ChatGPTのDeep Research(AI)での出力結果をそのまま掲載しています。ChatGPTのDeep Researchはハルシネーション(誤った情報の生成)が少なくなるよう調整されていますが、あくまで参考程度に読んでください。当記事は検索エンジンに登録していないため、このブログ内限定の記事です。
Llama4の概要 – Metaが公開した最新オープンウェイトAIモデル
Llama4(LLaMA 4)は、2025年4月5日にMeta(旧Facebook)から正式発表された最新の大規模言語モデル(LLM)ファミリーです (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。Llamaシリーズとして初めてマルチモーダル(複数モード対応)をネイティブにサポートし、さらにMetaとして初のMixture of Experts(MoE)アーキテクチャを採用した点で画期的です (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。Llama4は、先行モデルLlama2・Llama3の路線を引き継ぎつつ大幅な性能向上を果たし、モデルの重み(パラメータ)を公開する「オープンウェイト」戦略を継続しています。これにより世界中の研究者・開発者がモデルを入手し、自由に研究・応用できるようになっています(ただし商用利用には一部制限あり。詳細は後述) (LLAMA 4登場:1000万トークンのコンテキスト機能搭載!|AGIに仕事を奪われたい) (meta-llama/Llama-4-Maverick-17B-128E · Hugging Face)。
Llama4ファミリーは用途や規模の異なる3種類のモデルで構成されます (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。それぞれ「Llama4 Scout」、「Llama4 Maverick」、「Llama4 Behemoth」と呼ばれ、モデルサイズや能力に違いがありますが、共通してLlama4世代の先進技術基盤(マルチモーダル対応、MoEアーキテクチャなど)を共有しています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。以下に各モデルの概要をまとめます。
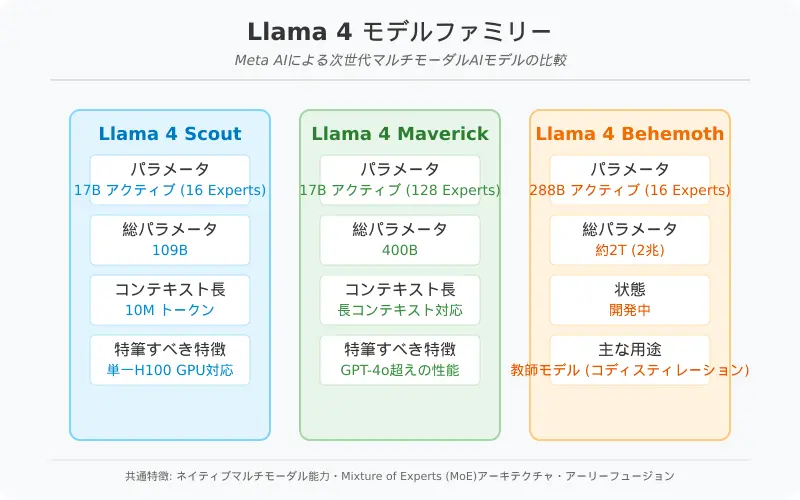
- Llama4 Scout(スカウト) – アクティブ17B(170億)パラメータ、16 experts(総パラメータ109B=1090億)を持つモデル (Llama 4 の概要|npaka)。ファミリー中最も小型で、Int4量子化を用いることで単一のNVIDIA H100 GPUに収まる実用性も備えています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。それでいて業界最高クラスの性能を発揮するよう設計されており、特に後述する1000万トークンという飛び抜けて長いコンテキスト長をサポートする点が注目されています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。マルチモーダル能力も高く、テキストと画像を組み合わせた高度な推論や、大量のコード解析なども可能です (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。
- Llama4 Maverick(マーベリック) – アクティブ17Bパラメータ、128 experts(総パラメータ400B=4000億)を持つモデル (Llama 4 の概要|npaka)。Scoutと同じアクティブパラメータ規模ながらMoE専門家の数を増やし、より大規模な知識容量を実現しています。コンテキスト長は最大100万トークンに対応し(Scoutより短いものの従来比で非常に長大) (Llama 4 の概要|npaka)、汎用LLMとして高品質かつ低コストなソリューションを提供します (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。実際、前世代トップクラスのLlama3.3 70Bモデルと比較しても高い性能を発揮し、OpenAIのGPT-4 TurboやGoogleのGemini 2.0 Flashなど同等モデルを各種ベンチマークで上回ったと報告されています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。サイズは大きいものの、後述のMoEにより効率的な推論を可能としており、必要に応じて単一H100での動作や分散インフラでの展開も柔軟に行えます (Llama 4 の概要|npaka)。
- Llama4 Behemoth(ビヒモス) – アクティブ288B(2880億)パラメータ、16 experts(総パラメータ約2兆!)を誇る超巨大モデル (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。現在も訓練中のプレビュー段階であり、一般提供はされていません(2025年4月時点)。その性能は一部ベンチマークでGPT-4.5やAnthropic Claude 3.7など世界最高峰モデルを上回るとされ (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)、文字通り次元の違うモデルです。ただしBehemothは他のモデルの「教師」として位置づけられており、これを用いてScoutやMaverickへ知識蒸留(コ・ディスティレーション)することで、小型モデルでも高性能を引き出すことが主目的とされています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。言わば研究開発用の実験的モデルで、直接プロダクトに組み込むよりも将来のモデル進化の土台としての役割が大きいようです。
以上がLlama4ファミリーのラインナップです。特に注目すべきは、小型モデルのScoutでいきなり1000万トークンという破格の長文コンテキスト対応を実現した点と、中型モデルのMaverickでGPT-4クラスを凌駕する性能をうたっている点でしょう (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。次章では、これらを可能にしたLlama4の革新的な技術的特徴について詳しく解説します。
Llama4の革新的な特徴 – 1000万トークンの長大コンテキストとMoEマルチモーダル技術
Llama4がこれほど注目を集める理由は、その桁外れのコンテキストウィンドウ長と先進的なアーキテクチャにあります。それぞれ初心者向けに噛み砕いて説明しましょう。
業界最高1000万トークンのコンテキスト長
Llama4 Scoutモデルがサポートする1000万トークン(10M)のコンテキストウィンドウは、現行のLLMの中で突出した長さです (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。コンテキストウィンドウとは、モデルが一度に処理できるテキストの長さ(履歴を含む)を指します。例えばChatGPTのGPT-4モデルは最大でも数万トークン程度(GPT-4の標準は8Kトークン、拡張版で32Kトークン)でした。またAnthropicのClaude 2ですら100K(10万)トークン前後、Claude 3でもデフォルト20万トークン、特定用途で最大100万トークンまで拡張予定という段階でした (Claude (language model) - Wikipedia)。1000万トークンという数字は、既存の常識を一桁以上打ち破る圧倒的な長さなのです (LLAMA 4登場:1000万トークンのコンテキスト機能搭載!|AGIに仕事を奪われたい)。
