に生成する場合、普通なら各コマごとにプロンプトを調整して同じキャラクターの見た目を維持するのは困難でした。しかしGeminiでは一度会話に登場したキャラクターや背景設定を内部で記憶し、次の画像生成に反映してくれるのです (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。実際にユーザーが白猫を主人公にした童話の挿絵を生成したところ、どの場面でも同じ白猫が一貫して登場し、画風も統一されていたと報告されています (AI 生成童話:星のかけらを探して|七誌)。これは従来の画像生成では難しかった点であり、長いストーリー漫画や絵本への応用にも期待できる革新的なポイントです (AI 生成童話:星のかけらを探して|七誌)。
③テキスト(文字)の正確な描画:もう一つ注目すべき技術革新が、画像内の文字描画能力の向上です。従来の画像生成AIでは、看板やポスター内の文字がぐにゃぐにゃに崩れたり、意味不明なアルファベット列になってしまうことが多々ありました。しかしGemini 2.0 Flashでは内部で文字情報を扱えるため、長い文章や正確な単語も読み取れるレベルでレンダリングできます (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。Google社による内部ベンチマークでも競合モデルを上回る文字レンダリング性能が確認されており (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)、例えば広告画像や招待状のデザインなど、文字情報が欠かせないビジュアル作成にも十分使える品質になっています (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。「SALE 50% OFF」といった看板をAIに描かせてもちゃんと判読可能な文字になる、というのは嬉しい進歩ですね。
④豊富な世界知識と論理推論:Gemini 2.0 Flashは単なる画像生成に留まらず、言語モデル由来の広範な知識や推論力を画像作成に活かせます (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。これにより「与えられたテーマに対して最もふさわしい情景」を考えて描くことが可能です。他の画像モデルでは辻褄が合わない内容になってしまうような場合でも、Geminiは現実世界の知識を参照して調整してくれるのです (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog)。例えばレシピ記事の挿絵を自動生成する際、料理名だけでなく実在する食材の見た目や調理法まで踏まえたリアルな画像表現が期待できます (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。また古い白黒写真をカラー化する場合にも、歴史的な背景知識を考慮して「当時実際にあり得た服の色や街並み」を推測して着色するといった応用も可能でしょう (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。このように賢い頭脳と画才を併せ持つのがGemini 2.0 Flashの技術的なスゴさなのです。
3.他の画像生成AIとの違い
上述した技術特徴からも明らかなように、Gemini 2.0 Flash Experimentalは既存の画像生成AIと一線を画しています。主な違いを整理してみましょう。
- (A)統合モデル vs. 分離モデル: 最大の違いは、一体型のマルチモーダルモデルであることです。他サービスではテキスト担当AIと画像担当AIが別々でしたが、Geminiは一人二役をこなします (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。これにより解釈の精度や反応の一貫性が向上しており、実際ユーザーからも「指示通りの絵がブレずに出てくる」と評価されています ([B! 人工知能] Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更 (ITmedia AI+))。
- (B)対話的な画像編集: Geminiはチャットの履歴を踏まえて段階的に画像を修正・更新できます (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。例えば一度生成した画像に対し「もう少し明るくして」と追加指示を出すと、その場で明るさを調整した新しい画像を返してくれるのです (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。従来の画像生成AIでは、一枚ごとにプロンプトを書き換えて再生成する必要があり、前後の繋がりを保つのが難しいものでした。Geminiならユーザーと会話しながら同じ画像を洗練させていくことが可能で、まるで隣にデザイナーが座ってリアルタイムで修正してくれているような感覚です (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。