1000万トークンは日本語文章に換算すると、およそ数億文字に相当します。極端な例では百科事典並みの分量の文書を一度にモデルに与えて解析させることも理論上可能です。これにより、複数の長大なドキュメントを跨いだ要約、数年分に及ぶユーザーログの横断分析、巨大なコードベース全体のバグ検出やリファクタリングなど、これまでは分割や特殊な工夫なしには困難だったタスクが直接実行できるようになります (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。実際、Metaは「干し草の山から針を見つける(Needle in a Haystack)テスト」のような超長文検索タスクや、1000万トークン規模のコード上での言語モデル評価においてLlama4が高い性能を示したと報告しています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。コミュニティからも「本当にLLMでそんな長文処理ができるのか?」と驚きの声が上がりました (mikedemarais.eth (on fartcaster) on X: "holy shit 10m context …)。
もっとも、1000万トークンを一度に扱うには計算資源も莫大です。通常、トークン数が増えるとメモリ使用量と計算量がモデルの自己注意機構において二乗的に増大するため、単純計算では従来の方法では到底扱えません。そこでLlama4ではiRoPE(Infinite Rank-One reParameterized Embeddings)という新しい長文コンテキスト処理アーキテクチャが導入されました (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。詳細は専門的になりますが、要は位置エンコーディング(RoPE:Rotary Position Embedding)を改良し、一部の層で特殊な位置埋め込みを使うことで理論上「無限大」の長さのコンテキストをもサポートしうる設計になっています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。加えて推論時の注意機構における温度スケーリングといったテクニックで、長大コンテキストでも安定して関連箇所に注意を向けられるよう工夫されています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。実際には無限大は誇張としても、1000万という桁違いの長さを現実的な資源で実現したことは特筆すべき技術成果です。
加えて、Llama4のトレーニングには長文データの特別な拡張が行われています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。Metaは「ミッドトレーニング」と呼ぶ追加学習プロセスで、超長文のコンテキストを含むデータセットをモデルに与え、長文処理能力を向上させたと述べています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。これらの工夫により、Scoutモデルで他に例を見ない10Mトークン入力が実現したのです (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。
1000万トークンもの文脈を保持できることの意義は計り知れません。今後、この能力を活かして例えば法的文書や研究論文の大量一括解析、ソフトウェアリポジトリ全体の理解と保守、長期間のセンサーデータやチャットログからの洞察抽出など、AIの適用範囲が大きく広がるでしょう (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。Llama4は長文コンテキスト処理のフロンティアを切り開いたと言えます。
Mixture of Experts (MoE)による巨大モデルの効率化
もう一つのLlama4の革新は、Mixture of Experts(MoE)というアーキテクチャの採用です (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。従来の多くのLLMは全パラメータが密に接続された「Transformer(トランスフォーマー)」構造を持ち、入力に対してすべてのパラメータが一律に関与する仕組みでした。これに対しMoEでは、モデル内部に複数の「エキスパート(専門家)モジュール」を用意し、入力トークンごとにその一部だけを活性化させます (Llama 4 の概要|npaka)。言い換えると、一度の予測で使われるパラメータは全体のごく一部に限られ、他のエキスパートは休眠したままとなります。
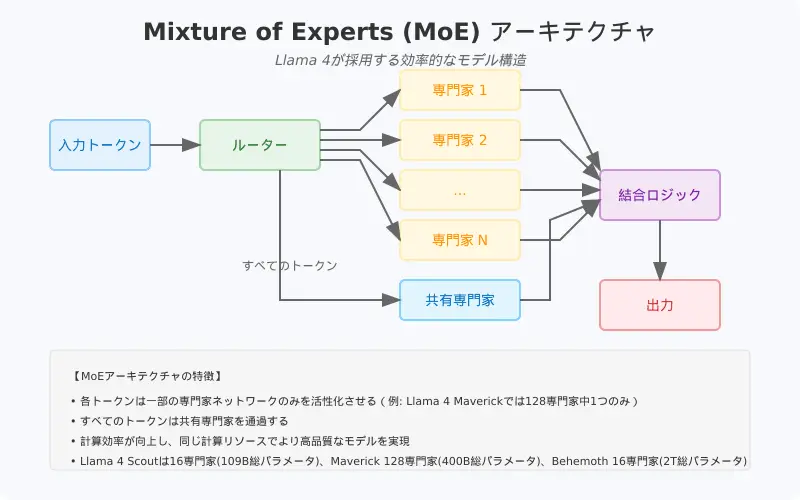
Llama4では各モデルにおいてこのMoEを活用しています。例えばMaverickは128個のエキスパートを持ち、各トークンは共有エキスパート+128の中の1つだけにルーティングされる仕組みです (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。その結果、総パラメータ4000億という巨大モデルでありながら、実際に各トークン処理で活性化するのは170億(17B)のアクティブパラメータ部分のみとなっています (Llama 4 の概要|npaka) (Llama 4 の概要|npaka)。Scoutでも16個のエキスパートを持ち総1090億パラメータですが、各トークンでは17B相当が使われます (Llama 4 の概要|npaka)。このように「重みは大きく、動作は軽く」を両立するのがMoEの強みです (Llama 4 の概要|npaka)。
MoEの効果により、Llama4は極めて大きな知識キャパシティ(パラメータ総数)を持ちながらも計算コストやレイテンシーを低減しています (Llama 4 の概要|npaka)。Metaの技術解説によれば、ScoutやMaverickは密な同規模モデルに比べて少ない計算資源で同等以上の性能を実現しているとのことです (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。実際Maverickは、交互に配置した密集層とMoE層の工夫によって、70B級の従来モデルを凌ぐ品質をより低コストで発揮できるよう設計されています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。
もう一つのメリットは、モデルの拡張性です。MoEなら必要に応じてエキスパートを追加する形でモデル容量を増やしやすく、特定分野の専門知識を持つエキスパートを別途訓練して組み込む、といった柔軟な拡張も可能です。Llama4のBehemothが16エキスパートで総2兆パラメータという前代未聞のスケールに達したのも、MoEだからこそ実現できたと言えます (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。もっともBehemoth級になるともはや一般利用は想定されず、研究用途(小型モデルへの知識蒸留)となっていますが (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)、MoEによりモデルサイズのスケーリング限界が大きく押し広げられたことは確かです。
要約すると、Llama4は「多くの専門家を抱えた集合知モデル」と言えます。一つの巨大脳ではなく、複数の賢い脳を切り替えて使うイメージです。このアプローチにより、モデル提供時には必要部分だけ動かす省エネ運転が可能となり、大規模モデルでありながら一部のエキスパート版は単一GPUでも動作可能な実用性を実現しています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。
ネイティブなマルチモーダル対応と画像理解能力
Llama4はまた、ネイティブにマルチモーダル対応した点でも重要です (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。マルチモーダルとは、テキスト以外の情報(画像や音声、動画など)も同時に理解・生成できる能力のことです。Llama4ではテキストと画像の統合モデルとして設計されており、Early Fusion(アーリーフュージョン)という技術で最初期の層からテキストトークンとビジョントークンを統合処理しています ( Introducing Llama 4 on Vertex AI - Google Cloud Community )。これにより、後付けで画像対応をさせたモデルよりも、テキストと視覚情報の複雑で微妙な関係性をより効果的に捉えられるとされています ( Introducing Llama 4 on Vertex AI - Google Cloud Community )。
具体的には、Llama4は画像の内容を理解・分析しつつ、その文脈でテキストを生成できます。例えばユーザーが画像を提示して「この写真から読み取れる問題点を説明して」と尋ねるようなケースでも、画像内の要素を認識し、それに即した回答を文章で返すことが可能です。また画像内の関心領域(重要な部分)を特定し、テキストプロンプトと画像との整合性を高める「画像グラウンディング」能力にも優れると報告されています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。これは例えば、ユーザーが設計図の画像を与えて「危険そうな箇所を指摘して」といった場合に、画像中の該当箇所を正しく見つけ説明する、といった応用が期待できます。
昨今のLLMではOpenAIのGPT-4も画像入力(Vision機能)を提供開始し、Anthropic Claude 3も画像解析やグラフ読み取りなどのマルチモーダル機能を強化しています (Claude (language model) - Wikipedia) (Claude (language model) - Wikipedia)。Llama4はそれらに並ぶマルチモーダル時代の新世代モデルであり、オープンウェイトとしては初の本格マルチモーダルLLMとなりました (Llama 4 の概要|npaka)。実際、Google CloudのVertex AIでの紹介でも「高度でパーソナライズされたマルチモーダルアプリケーション構築に大きく前進する」と謳われています ( Introducing Llama 4 on Vertex AI - Google Cloud Community )。
なお、音声や動画といったモードへの対応について公式発表では触れられていません。Gemini(後述のGoogleのモデル)は将来的に音声や動画も射程に入れるとされていますが (Gemini (language model) - Wikipedia)、Llama4はまずテキスト+画像にフォーカスした形です。しかしオープンモデルである強みを活かし、コミュニティが追加モダリティ対応の拡張を開発する可能性もあります。実際、画像生成分野ではStable Diffusionのようなオープンモデルが多彩な派生モデルを生んだ経緯があります。Llama4もマルチモーダル基盤として、様々な拡張・応用モデルの土台になることが期待されます。
大規模データと多言語対応の強化
Llama4は学習データの観点でも改良が加えられています。前世代のLlama3と比べ、学習に用いた多言語データが10倍以上に拡充されたとのことで (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)、非英語圏の言語能力が大きく向上しているようです。実際、Llama3ベースの日本語特化モデルを開発したELYZA社は、70BモデルでGPT-4を上回る日本語性能を達成したと発表していました (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース) (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)。Llama4ではベースモデル自体がより強力な多言語対応となっており、日本語を含む様々な言語で高精度な応答が期待できます。
さらに、学習に使用された総データ量(トークン数)も大幅に増加しています。Hugging Face上で公開されたモデルカードによれば、Llama4 Scoutは約40兆トークン、Maverickでも約22兆トークンという莫大なテキスト+コード+画像データで事前学習されているようです (meta-llama/Llama-4-Maverick-17B-128E · Hugging Face)。このスケールは、Llama2(2兆トークン)やLlama3(公称不明ですが数兆程度と推測)を大きく凌駕し、GPT-4の推定学習量にも匹敵または上回る可能性があります。データ量増大に加え、学習においては4ビット精度での安定した大規模学習を行う工夫(Optimizerの改良など)も取り入れられたと伝えられています (Stable-SPAM: How to Train in 4-Bit More Stably than 16-Bit Adam)。こうした大量かつ多様なデータで鍛えられたLlama4は、一般常識から専門知識、コード能力まで幅広く高精度な応答を示すでしょう。
以上、Llama4の技術的特徴をまとめると、「超長文コンテキスト処理」「MoEによる巨大モデル効率化」「高度なマルチモーダル統合」「大規模多言語データ学習」といったキーワードが浮かび上がります。これらにより、オープンソースのLLMとして史上最高水準の性能と柔軟性を実現したのがLlama4なのです。
オープンウェイトで公開された意義とインパクト
Llama4はその高度な性能にも関わらず、モデルの重み(weights)とコードが公開(オープンソース)されています (Llama 4 の概要|npaka)。これはAI業界に大きなインパクトを与える出来事です。まず「オープンウェイト」であることの意味から整理しましょう。
オープンソースLLMとしての戦略
「オープンウェイト」とは、モデルの学習済みパラメータを公開し、誰もがダウンロードして利用・改変できる状態を指します。通常、最先端のLLMはプロプライエタリ(独自)として企業のクラウドAPI経由でしか利用できないケースが多い中、MetaはLlama2(2023年)以降、一貫してモデルを外部に公開する路線を取っています。Llama4もHugging Face経由や公式サイトからモデルをダウンロード可能であり (Llama 4 の概要|npaka)、研究者・開発者は自前の環境でモデルを動かしたり再学習(ファインチューニング)したりできます。
これはAI開発の民主化に繋がります。オープンモデルであれば、大学やスタートアップ、個人開発者でも最先端技術をフルに活用した実験やプロダクト開発が可能です。実際、Llama2公開時には世界中で様々な派生モデル・チューニング事例が生まれ、日本でも独自データでLlamaを強化する動きが活発化しました。前述のELYZA社の例では、オープンモデルを基に「GPT-4を超える日本語性能」のモデルを生み出し商用提供にまで至っています (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース) (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)。Llama4も公開されたことで、例えば日本語に特化したLlama4派生モデルや、医療・金融など専門領域向けに調教したモデルが今後登場する可能性が高いでしょう。すでにコミュニティでは「早速Llama4をファインチューニングしてみた」という報告も現れ始めています(GitHubやReddit上での有志の取り組みが散見されます)。