- (C)高度な画像編集能力: 単なる生成だけでなく、既存画像の高度な編集もGeminiの得意技です。ユーザーがアップロードした写真に対し、「この部分を消して別のオブジェクトに差し替えて」と指示すれば、自然な形で加工してみせます (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。例えば人物の顔写真を与えて、「頭にスパゲッティの入ったボウルを載せて」と冗談で頼めば、本当に頭にパスタの載ったユニークな合成画像が生成される、と海外のユーザーが実演しています (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。さらには顔写真から全身像を想像で補完する(顔だけの写真を与えて「全身を写して」と頼むと、同じ人物の全身を生成する)といった高度なアウトペインティングも可能で、その人物らしさを保ったまま見事に描き足してみせました (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。このような柔軟な画像編集は、従来は高度なフォト編集スキルが必要でしたが、Geminiなら誰でもチャットで簡単に実現できます。
- (D)文字入り画像の作成: 前述の通り、Gemini 2.0 Flashはテキスト入りの画像(ポスターやチラシ等)も破綻なく作れます (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。DALL·Eなど他の生成AIでは文字が苦手で、「HELLO」が「HERLO」に崩れる…といった例が有名でした。Geminiではその点大きく改善されており、文章量の多い画像や複雑なレイアウトでもかなり人間に近いレベルで再現します (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。これはGoogleが以前公開した文字特化の画像AI Ideogram に匹敵する性能との声もあります(※Ideogramは独立モデルでしたが、Geminiはそれを内包してきた形です)。
- (E)安全性とフィルタリング: Googleは生成AIの安全対策にも注力しており、Gemini 2.0 Flashによる画像にはデジタル透かし「SynthID」が自動で埋め込まれます (〖Google〗ImageFX(Imagen3)とは?使い方や料金、商用利用について解説! | AI総合研究所)。これはパッと見では分かりませんが、後から画像データを解析することでAI生成と判別できる目印で、不正利用防止に役立ちます。また不適切な画像を生成しないようコンテンツフィルタも強化されており、暴力・わいせつや他人の顔写真の無断生成などは禁止されています (〖Google〗ImageFX(Imagen3)とは?使い方や料金、商用利用について解説! | AI総合研究所)。実際ユーザーからは「人物を含む画像はフィルタで弾かれやすい」との指摘もあり、安全面に配慮した設計となっているようです (AI 生成童話:星のかけらを探して|七誌)。そのため現状、人間キャラクターが登場する漫画制作には使いにくい面もありますが、裏を返せば悪用リスクを下げた堅実な実装とも言えるでしょう。
以上が主な技術的特徴・他モデルとの比較です。総合すると、Gemini 2.0 Flash Experimentalは統合AIならではの賢さと、画像特化AIに匹敵する描画力を兼ね備えた画期的モデルであることが分かります。ただし現時点ではまだ「Experimental(実験版)」であるため、生成結果にばらつきが出ることもあります。実際に使ってみたユーザーからは「毎回同じ指示でも少し違う画像が出るので、うまくいかない時は再実行すると良い」といった報告もあります (Google AI StudioのGemini 2.0 Flash Experimentalで画像編集を試す|まゆひらa) (Google AI StudioのGemini 2.0 Flash Experimentalで画像編集を試す|まゆひらa)。このあたりは研究段階ゆえの不安定さですが、今後の改善でさらに完成度が上がっていくでしょう。
活用事例:どんなシーンで使えるの?
では、このGemini 2.0 Flash Experimentalは具体的にどのように活用できるのでしょうか。ここからは、想定される利用シーンや実際に試された事例をいくつか紹介します。企業での応用から個人のクリエイティブ利用まで、幅広い可能性があります。
1.物語作りや教育:AIが即席イラスト付きストーリーを生成
創作の分野では、Gemini 2.0 Flashは強力な相棒になりえます。例えば絵本作家や教師のケースを考えてみましょう。絵本作家の卵であるアリスさんは、ある日「白い子猫が主人公のおとぎ話」を思いつきました。彼女はGeminiにこう語りかけます。
- アリス:「森に住む白い子猫が星のかけらを探しに旅に出るお話を考えています。まずはその子猫が森で星のかけらを見つけるシーンを書いて、挿絵も描いてもらえますか?」
- Gemini:(物語の第1シーンの文章と、森の中で輝く星のかけらを見つめる白い子猫のイラストを生成)
Geminiはわずかな時間でシーン1の文章と挿絵を提示しました。さらにアリスさんが続きを促します。
- アリス:「次のシーンでは、子猫が星のかけらを持って町に行き、夜空に返す場面をお願いします」
- Gemini:(物語の第2シーンの文章と、夜空に星のかけらを放つ子猫の挿絵を生成)
このように、テキストと画像を交互に組み合わせたストーリーテリングが非常にスムーズに行えます (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)。実際、あるユーザーは「3歳児向けの絵本を作って。テーマは日本に遊びに来たギリシャ神話の12神。各シーンごとに画像を描いて」と一度にプロンプトを投入し、5シーン分の物語と挿絵を一撃で生成させることにも成功しています (AI 生成童話:星のかけらを探して|七誌)。出来上がった画像の画風も全シーンで統一され、キャラクターも変わらず登場しており、「本当に一発の指示で絵本ができてしまった!」と驚く声が上がりました (AI 生成童話:星のかけらを探して|七誌)。
このような活用は教育現場でも有用でしょう。先生がGeminiに「今日の理科の授業で使う太陽系のイラストを作って」と頼めば、児童向けに分かりやすい太陽系モデル図が生成されるかもしれません。あるいは子供たち自身がGeminiと対話しながら物語を作る、なんて学習プロジェクトも面白そうですね。文章を書くのが苦手な子でも、AIが絵を付けてくれることでモチベーションが上がる効果も期待できます。
2.デザイン・マーケティング:対話で画像編集&コンテンツ制作
ビジネス分野でも、Gemini 2.0 Flash Experimentalは様々な使い道があります。特にデザイン制作やマーケティングでは、試作段階のスピードアップや発想支援に役立つでしょう。
例えば広告バナーを作るシナリオを考えます。とあるカフェの宣伝担当ボブさんは、新メニューの告知チラシを作りたいとします。彼はGeminiにカフェの写真を送り、「この店内写真を使って、新作クロワッサンの宣伝ポスターを作って」と依頼しました。Geminiは店内の写真に新作クロワッサンの画像を合成し、「新登場!焼きたてクロワッサン」と日本語でタイトル文字が入ったポスター風画像を生成してくれました。さらに細部の調整も会話で行います。
- ボブ:「クロワッサンの上にスライスアーモンドを乗せてみて」
- Gemini:(クロワッサンにトッピングを追加した画像を再生成 (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master))
- ボブ:「もっとチョコソースをかけて艶を出して」
- Gemini:(チョコソースの量を増やし光沢感が出るよう調整 (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master))
- ボブ:「いいね!最後に『期間限定』の文字バナーも入れて」
- Gemini:(画像の上部に「期間限定!」の目立つテキストを追加 (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat))
このように、対話形式で細かなデザイン修正を重ねていけるのが大きな利点です。従来ならデザイナーとの打ち合わせと何度もの修正作業が必要だった工程が、AIとの直接対話でどんどん進んでいきます。特にGeminiは人物の表情を変えるなど高度な編集もテキスト指示で可能なので (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)、例えばモデルの写真の表情を「もう少し笑顔にして」と変えて雰囲気を調整するといった芸当もお手の物です。実務では、商品写真の背景差し替えや色味の変更、レイアウト案出しなど、マーケ担当者が欲しい画像素材をスピーディーに生み出すのに役立つでしょう。
実際の事例として、ある開発者は自社の商品カタログ用に、Geminiを使って様々な背景バリエーションの製品写真を生成する実験をしています。白バックの製品写真を入力し、「木目調のテーブルの上に置いた雰囲気で」「カフェ風の背景で」などと指示を与えると、製品がまるで異なる場所で撮影されたかのような画像が次々と得られました。これらはSNS投稿用画像としてもすぐ使えるクオリティで、プロのカメラマンに追加撮影を頼むコスト削減につながりそうだといいます。
3.クリエイター・開発者の新たなツール:発想支援からアプリ開発まで
Gemini 2.0 Flash Experimentalはクリエイターや開発者にとって強力な新ツールにもなります。その対話型の特性から、アイデア出しや試作段階で特に力を発揮するでしょう。