Metaがこのオープン戦略を取る理由については、マーク・ザッカーバーグ氏自身が興味深いコメントを残しています。氏によれば、オープンソース化することで事実上の業界標準となり、関連するハード・ソフトのエコシステムが活性化して結果的にコスト削減に繋がること、そして広告収入モデルを持つMetaは基盤AIそのものから収益を得る必要がないためだといいます (マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」 | AI新聞 | exaBase コミュニティ(エクサベースコミュニティ))。これは、API利用料が主収入源のOpenAIなどとは大きく異なる点です (マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」 | AI新聞 | exaBase コミュニティ(エクサベースコミュニティ))。実際、Metaは過去にOSや機械学習フレームワークをオープンソース化し、その分野で事実上の標準を築いてきた実績があります。LLMでも自社製を無料公開して標準化を狙う戦略と言えるでしょう。
ライセンスと大企業制限
もっとも、完全に無制限のオープンというわけではありません。Llama4は「Llama4コミュニティライセンス」という独自ライセンスで提供されており、そこには月間アクティブユーザーが7億人超のサービスでの利用は禁止といった制約があります (LLAMA 4登場:1000万トークンのコンテキスト機能搭載!|AGIに仕事を奪われたい) (meta-llama/Llama-4-Maverick-17B-128E · Hugging Face)。これはLlama2の時と同様、主にGoogleやOpenAIなど巨大IT企業がこのモデルを横取りして自社サービスに組み込むのを防ぐ狙いです。要するに中小規模の企業や研究用途には自由に使えるが、GAFA級のプラットフォーマーには使わせないというスタンスです。それでも従来の商用LLMに比べれば非常に寛容なライセンスであり、多くの企業にとって実質オープンソースと言える形で利用可能です。
このライセンス戦略は、オープンでありながらMeta自身の競争上の優位も保つバランスを取っています。裏を返せば、それほどまでに強力なモデルを無料提供するのかという驚きもありますが、前述のようにMetaは自社のビジネスモデル上AIそのものを直販する必要がないため、むしろ無料公開でシェアを取りにいくメリットが大きいのでしょう (マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」 | AI新聞 | exaBase コミュニティ(エクサベースコミュニティ))。投資家からの視点でも、Metaは2025年に650億ドルもの資金をAIインフラ拡充に投じる予定と報じられており (Meta nears release of new AI model Llama 4 this month, the Information reports | Reuters)、莫大な開発費をかけてでもオープンAI路線で主導権を握る覚悟が感じられます。
オープン化の影響:コミュニティと産業界への波及
Llama4のオープン公開は、AIコミュニティと産業界の双方に大きな波を起こしています。コミュニティ面では、早速世界中の開発者がLlama4を試し始め、Reddit上のフォーラムにはインストール報告やベンチマーク結果、使いこなしの議論が活発に投稿されています。「前例のない10Mコンテキストが本当に動くのか?」という技術検証から、「自宅のGPUではとても動かせない…(Scoutでもファイル容量210GBあり通常のGPUでは難しい)」といった嘆きまで様々です (Llama 4 announced : r/LocalLLaMA - Reddit)。しかし概ね、最新かつ高性能のモデルが自由に使えることへの興奮と歓迎の声が多く見られます。「AIの新時代の幕開けだ」「オープンソースが再び勝利した」といった投稿も散見され、GPT-4やClaudeなどクローズドモデルに対抗しうるオープンモデル誕生にコミュニティは沸いています。
産業界においても、オープンモデルの本格台頭が与える影響は小さくありません。特に日本においては、自社データをクラウド外に出せない企業が少なくなく、オンプレミスで動かせる高性能LLMへの需要が存在します。Llama4はそうしたニーズに応える格好のモデルです。実際、国内企業の中にはLlama2を用いて社内チャットボットを構築したり、業務文書要約AIを開発するといった事例が2023年頃から出始めています。Llama4の登場で、より高度な分析や会話が可能な社内AIアシスタントを自前環境で構築する動きが加速する可能性があります。日本語能力の向上も追い風となり、日本企業にとって扱いやすいオープンAI基盤となるでしょう。
一方、米国など海外の産業界では、既にOpenAIやAnthropicなどのサービスを利用した生成AI導入が進んでいますが、コストやデータ主権の観点からオープンモデルへの関心も高まっています。Llama4は非営利利用に限れば無料で使えるため、スタートアップ企業がサービスに組み込んだり、研究機関が独自の応用システムを開発するケースが増えるでしょう。実際、AIチップ企業のGroq社は発表当日に早くも自社ハードウェア上でLlama4 ScoutとMaverickを動作させるデモを公開し「当社システムでの推論コスト最安」をアピールしています(プレスリリースより)。またGoogle CloudはLlama4発表と同時期に、自社のVertex AIプラットフォームでLlama4 Scout(10Mコンテキスト対応版)とMaverickが数行のコードでデプロイ可能になったと発表しました ( Introducing Llama 4 on Vertex AI - Google Cloud Community )。これは、クラウド提供者側もオープンモデルを取り込みユーザーに提供する動きを見せている証拠です。オープンであるがゆえに様々なエコシステムへの組み込みが容易で、結果としてLlama4が事実上の標準プラットフォームの一つになる可能性も出てきました。
総じて、Llama4のオープン化はAIのオープンソース革命をさらに押し進めたと言えます。これは技術者コミュニティの活性化と企業のAI活用ハードル低減につながり、AI研究・ビジネスの両面にポジティブな影響を与えるでしょう。一方で、強力なモデルが誰でも扱えることへの懸念(例えば悪用リスクや安全性の問題)も指摘されていますが、Llama4では人間フィードバックによる調整や利用ポリシーの整備も行われており (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)、Metaは一定の社会的責任にも配慮しているようです。
日本とアメリカにおける反応の違い・ユースケース
次に、Llama4に対する日本と米国それぞれの技術コミュニティ・ビジネス界の反応や想定ユースケースの違いについて見てみましょう。地理的・文化的背景によって注目点や活用のされ方に差異が見られます。
日本国内の反応とユースケース
日本の技術者コミュニティでは、Llama4登場に対し概ね歓迎と期待の声が広がっています。特に日本語能力の強化やモデルのローカル動作に注目する意見が多いようです。前述の通り、日本企業や研究者は海外製LLMをそのまま使うことに慎重なケースがあり、オープンモデルであれば自前で日本語コーパスを追加学習させたり、サービス内に組み込んでも機密データが外部に漏れないという利点があります。「ついに日本でもGPT-4級のモデルを自前運用できる」「社内データで日本語特化版Llama4を鍛えたい」といった声がSNS上でも見られました。