イラストレーターのカレンさんは、新キャラクターのデザインにGeminiを活用しています。まず「森のエルフの少女で、魔法の弓矢を持っているキャラクターをデザインして」と依頼すると、Geminiは数パターンのエルフ少女のイラストを提示しました。カレンさんはその中から一つを選び、「この子の服をもう少し豪華にして」「髪型をショートカットに変更して」と要望を重ねます。Geminiは都度画像をアップデートし、理想のキャラクタービジュアルに近づけていきます。最終的に得られたイラストを元にカレンさん自身が細部を描き込み、オリジナルキャラクターが完成しました。「ラフスケッチを一緒に描いてくれる相棒ができた感じ」と彼女は語っています。
一方、アプリ開発者にとっては、Gemini 2.0 Flash Experimentalは新機能を組み込むチャンスです。GoogleはGeminiをAPI経由でも提供しており、プログラマは自分のアプリケーションにこの画像生成能力を統合できます (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog)。例えばチャットボットにGeminiを組み込めば、ユーザーが「部屋のレイアウト案を絵に描いて」と要求した際に、その場で簡単なレイアウト図を生成して見せる、といったことも可能になります。またゲーム開発では、プレイヤーがテキストで入力した内容からゲーム内の看板画像やマップを自動生成するといったダイナミックな演出も考えられます。
実際、ある開発者はNext.js(ウェブアプリ向けフレームワーク)でGemini APIを呼び出すサンプルを公開しており、わずか数行のコードでテキストから画像を得ることができると報告しています (Logan Kilpatrick - X)。これにより、従来別々に扱っていた「文章生成AI」と「画像生成AI」を単一の統一APIで扱えるようになるため、開発フローがシンプルになります (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。創作系アプリ、デザイン補助ツール、教育用ソフトなど、応用範囲は非常に広いでしょう。
以上、Gemini 2.0 Flash Experimentalの活用シーンを見てきました。お絵描きからビジネス資料作りまで、まさに「テキストも画像も一気通貫」でこなす様子がイメージできたのではないでしょうか (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)。
今後の応用可能性とトレンド予測
Gemini 2.0 Flash Experimentalがもたらした衝撃は、AI業界全体のトレンドにも影響を与えています。この章では、今後の展開や応用可能性について考えてみましょう。
まず、マルチモーダルAIの加速です。Geminiが示したように、今後のAIモデルはテキストだけでなく画像・音声・動画など複数のモードを統合的に扱う方向に進むと予想されます。実際、「一つのモデルで何でもできるオムニモーダルなAI」の時代が目前に迫っているとも言われています (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)。これまでバラバラだった機能をつなぎ合わせて使っていたのが嘘のように、単一のAIがあらゆる創作・情報処理をこなす未来が来るかもしれません (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)。Gemini 2.0 Flashはその先駆けであり、今後はOpenAIなど他社も追随して同様の統合モデルを公開してくるでしょう (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master) (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)。実際、OpenAI側も「ネイティブな画像生成機能を開発中で、期待して待っていてほしい」とコメントしており、競争は激化しそうです (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)。
また、Geminiの技術が洗練されれば、私たちの身近なサービスへの組み込みも進むでしょう。たとえば将来的には、スマートフォンのGoogleアシスタントにGeminiが搭載され、音声で「新しい家具に合う部屋のレイアウトを見せて」と頼むとその場でレイアウト図を表示してくれる、といったことも十分考えられます。実際のニュースでも、GoogleアシスタントをGeminiベースにアップグレードする計画が報じられており (Gemini – omake AIメディア)、AIチャットがテキスト回答だけでなく視覚的な回答を返す時代がすぐそこまで来ています。
クリエイティブ業界の変革も大きなトピックです。画像生成AIの進化は、デザイナーやイラストレーターの作業スタイルを変える可能性があります。Geminiのようなツールを使いこなすことで、ラフ制作やアイデアスケッチの工程が爆速になり、人間クリエイターはより高度な部分(構図のブラッシュアップや独自スタイルの描き込み)に注力できるようになります。つまりAIと人間の協業が今以上に進むでしょう。一方で、簡単なバナー作成などはAIが自動化してしまうため、一部の単純作業系デザイン業務は縮小するかもしれません。クリエイターにとっては、AIを味方につけて創造性を発揮することがますます重要になるでしょう。