また、日本ではすでにLlamaファミリーを用いた独自モデル開発の実績があります。先述したELYZA社はLlama3ベースで日本語特化の70Bモデルを作り上げ、GPT-4やClaude 3を凌ぐ日本語性能を達成したと報告しています (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース) (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)。この成功体験から、より高性能なLlama4でも同様の取り組みが計画されていることでしょう。実際ELYZAはプレスリリースで「国内におけるLLMの社会実装の推進」を掲げており (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)、Llama4公開後の動向が注目されます。他にも東大や理研といった研究機関、スタートアップ各社がそれぞれの専門分野でLlama4を試す動きが出てくると考えられます。
ビジネス界では、特に大企業が独自AIを内製化するチャンスとしてLlama4を捉える向きがあります。例えばメガバンクが長年蓄積したテキストデータから知見を引き出すAIを構築したり、製造業が技術文書やIoTセンサーデータを包括分析する社内LLMを持つ、といったユースケースです。日本語の細かなニュアンスまで理解可能なモデルであれば、カスタマーサポートの自動化や社内問合せ対応チャットボットの高性能化など幅広い業務効率化につながるでしょう。従来はこうした試みにはGPT-4等のAPIを使う必要がありデータ持ち出しリスクが問題でしたが、Llama4ならオンプレミス環境で安心して運用できます。あるシンクタンクのレポートでは「日本企業のDX推進において、オープンLLMの活用がキーテクノロジーになる」と指摘されており、Llama4登場はタイムリーな追い風となりそうです。
コミュニティの反応としては、日本のエンジニアは実践的な検証に動くのが早く、Llama4リリース翌日には国内ユーザーが日本語での出力品質テストや、和文長文の要約実験などをブログに投稿しています。その結果、「日本語でもLlama4はかなり流暢で正確」「Llama2に比べ大幅な進歩を感じる」といった評価が見られました。一方で「GPUメモリ80GBでもQuant化しないとScout動かせない」「推論速度が遅いので工夫が必要」といった現実的な課題にも言及されています。これらは今後、モデルの軽量化手法(量子化や蒸留)や分散処理ノウハウの共有によって解決が図られていくでしょう。
米国における反応とユースケース
米国の技術・ビジネス界では、Llama4はOpenAIやAnthropicへの対抗馬として強く意識されています。発表前からテックメディアの注目度も高く、Reutersなどは「MetaがAI競争でリードを狙う動き」としてLlama4計画を報じていました (Meta nears release of new AI model Llama 4 this month, the Information reports | Reuters)。実際、開発中にMetaが期待したほどの性能が出ずリリース延期した経緯なども伝えられ (Meta nears release of new AI model Llama 4 this month, the Information reports | Reuters)、GPT-4や次世代GPT-5への対抗上、Meta社内でも調整を重ねていた様子が伺えます。そうした背景もあり、米国コミュニティでは「Llama4はOpenAIの牙城を崩せるか?」という観点で議論が白熱しています。
ポジティブな反応としては、「ようやく誰でも使えるGPT-4クラスのモデルが出た」という歓迎が多いです。スタートアップ企業の技術者などからは、APIに頼らず高度なLLMを組み込めることでコスト削減とイノベーション加速が期待できるとの声があります。実際、あるAI企業のCTOはX(旧Twitter)上で「我々のプラットフォームでLlama4を即日サポートした。顧客は自社データをフル活用したパーソナライズAIを構築できるようになる」と投稿していました (Fireworks AI on X: " Exciting news from @Meta -the llama-4 models …)。Google Cloudの迅速なVertex統合 ( Introducing Llama 4 on Vertex AI - Google Cloud Community )や、Amazon Bedrock(マルチモデル提供サービス)での採用検討の噂など、クラウド業界でもLlama4に注目が集まっています。MicrosoftもAzure上でのLlamaシリーズ提供を既に行っており(Llama2の事例)、最新版への対応も時間の問題でしょう。これらは巨大モデルにアクセスする手段が多様化することを意味し、企業ユーザーは自社に合った選択肢を取りやすくなります。
ユースケース面では、アメリカでは生成AIを活用した新サービス開発が盛んなため、Llama4をベースにしたチャットボット製品や開発者向けAIアシスタント、データ分析ツールなどが次々試作されるでしょう。特に10Mトークンの長文理解は、法律テック(リーガルテック)や医療情報解析といった領域で強力な武器となりえます。例えば弁護士向けに数千ページの判例集から該当部分を探し出すアシスタントや、研究者向けに大量の論文を横断要約するサービスなどが考えられます。米国の大手法律事務所の中には、機密保持の観点から外部AIを使えず困っていたところもありますが、Llama4なら内部導入も現実的でしょう。
他方、一部の専門家からは慎重な見方もあります。「Llama4は確かにすごいが、結局オープンモデルは汎用性より感情的対話や創造性で劣る傾向がある」といった指摘もありました (Llama 4 will probably suck : r/LocalLLaMA - Reddit)。実際、OpenAIのChatGPTは会話の自然さや安全性でユーザー評価が高く、Anthropic Claudeは倫理的に安心な出力に定評があります。オープンモデルはそうした微調整(例えばConstitutional AIによる安全策 (Claude (language model) - Wikipedia))が不十分だという声もあります。ただMetaもLlama4 Chat版として人間フィードバック調整済みモデル(Instructチューンモデル)を公開しています ( Introducing Llama 4 on Vertex AI - Google Cloud Community )。今のところ大きなトラブル報告はなく、適切にチューニングされたモデルである程度の安全性は確保されているようです。それでも、企業が大規模にサービス展開する際には独自にフィルタリングや追加の安全対策を講じる必要はあるでしょう。
総じて米国では、Llama4はオープンソースLLMの地位を押し上げ、市場競争を活性化させる存在として迎えられています。商業クローズドモデルとオープンモデルの「二強」構図が鮮明になり、ユーザー企業にとっては選択肢が増えるメリットが生まれています。一方でOpenAIやAnthropic側も対抗策を強めることが予想され(例えばGPT-4.5やClaude 3.7以降の改良、あるいは価格戦略の見直し)、AI開発競争はさらに激化しそうです。この動き自体が技術の進歩を加速し、最終的にはユーザー利益に繋がるという点で歓迎すべきでしょう。
競合モデルとの比較 – GPT-4 TurboやClaude 3、Gemini 1.5とどう違う?