さらに先を見れば、動画生成や3Dモデリングへの波及も考えられます。現在Geminiは静止画までですが、将来的に動画を数フレーム生成して繋げることでショートアニメを作ったり、3D空間内のオブジェクト配置を提案したりと、よりリッチな生成が可能になるかもしれません。実際、競合のMeta社などはテキストから動画を作るAIの研究も進めていますし、Googleも過去にImagen Videoというデモを公開しています。Geminiシリーズが成長していけば、会話で動画編集・生成する日も遠くないでしょう。
最後に、ユーザーコミュニティのフィードバックも重要です。Experimental版はあくまで試用段階であり、開発者コミュニティから寄せられるフィードバックが今後の正式版に反映されていきます (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog)。幸い多くのユーザーがSNSやフォーラムで活発に事例共有や意見交換をしており、Googleもそれらを注視しているようです。ユーザーの創意工夫によって新たな使い道が発見され、モデル側の改良でそれが正式にサポートされる、といった相乗効果が期待できます。
総括すると、Gemini 2.0 Flash Experimentalは「対話型で画像を扱うAI」の先駆けとして登場し、今まさに多方面で試され始めたところです。その実力は既に高く評価されていますが、完成版に向けさらにブラッシュアップされれば、私たちの創作や仕事の風景を一変させる可能性を秘めています (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)。まさに“これからが本番”の技術と言えるでしょう。AIとおしゃべりしながら、一緒に絵を描いたり写真を編集したりする——そんな未来が現実のものとなりつつある今、ぜひ一度このGemini 2.0 Flash Experimentalを体験してみてはいかがでしょうか。その便利さと楽しさに、きっと驚くはずです。
参考文献:
- 【3】Google Developers Blog: Experiment with Gemini 2.0 Flash native image generation(2025年3月12日) (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog) (Experiment with Gemini 2.0 Flash native image generation - Google Developers Blog)
- 【23】ITmedia NEWS: Google「Gemini」の画像生成がハイレベルと話題に(2025年3月14日) ([B! 人工知能] Google「Gemini」の画像生成がハイレベルと話題に チャット1つで写真のアングルを違和感なく変更 (ITmedia AI+))
- 【27】ビジネス+IT: グーグル「Gemini 2.0 Flash Thinking」とは?(2025年3月17日) (グーグル「Gemini 2.0 Flash Thinking」とは? o1対抗推論モデルの「スゴイ実力」 |ビジネス+IT)
- 【30】窓の杜: 「Gemini」アプリの頭脳が最新モデル「Gemini 2.0 Flash」にアップグレード(2025年1月31日) (「Gemini」アプリの頭脳が最新モデル「Gemini 2.0 Flash」にアップグレード - 窓の杜)
- 【48】VentureBeat: Google’s native multimodal AI image generation in Gemini 2.0 Flash…(2025年3月12日) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat) (Google's native multimodal AI image generation in Gemini 2.0 Flash impresses with fast edits, style transfers | VentureBeat)
- 【49】AI総合研究所: Google ImageFX(Imagen3)とは?(2025年3月10日) (〖Google〗ImageFX(Imagen3)とは?使い方や料金、商用利用について解説! | AI総合研究所) (〖Google〗ImageFX(Imagen3)とは?使い方や料金、商用利用について解説! | AI総合研究所)
- 【52】note(七誌): AI生成童話:星のかけらを探して(2025年3月13日) (AI 生成童話:星のかけらを探して|七誌) (AI 生成童話:星のかけらを探して|七誌)
- 【55】GPTマスター(ブログ): Gemini 2.0 Flashが実現する新時代のAI(2025年3月13日) (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master) (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master) (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master) (テキストも画像も一気通貫!Gemini 2.0 Flashが実現する新時代のAI - GPT Master)
- 【39】Why Try AI (Substack): Gemini 2.0 Flash Makes Mediocre Images…But That’s Not The Point!(2025年3月13日) (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!) (Yes, Gemini 2.0 Flash Makes Mediocre Images…But It Can Hide the Elephant!)