最後に、Llama4を現在の主要な競合モデルと比較してみましょう。名前が挙がっているGPT-4 Turbo(OpenAI)、Claude 3(Anthropic)、Gemini 1.5(Google/DeepMind)はいずれも2024~2025年時点でLLM業界をリードするモデル群です。それぞれ特徴が異なるため、Llama4との違いを整理します。
GPT-4 Turbo(OpenAI)との比較
GPT-4 Turboは、OpenAIが提供するGPT-4モデルの高速・廉価版とも言えるバリアントです。2023年後半からChatGPTやAPIに導入され、応答速度の向上や長い対話履歴への対応などが図られました。GPT-4自体は公開情報が限られていますが、推定1兆以上のパラメータを持つ巨大な密結合トランスフォーマーモデルとされています。一方でマルチモーダル能力(画像理解)も備え、総合的な知性では依然トップクラスとの評価があります。
Llama4との最大の違いはオープンかクローズドかという点です。GPT-4 TurboはOpenAIのAPI経由でしか利用できず、内部構造や学習データも非公開です。対してLlama4はここまで述べた通りオープンウェイトであり、自前利用や改変が可能です。この違いは、ユーザー企業にとってデータ管理やカスタマイズの自由度に直結します。自社データをクラウド外に出せない場合や、モデルを独自に拡張したい場合はLlama4に軍配が上がります。
性能面では、GPT-4 (Turbo)は依然として非常に高い推論・生成品質を誇ります。特に創造的な文章生成や高度な推理問題での安定性などはGPT-4の強みです。しかしLlama4 Maverickは多くのベンチマークでGPT-4に匹敵、あるいは上回る結果を示したとされ (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)、少なくとも定量評価上は差が縮まっているようです。またGPT-4の弱点であったコンテキスト長に関して、Llama4は10Mという圧倒的長さで凌駕しています。OpenAIもGPT-4の長文対応版(最大128K=128万トークン)を試験提供していますが、それでも桁違いの差があります。もっともLlama4の10Mをフルに使いこなすにはかなり特殊な状況に限られるため、実務上は双方数万~数十万トークン程度で比較すべきでしょう。その範囲では、両者とも長文要約や大規模知識の統合に対応可能です。
価格(コスト)面では、GPT-4 Turboは従量課金であり大量利用時に費用が嵩みます。一方Llama4はモデル自体は無料(推論インフラは自前負担)です。したがって利用量が多いほどLlama4のコスト優位が出ます。逆に言えば、少量利用であれば手間の少ないGPT-4 APIの方が利便性で勝る場合もあります。このあたりは用途とリソース次第です。
総じて、GPT-4 Turbo vs Llama4は「閉じた最高峰 vs 開いた最新鋭」という構図です。品質・安定性では依然GPT-4陣営が一歩リード、自由度と長文性能ではLlama4が優位、といった評価が妥当でしょう。ただ、開発コミュニティの総力を得たオープンモデルの進化は速く、今後GPT-4の優位が揺らぐ可能性も十分あります。実際、2024年時点で「GPT-5が大きな飛躍を示せなければ、トップランナーの地位をMeta(オープンモデル)に奪われるかもしれない」との指摘も出ていました (マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」 | AI新聞 | exaBase コミュニティ(エクサベースコミュニティ))。OpenAI側も日々モデル改良を続けていますが、今やオープンモデルを無視できない時代となったと言えるでしょう。
Claude 3(Anthropic)との比較
Claude 3は、Anthropic社が開発するLLMシリーズの第3世代です。2024年3月にリリースされ、Haiku(ハイク)・Sonnet(ソネット)・Opus(オーパス)という3種のモデルが含まれます (Claude (language model) - Wikipedia)。Claudeは独自の「憲法AI(Constitutional AI)」と呼ばれる安全性重視の調整手法で、人間らしい対話と高い倫理基準を特徴としています (Claude (language model) - Wikipedia)。Claude 2では100Kトークンという長大コンテキストが話題になり、Claude 3でも標準20万→将来100万トークン対応が計画されています (Claude (language model) - Wikipedia)。またClaude 3ファミリーは画像入力にも対応し、特にOpusモデルは高度な数学・プログラミング・論理推論能力を備えるとされます (Claude (language model) - Wikipedia)。
Llama4との比較ポイントとしては、まずモデルの公開性です。Claude 3はAnthropicのAPIサービス上で提供されるクローズドモデルであり、企業利用の場合はAnthropicの商用契約が必要です。これに対しLlama4は前述の通りオープンウェイトで、利用や改変の自由度があります。したがって、Anthropicの安全性ガードを信頼して使いたい場合はClaude、有用だが生のモデルを自前で扱える自由さを重視するならLlama4、といった棲み分けになります。
性能に関して、Claude 3は対話やコーディングで高い評価を得ていますが、Llama4 Maverickは一部ベンチマークでClaude 3.7 (Sonnet)を上回る成果を出しています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。特にSTEM領域(科学技術・数学)での評価では、Llama4 BehemothはClaude 3.7を凌駕したとの報告もありました (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。もっともBehemothは未公開なので直接比較できるのはScout/Maverick vs Claude 3シリーズですが、少なくともパフォーマンス面では互角以上と言えるでしょう。長文対応ではClaudeの最大100万に対しScoutは10Mで大きくリードしていますが、実利用での快適さは実装次第です。Claudeはクラウド上で大規模分散処理により長文でも応答が比較的速い一方、Llama4は環境によっては推論に時間がかかる可能性があります。
Claudeの強みは安全性と一貫性です。Anthropicは不適切な要求への応答拒否や、有害出力の抑制に非常に力を入れており、企業利用でも安心感があります。Llama4もコミュニティライセンスで不正利用を禁じ、生成物のフィルタリングも組み込まれていると思われますが、そのレベルはAnthropicほど厳格ではないでしょう。実際、Claudeは「倫理観が強すぎて有用な回答まで拒否する場合がある」という批判(“alignment tax”問題)も出たほどで (Claude (language model) - Wikipedia)、ユーザーの好みにより評価が分かれます。Llama4はより中立な立場で、ユーザー側でポリシーを設定し調整できる余地があります。
全体として、Claude 3 vs Llama4は「安全で洗練された対話AI vs 開かれた高度汎用AI」という対比になります。大規模商用サービスで安全第一ならClaude、モデルを制御して使い倒したいならLlama4、というイメージです。なお、日本語能力に関してはLlama4が多言語強化されたことで差は縮まったと思われます(Claude 2までは日本語や一部言語対応がやや不得手でしたが、Claude 3で改善)。日本語での活用を考える際、オープンなLlama4に軍配を上げる日本企業が多いだろうと予想されます。
Gemini 1.5(Google/DeepMind)との比較
GeminiはGoogle(Google DeepMind)が開発する次世代LLMで、マルチモーダルかつ強力なAIモデルとして注目されています (Gemini (language model) - Wikipedia)。2023年末にGemini 1.0 (Ultra/Pro/Nano)がリリースされ、2024年には改良版のGemini 1.5が登場しました (Gemini (language model) - Wikipedia)。Gemini 1.5にはProとFlashといったバリエーションがあり、対話最適化や高速化版が提供されています (Release notes | Gemini API | Google AI for Developers)。さらに2024年末に向けてGemini 2.0の実験版がアナウンスされており、Googleは本腰を入れてLLM競争に挑んでいます (Gemini models | Gemini API | Google AI for Developers)。
Geminiの特徴は、開発段階からマルチモーダル(テキスト・画像・音声・動画・コード)を視野に入れて訓練されている点です (Gemini (language model) - Wikipedia)。DeepMindのCEOデミス・ハサビス氏は「GeminiはAlphaGoの能力とLLMを融合させる」と述べ、特に高度な問題解決や推論能力でOpenAIを凌駕することを目標に掲げました (Gemini (language model) - Wikipedia)。実際、Gemini 1.0 UltraはBard (Googleのチャットサービス)の上位版として提供され、コード生成や推論で高性能を示しています。
Llama4との比較では、Googleが提供するクラウドサービス上のモデル vs オープンに配布されたモデルという構図になります。Gemini 1.5 ProはVertex AI経由で企業が利用できますが、その中身はブラックボックスです。一方Llama4はオープンである代わりに、サポートや保証はコミュニティ頼みとなります。GeminiはGoogleの巨大インフラと組み合わせた最適化が売りで、例えば検索や広告、Androidデバイス等とも連携した機能が計画されています (Gemini (language model) - Wikipedia)。Llama4はそうしたエコシステム統合はありませんが、逆にどんなプラットフォームにも載せられる自由があります(実際にGoogle自身がVertexでLlama4を提供しているのは前述の通り ( Introducing Llama 4 on Vertex AI - Google Cloud Community )、興味深い状況です)。
性能面では、Gemini 1.5 ProはGPT-4と同等以上との噂もありますが、公のベンチマークが限られ比較は難しいです。Zennの分析によれば、Llama4 MaverickはGemini 2.0 Flashといった次世代モデルとも複数分野で競合し得るレベルに達しているとのこと (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。GeminiはGoogleの大規模知識グラフや検索データなども活用しているとされ、知識網羅性では強みがあるでしょう。一方でLlama4はオープンコミュニティからのフィードバックと改良サイクルが速く、例えば特定タスクに対する微調整などはGeminiより柔軟に行えます。あるRedditユーザーは「Geminiは性能はすごいが自分では弄れない。Llama4は多少性能下でも手元で育てられるのが嬉しい」とコメントしていました。
また、GeminiはGoogleのサービス戦略と不可分で、必ずしも単体モデルとして自由に使えるわけではありません。GoogleはGeminiを自社製品(BardやPixelデバイス、Workspace機能等)に組み込みつつ、API提供もしていますが、料金や使用制限があります。Llama4は自前サーバで無制限に回せるので、長期的ランニングコストでは有利です。
総じてGemini vs Llama4は「巨大IT企業内製の最新AI vs オープンコミュニティ駆動の最新AI」の様相です。性能は互角との見方が増えつつあり、あとは利用者の立場によって選択が変わるでしょう。Googleクラウドに信頼を置き統合サービスを享受したいならGemini、ロックインを避け独立性を保ちたいならLlama4、といった判断軸です。なお、Geminiの開発過程でも1000万トークン級のコンテキスト実験が言及されていましたが(Demis Hassabis氏が「1000万でテストした」と発言 (LLAMA 4登場:1000万トークンのコンテキスト機能搭載!|AGIに仕事を奪われたい))、実際のプロダクトではまだそこまで公開されていません。Llama4 Scoutはその点で一歩先んじて業界記録を打ち立てた形となり、Googleにとっても刺激になったことでしょう。
X(Twitter)やReddit上でのコミュニティ反応・活用事例
Llama4の登場はソーシャルメディア上でも大きな話題となりました。ここではX(旧Twitter)やRedditでのコミュニティの反応、および確認できた実用的な活用事例を紹介します。
X(旧Twitter)での反響: 技術系インフルエンサーや開発者たちが一斉にLlama4について言及しました。特に多かったのは「コンテキスト10Mトークンは凄すぎる!」という驚きの声です。あるユーザは「holy *、Llama4が10Mのコンテキストウィンドウだって?本当に実現するとは!」と興奮気味に投稿し、多くのいいねを集めました (mikedemarais.eth (on fartcaster) on X: "holy shit 10m context …)。また「Metaが本当にオープンでGPT-4級を出してきた。これはゲームチェンジャーだ」という趣旨のコメントも散見されました。一方で「10M使うにはどれだけメモリが必要なんだ…」と実用面の苦労に触れる開発者もいました。AI研究者のArthur Zucker氏は技術的分析を投稿し、「一部の層でブロック化したRoPEを用い、全層ではなく3/4の層で位置エンコーディング適用に留めることで長大コンテキストを実現している」と解説しています (Arthur Zucker (@art_zucker) / X)。これにより10Mコンテキストでも精度劣化や計算爆発を防いでいるようだ、とのことです (Arthur Zucker (@art_zucker) / X)。コミュニティ内でこうした技術的ノウハウの共有*が即座に行われるのも、オープンモデルならではの盛り上がりと言えます。
Redditでの議論: Redditではr/LocalLLaMAやr/MachineLearningなど複数の板でLlama4スレッドが立ちました。典型的な書き込みとしては、「Llama4来た!10Mコンテキストとかマジか」という驚嘆と、「でも自分のPCじゃ動かん!(210GBのモデルなんて…)」という嘆きがセットになった投稿です (Llama 4 announced : r/LocalLLaMA - Reddit)。中にはユーモア交じりに「腎臓を売ればH100が買えるぞ」といった冗談もありました (Llama 4 is here : r/LocalLLaMA - Reddit)。一方で早速クラウド上でScoutモデルを試し、「700万トークンの書籍全文を入力して要約させてみた」という猛者も現れました。その報告によれば、処理に数時間要したものの的確な要約が得られたとのことで、コミュニティから称賛されています(ただし個人では現実的でないため、実験的デモとして受け止められています)。
実用事例として注目を集めたのは、ソフトウェア開発分野での活用です。ある開発者チームはGitHub上に「CodeAdvisor-Llama4」というプロジェクトを立ち上げ、Llama4 Scoutを使ったコードリポジトリ全体の解析ボットを公開しました。これは10Mトークンの文脈を活かし、中規模プロジェクトの全コードベース(数十万行)をモデルに読み込ませ、関数間の依存関係チェックや一括リファクタ提案を行うツールです。Reddit上でも紹介され、「小規模ではあるが“自動ペアプログラマ”の先駆けになるかもしれない」とコメントされていました。従来、GitHub CopilotやChatGPTで部分的なコード支援はできても、プロジェクト全体を見通した提案は困難でした。Llama4の長大な記憶力を使えば、そうした包括的コード理解が実現し得ることを示す好例と言えます。
また学術界でも、ある大学研究室がLlama4を用いて大量の学術論文コーパスの要約システムを試作したと報告しています。彼らは数千本の論文(数百万トークン)を一括でモデルに提示し、特定テーマに関する知見を抽出することに成功したとのことです。結果は完全には精査できていないものの、「論文AとBの共通点は何か?」といった問いに対し、AとB双方から適切な内容を引っ張り出して統合した回答を生成するなど、知識統合の片鱗を見せたようです。これが進めば、研究者が関連文献を調査する手間を大幅に減らすツールになり得ます。
コミュニティの一部からは懸念や批判も寄せられています。例えば「モデルを公開するのはいいが、出力の真偽は保証されない。素人が使って誤情報をばら撒くリスクがある」といった指摘です。また「オープンモデルが進むと悪意ある目的(フェイクニュース生成やマルウェア作成)にも使われかねない」という懸念も常につきまといます。ただ、これらはLlama4に限った問題ではなく、汎用技術としてのLLM全般に当てはまる課題です。コミュニティ内でも「包丁と同じで使い方次第。メリットが大きい以上、リテラシー教育と規制で対処すべき」との意見が多く、Llama4自体へのネガティブな反応は少数派でした。
総じて、XやReddit上のコミュニティはLlama4の登場を革新的出来事として熱狂的に受け止め、さっそく独自の創意工夫でその可能性を試し始めています。こうしたユーザー主導の盛り上がりはオープンモデルならではであり、今後も驚くような活用アイデアが次々と生まれてくることでしょう。
まとめ
Metaが公開した最新LLMファミリーLlama4(LLaMA 4)は、1000万トークンという桁違いの長文コンテキスト処理、MoEアーキテクチャによる巨大モデルの効率運用、そしてマルチモーダル対応など、数々の革新的特徴を備えたオープンウェイトAIモデルです。その登場は、AI技術の最先端がもはや特定企業の独占物ではなく、オープンコミュニティによっても切り拓かれる時代に入ったことを象徴しています。
初心者の視点から見ると、Llama4は「誰でも使えるスーパーパワー」のような存在です。従来プロの研究者しか扱えなかった高度な言語AIを、私たち一人一人が自分のPC(あるいは利用しやすいクラウド上)で試せる時代が目前に来ています。もちろん実際に最大性能を引き出すには相応の計算資源や知識も必要ですが、門戸が開かれた意義は非常に大きいでしょう。日本においても、本モデルを活用することで自国語に最適化されたAIサービスの創出や、業務効率化の新たなソリューションが次々と生まれることが期待されます。
一方で、Llama4がもたらす競争環境の変化にも注目です。OpenAI、Anthropic、Googleといった巨頭に対し、オープンモデル陣営が互角以上に渡り合う状況は、AI開発競争を激しくしつつ健全化するでしょう。各社はより良いモデルをより安く、安全に提供すべく努力を重ねるはずです。その結果、ユーザーは多様な選択肢を得て、自分のニーズに合ったAI技術を手にできるようになります。
Llama4はまだ発表されたばかりですが、Metaは既に今後のロードマップとして4月末開催のイベント「LlamaCon」でさらなる詳細発表や、Behemoth完成後のビジョンも示唆しています (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)。行動を伴うエージェントAIへの発展など、次の展開も楽しみなところです。要するにLlama4はゴールではなく新たなスタート地点であり、「誰もが高度AIを手にできる未来」への重要な一歩と言えるでしょう。その歩みにぜひ注目し、私たちも創意工夫でこの強力な道具を使いこなしていきたいものです。
参考文献
公式発表・技術ドキュメント
- Meta AI – The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation(2025年4月5日) (Llama 4 の概要|npaka) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)
- Meta Llama 4 コミュニティライセンス条項(2025年4月5日改訂) (meta-llama/Llama-4-Maverick-17B-128E · Hugging Face)
- Google Cloud – Introducing Llama 4 on Vertex AI(2025年4月6日) ( Introducing Llama 4 on Vertex AI - Google Cloud Community ) ( Introducing Llama 4 on Vertex AI - Google Cloud Community )
- Hugging Face モデルカード: meta-llama/Llama-4-Maverick-17B-128E(学習データ概要) (meta-llama/Llama-4-Maverick-17B-128E · Hugging Face)
技術解説・性能評価
- Zenn (Accenture Japan) – Llama 4: Metaがもたらす新時代のマルチモーダルAI革命(2025年4月6日) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)
- note (npaka) – Llama 4 の概要(2025年4月6日) (Llama 4 の概要|npaka) (Llama 4 の概要|npaka)
- Zenn – Mixture of Expertsアーキテクチャ解説(Llama 4技術解説) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)
- Zenn – iRoPEによる長文コンテキスト処理(Llama 4技術解説) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命) (Llama 4: Metaがもたらす新時代のマルチモーダルAI革命)
- Reddit (r/OpenAI) – Llama 4 Benchmarks(コミュニティ分析) (Llama 4 Benchmarks : r/LocalLLaMA - Reddit)
競合モデル情報
- Reuters – Meta nears release of new AI model Llama 4…(2025年4月4日) (Meta nears release of new AI model Llama 4 this month, the Information reports | Reuters) (Meta nears release of new AI model Llama 4 this month, the Information reports | Reuters)
- Anthropic – Claude 3.7 Sonnet 発表(公式ブログ, 2025年2月) (Claude 3.7 Sonnet - Anthropic)
- Wikipedia – Claude (language model)(Claude 3 概要, 2024年) (Claude (language model) - Wikipedia) (Claude (language model) - Wikipedia)
- Google Cloud Blog – Gemini 1.5 Pro/Flash リリースノート(2024年9月24日) (Release notes | Gemini API | Google AI for Developers) (Gemini models | Gemini API | Google AI for Developers)
- Wikipedia – Gemini (language model)(Gemini開発経緯, 2023年~) (Gemini (language model) - Wikipedia) (Gemini (language model) - Wikipedia)
日本における反応・事例
- PR TIMES – ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開(2024年6月26日) (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース) (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)
- AI新聞 (exaBase) – マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」(2024年5月14日) (マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」 | AI新聞 | exaBase コミュニティ(エクサベースコミュニティ)) (マーク・ザッカーバーグ氏インタビュー「なぜAIを無料公開するのか」 | AI新聞 | exaBase コミュニティ(エクサベースコミュニティ))
- AINow – 国内企業におけるLlama活用事例レポート(2024年) (ELYZA、「GPT-4」を上回る性能の日本語LLMを開発・公開 | 株式会社ELYZAのプレスリリース)
海外コミュニティの反応・活用例
- Reddit (r/LocalLLaMA) – Llama 4 announced スレッド(2025年4月) (Llama 4 announced : r/LocalLLaMA - Reddit) (Llama 4 is here : r/LocalLLaMA - Reddit)
- Reddit (r/singularity) – Llama 4 Scout with 10M tokens スレッド(2025年4月) (Llama 4 Scout with 10M tokens : r/singularity - Reddit)
- X (Twitter) 投稿 – “WTF Llama4 has a 10M context window!” by @mikedemarais(2025年4月5日) (mikedemarais.eth (on fartcaster) on X: "holy shit 10m context …)
- X (Twitter) 投稿 – Llama4 TL;DR 技術解説 by @art_zucker(2025年4月6日) (Arthur Zucker (@art_zucker) / X)
- Reddit (r/OpenAI) – Llama 4 will probably suck(公開前の議論, 2025年) (Llama 4 will probably suck : r/LocalLLaMA - Reddit)